Автоматизированная система сбора контента и создания Базы Знаний н
AI и машинное обучение 60 000 UAH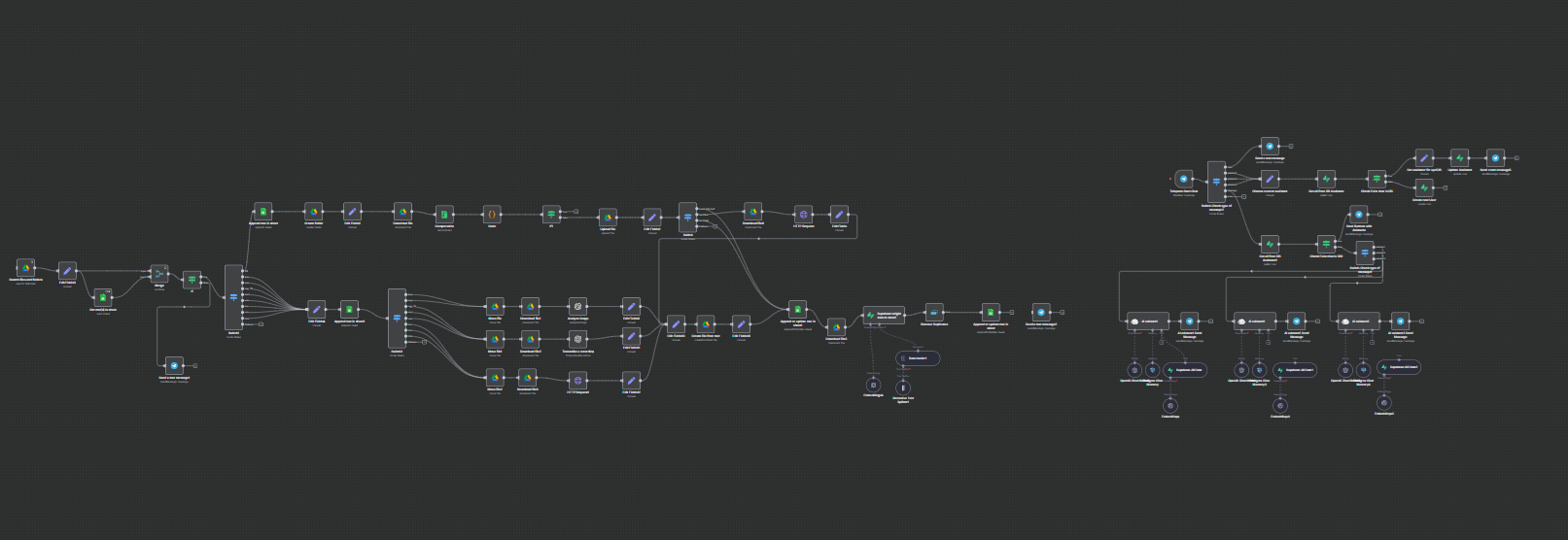
Проект: Автоматизированная система сбора контента и создания Базы Знаний на основе ИИ
Основные функции и техническая реализация
1. Конвейер входных данных и фильтрации:
Триггер регулярно сканирует указанную папку на Google Drive на наличие новых файлов.
Надежный механизм дедупликации проверяет "реестр" в Google Sheets, чтобы гарантировать, что файлы обрабатываются только один раз. Новые файлы сразу логируются со статусом pending (в ожидании).
2. Модульная архитектура обработки ("Маршрутизатор"):
Центральная нода Switch действует как маршрутизатор, направляя файлы к различным веткам обработки на основе их MIME-типа. Эта архитектура легко масштабируема, что позволяет добавлять новые типы файлов с минимальными изменениями.
Ветка для ZIP-архивов:
Архивы распаковываются, а их содержимое повторно направляется на начало рабочего процесса для индивидуальной обработки. Оригинальный архив немедленно логируется и перемещается, чтобы избежать повторной обработки.
Ветка для документов (.doc, .docx, .html):
Файлы отправляются на специально созданный микросервис на Node.js для парсинга. Сервис использует специализированные библиотеки (docx-parser, textract, node-html-parser) для извлечения чистого текста.
Ветка для изображений (.jpeg, .png):
Изображения загружаются и отправляются в OpenAI Vision API (gpt-4o) с детальным промптом для выполнения оптического распознавания символов (OCR) и описания визуальных элементов, возвращая структурированный текст.
Ветка для аудио (.mp3, .wav, .ogg):
Аудиофайлы отправляются в OpenAI Whisper API для точной транскрипции речи в текст.
3. Стандартизация и хранение контента:
Результат каждой ветки обработки (извлеченный текст) стандартизируется в единый формат.
Создается и сохраняется новый текстовый файл, содержащий извлеченный контент, на Google Drive для архивирования.
Далее текст передается в конвейер на базе LangChain:
Разбиение текста: Большие документы разбиваются на меньшие, частично пересекающиеся части (чанки), чтобы соответствовать ограничениям контекстного окна моделей для эмбеддингов.
Создание эмбеддингов: Каждая часть текста преобразуется в числовой вектор с помощью моделей эмбеддингов от OpenAI.
Хранение в векторной базе: Эмбеддинги и связанные с ними метаданные (ID исходного файла, имя, ссылка на источник) хранятся в базе данных Supabase с использованием расширения pgvector.
4. Управление состоянием и уведомления:
После успешной обработки и сохранения в векторную базу соответствующая запись в реестре Google Sheets обновляется до статуса completed.
Оригинальный исходный файл перемещается из входной папки в архивный каталог "Processed" на Google Drive.
Уведомление в реальном времени, содержащее детали обработанного файла и ссылку на оригинал, отправляется в определенный чат Telegram.
5. Интеграция с AI-ассистентом (компонент для пользователя):
Система включает многоагентного Telegram-бота, где пользователи могут выбирать различных "ассистентов".
Каждый ассистент настроен с уникальным системным промптом и может быть подключен к собственной выделенной векторной базе или источнику знаний.
История чата для каждого пользователя и ассистента хранится в базе данных Postgres, что обеспечивает контекстные, непрерывные разговоры.
Используемые технологии
Оркестрация: n8n (self-hosted)
Источники данных и хранение: Google Drive, Google Sheets
Векторная база данных: Supabase (с Postgres и pgvector)
Искусственный интеллект и Эмбеддинги: OpenAI (GPT-4o для Vision, Whisper для Audio, модели для Text Embedding), LangChain.js (в рамках n8n)
Кастомный парсинг: Node.js, Express.js, docx-parser, textract, node-html-parser
Интерфейс пользователя: Telegram Bot API
Основные функции и техническая реализация
1. Конвейер входных данных и фильтрации:
Триггер регулярно сканирует указанную папку на Google Drive на наличие новых файлов.
Надежный механизм дедупликации проверяет "реестр" в Google Sheets, чтобы гарантировать, что файлы обрабатываются только один раз. Новые файлы сразу логируются со статусом pending (в ожидании).
2. Модульная архитектура обработки ("Маршрутизатор"):
Центральная нода Switch действует как маршрутизатор, направляя файлы к различным веткам обработки на основе их MIME-типа. Эта архитектура легко масштабируема, что позволяет добавлять новые типы файлов с минимальными изменениями.
Ветка для ZIP-архивов:
Архивы распаковываются, а их содержимое повторно направляется на начало рабочего процесса для индивидуальной обработки. Оригинальный архив немедленно логируется и перемещается, чтобы избежать повторной обработки.
Ветка для документов (.doc, .docx, .html):
Файлы отправляются на специально созданный микросервис на Node.js для парсинга. Сервис использует специализированные библиотеки (docx-parser, textract, node-html-parser) для извлечения чистого текста.
Ветка для изображений (.jpeg, .png):
Изображения загружаются и отправляются в OpenAI Vision API (gpt-4o) с детальным промптом для выполнения оптического распознавания символов (OCR) и описания визуальных элементов, возвращая структурированный текст.
Ветка для аудио (.mp3, .wav, .ogg):
Аудиофайлы отправляются в OpenAI Whisper API для точной транскрипции речи в текст.
3. Стандартизация и хранение контента:
Результат каждой ветки обработки (извлеченный текст) стандартизируется в единый формат.
Создается и сохраняется новый текстовый файл, содержащий извлеченный контент, на Google Drive для архивирования.
Далее текст передается в конвейер на базе LangChain:
Разбиение текста: Большие документы разбиваются на меньшие, частично пересекающиеся части (чанки), чтобы соответствовать ограничениям контекстного окна моделей для эмбеддингов.
Создание эмбеддингов: Каждая часть текста преобразуется в числовой вектор с помощью моделей эмбеддингов от OpenAI.
Хранение в векторной базе: Эмбеддинги и связанные с ними метаданные (ID исходного файла, имя, ссылка на источник) хранятся в базе данных Supabase с использованием расширения pgvector.
4. Управление состоянием и уведомления:
После успешной обработки и сохранения в векторную базу соответствующая запись в реестре Google Sheets обновляется до статуса completed.
Оригинальный исходный файл перемещается из входной папки в архивный каталог "Processed" на Google Drive.
Уведомление в реальном времени, содержащее детали обработанного файла и ссылку на оригинал, отправляется в определенный чат Telegram.
5. Интеграция с AI-ассистентом (компонент для пользователя):
Система включает многоагентного Telegram-бота, где пользователи могут выбирать различных "ассистентов".
Каждый ассистент настроен с уникальным системным промптом и может быть подключен к собственной выделенной векторной базе или источнику знаний.
История чата для каждого пользователя и ассистента хранится в базе данных Postgres, что обеспечивает контекстные, непрерывные разговоры.
Используемые технологии
Оркестрация: n8n (self-hosted)
Источники данных и хранение: Google Drive, Google Sheets
Векторная база данных: Supabase (с Postgres и pgvector)
Искусственный интеллект и Эмбеддинги: OpenAI (GPT-4o для Vision, Whisper для Audio, модели для Text Embedding), LangChain.js (в рамках n8n)
Кастомный парсинг: Node.js, Express.js, docx-parser, textract, node-html-parser
Интерфейс пользователя: Telegram Bot API