Мутация и миграция контента с использованием ИИ
AI и машинное обучение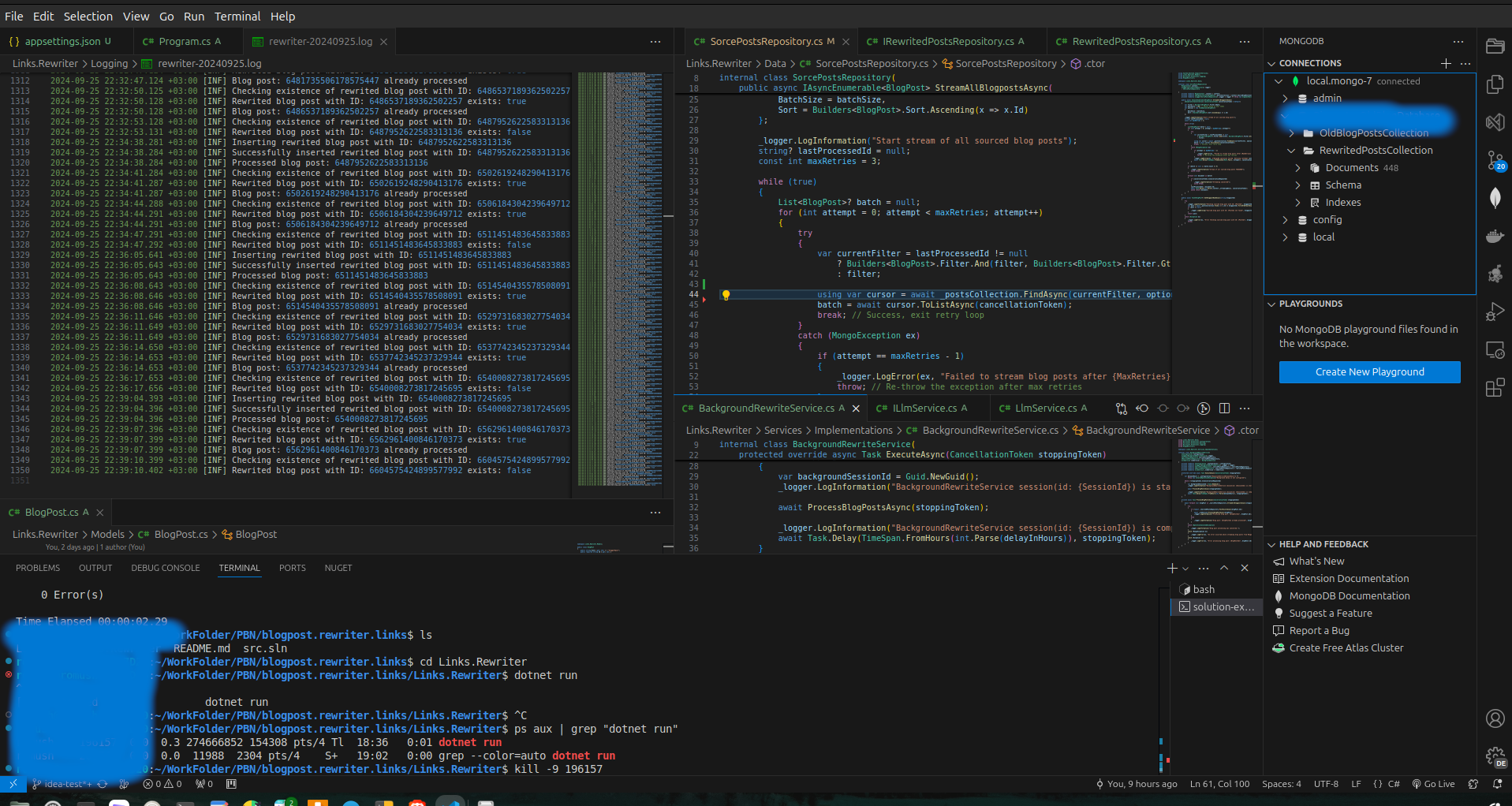
Представьте себе: перед вами стоит задача перенести десятки блогов из CMS-1 в новую систему CMS-2. Но это не просто копирование — контент нужно еще адаптировать, изменить под требования новой платформы, и все это с помощью искусственного интеллекта.
Основным условием клиента была полная конфиденциальность данных, поэтому я разработал решение, которое обошлось без сторонних сервисов.
Первая часть проекта заключалась в разработке микросервиса, который через API взаимодействовал с CMS-1, извлекая все имеющиеся посты вместе с их первоначальной структурой — заголовки, текст, изображения, метаданные. Этот контент хранился в MongoDB как документно-ориентированная база, что позволило сохранить оригинальные данные без потери структуры.
Следующий шаг — разработка микросервиса, который подключался к базе данных MongoDB, брал сохраненные посты и передавал их на обработку локальной модели Llama3.1. Эта модель выполняла мутацию контента: переписывала тексты, изменяла форматирование и адаптировала его в соответствии с требованиями клиента и спецификациями CMS-2. Результаты этой обработки также сохранялись в новой коллекции MongoDB.
Третий этап — микросервис для переноса обработанного контента в CMS-2. Он извлекал измененные данные из базы, трансформировал их в формат, совместимый с CMS-2, и передавал с помощью API. Такой подход позволил сохранить целостность контента и без проблем интегрировать его в новую систему.
Процесс занял примерно 111 часов — да, это дольше, чем использование публичных ИИ моделей, но благодаря локальной модели мы полностью сохранили приватность данных.
Основные характеристики проекта:
- 15 миллионов токенов инференса
- Скорость обработки: 35-50 токенов в секунду
- Стек: C#, .Net Core, MongoDB, Llama3.1
#dot.net #Llama3.1 #ПриватностьДанных #Микросервисы #mongodb
Основным условием клиента была полная конфиденциальность данных, поэтому я разработал решение, которое обошлось без сторонних сервисов.
Первая часть проекта заключалась в разработке микросервиса, который через API взаимодействовал с CMS-1, извлекая все имеющиеся посты вместе с их первоначальной структурой — заголовки, текст, изображения, метаданные. Этот контент хранился в MongoDB как документно-ориентированная база, что позволило сохранить оригинальные данные без потери структуры.
Следующий шаг — разработка микросервиса, который подключался к базе данных MongoDB, брал сохраненные посты и передавал их на обработку локальной модели Llama3.1. Эта модель выполняла мутацию контента: переписывала тексты, изменяла форматирование и адаптировала его в соответствии с требованиями клиента и спецификациями CMS-2. Результаты этой обработки также сохранялись в новой коллекции MongoDB.
Третий этап — микросервис для переноса обработанного контента в CMS-2. Он извлекал измененные данные из базы, трансформировал их в формат, совместимый с CMS-2, и передавал с помощью API. Такой подход позволил сохранить целостность контента и без проблем интегрировать его в новую систему.
Процесс занял примерно 111 часов — да, это дольше, чем использование публичных ИИ моделей, но благодаря локальной модели мы полностью сохранили приватность данных.
Основные характеристики проекта:
- 15 миллионов токенов инференса
- Скорость обработки: 35-50 токенов в секунду
- Стек: C#, .Net Core, MongoDB, Llama3.1
#dot.net #Llama3.1 #ПриватностьДанных #Микросервисы #mongodb