#Kubernetes #Security #Automation #GPT #DataAnalysis #DevSecOps #AI #PromptEngineering #BigData
Этот проект призван автоматизировать анализ больших JSON-отчетов безопасности Kubernetes (#Polaris, #Trivy, #Kubescape). Заказчица нуждалась в удобном инструменте для преобразования сырых данных в полезный отчет с ключевыми выводами, лучшими практиками, рекомендациями и оценкой зрелости. Результат должен быть готов к презентациям для технической и нетехнической аудитории.
Задачи и Вызовы
• Обработка огромных объемов данных (#BigData) без превышения контекста GPT.
• Отдельные #Prompts для каждого инструмента для повышения точности (#PromptEngineering).
• Сбалансировать затраты: начальный уровень обобщения должен быть дешевле (#gpt-3.5-turbo), финальный — глубже (#o1-mini), чтобы сохранить качество (#CostOptimization).
• Иерархический подход (#HierarchicalAnalysis) и кэширование (#Caching) для ускорения повторных запусков.
Решения
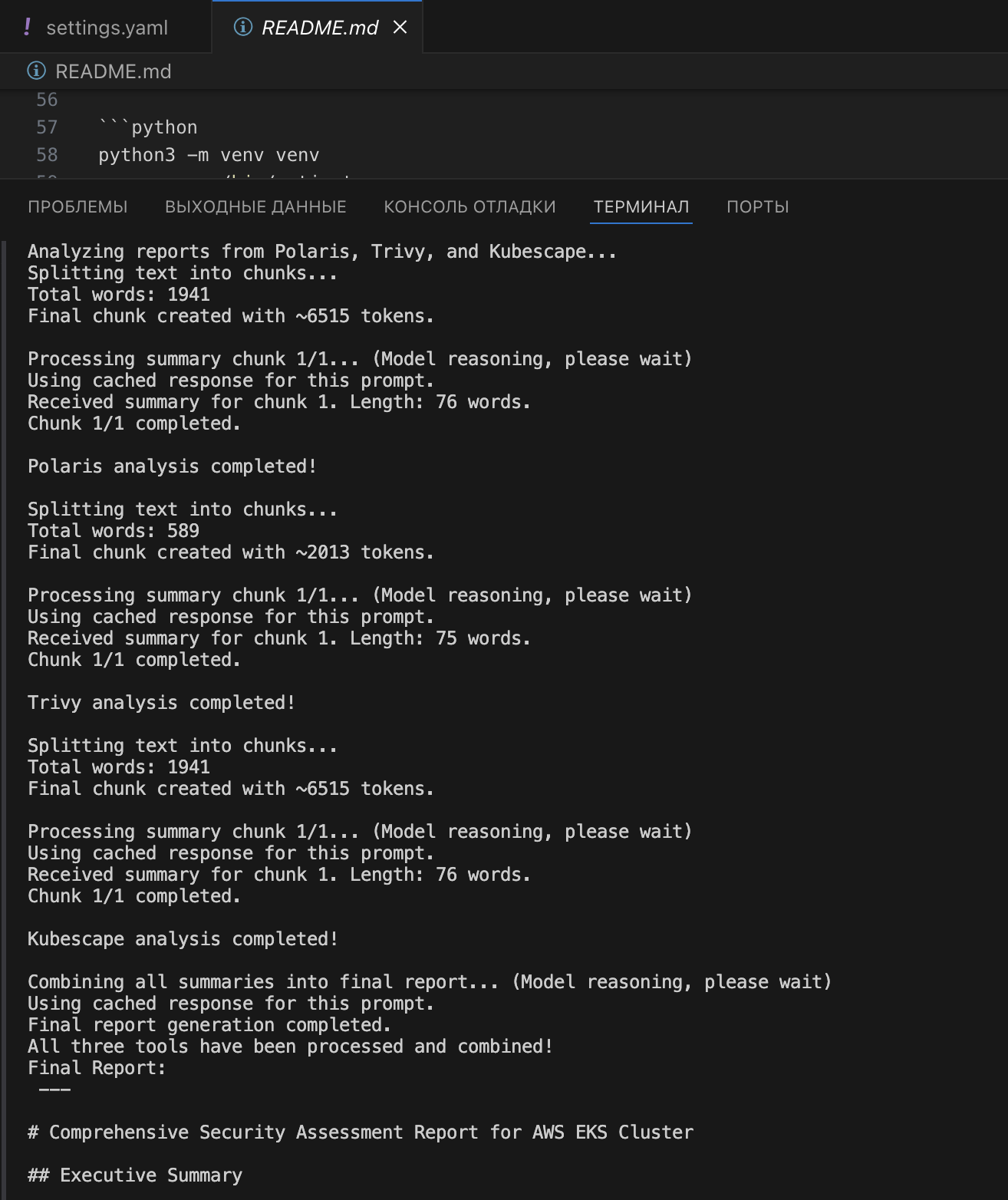
1. Иерархический анализ: Данные разбиваются на чанки, обобщаются gpt-3.5-turbo, затем итоги трех инструментов объединяет o1-mini.
2. Отдельные промты: Каждый инструмент имеет свой промт, адаптированный под формат данных (#Polaris, #Trivy, #Kubescape).
3. Кэширование: Уменьшает время и стоимость повторных запусков.
4. Модульность: Код разделен на модули, что упростило будущие обновления (#Modularity).
Результаты
• Полная автоматизация анализа (#Automation): Огромные файлы обрабатываются без ручного труда.
• Оптимизация затрат (#CostEffective): Начальные обобщения gpt-3.5-turbo дешевы, кэширование быстрое.
• Качественный финальный отчет (#QualityOutput): Благодаря гибридному подходу и промтам отчет точный, релевантный и готов для презентаций.
Вывод
Этот кейс демонстрирует эффективность #AI, #LLM и #PromptEngineering в задачах #DevSecOps и #DataAnalysis. Сочетание различных моделей, иерархический анализ, модульная архитектура и четкая документация сделали решение гибким, масштабируемым и экономичным.
Этот проект призван автоматизировать анализ больших JSON-отчетов безопасности Kubernetes (#Polaris, #Trivy, #Kubescape). Заказчица нуждалась в удобном инструменте для преобразования сырых данных в полезный отчет с ключевыми выводами, лучшими практиками, рекомендациями и оценкой зрелости. Результат должен быть готов к презентациям для технической и нетехнической аудитории.
Задачи и Вызовы
• Обработка огромных объемов данных (#BigData) без превышения контекста GPT.
• Отдельные #Prompts для каждого инструмента для повышения точности (#PromptEngineering).
• Сбалансировать затраты: начальный уровень обобщения должен быть дешевле (#gpt-3.5-turbo), финальный — глубже (#o1-mini), чтобы сохранить качество (#CostOptimization).
• Иерархический подход (#HierarchicalAnalysis) и кэширование (#Caching) для ускорения повторных запусков.
Решения
1. Иерархический анализ: Данные разбиваются на чанки, обобщаются gpt-3.5-turbo, затем итоги трех инструментов объединяет o1-mini.
2. Отдельные промты: Каждый инструмент имеет свой промт, адаптированный под формат данных (#Polaris, #Trivy, #Kubescape).
3. Кэширование: Уменьшает время и стоимость повторных запусков.
4. Модульность: Код разделен на модули, что упростило будущие обновления (#Modularity).
Результаты
• Полная автоматизация анализа (#Automation): Огромные файлы обрабатываются без ручного труда.
• Оптимизация затрат (#CostEffective): Начальные обобщения gpt-3.5-turbo дешевы, кэширование быстрое.
• Качественный финальный отчет (#QualityOutput): Благодаря гибридному подходу и промтам отчет точный, релевантный и готов для презентаций.
Вывод
Этот кейс демонстрирует эффективность #AI, #LLM и #PromptEngineering в задачах #DevSecOps и #DataAnalysis. Сочетание различных моделей, иерархический анализ, модульная архитектура и четкая документация сделали решение гибким, масштабируемым и экономичным.