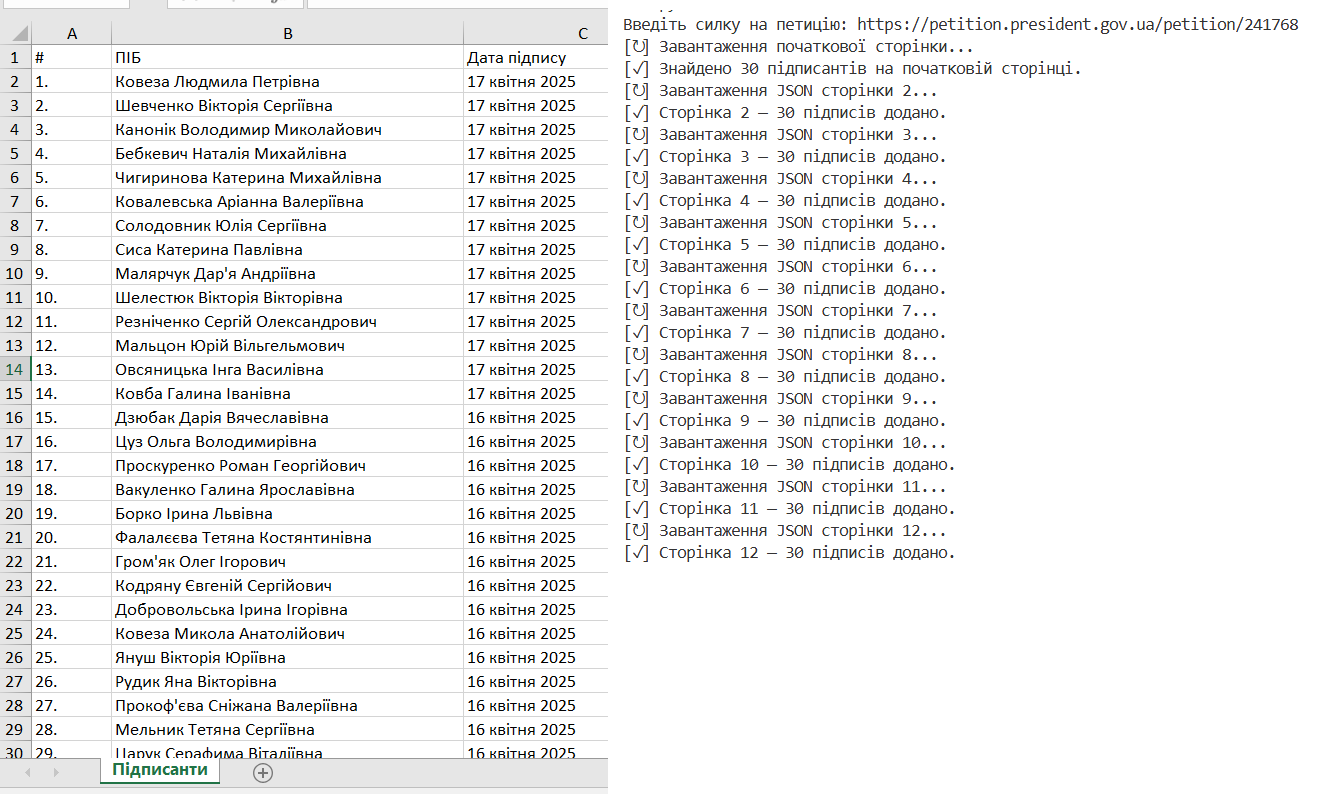
Этот парсер автоматизирует сбор информации о подписавших электронные петиции с официального сайта Президента Украины. Он принимает ссылку на конкретную петицию и последовательно собирает данные со всех страниц подписей, включая имя, фамилию и дату подписи каждого пользователя.
Парсер работает в два этапа: сначала загружает и парсит статичный HTML первой страницы петиции, где отображена часть подписантов, а затем динамически получает дополнительные страницы через AJAX-запросы к API в формате JSON. Полученные данные обрабатываются и сохраняются в формате Excel (.xlsx) с постепенным обновлением файла после каждой страницы, что обеспечивает надежность работы даже при прерывании процесса.
Используемые технологии: Python, библиотеки requests (HTTP-запросы), BeautifulSoup (парсинг HTML), openpyxl (работа с Excel), регулярные выражения (извлечение ID петиции), а также базовые механизмы обработки JSON. Парсер ориентирован на стабильную работу с большими объемами данных и учитывает особенности динамической загрузки контента.
Парсер работает в два этапа: сначала загружает и парсит статичный HTML первой страницы петиции, где отображена часть подписантов, а затем динамически получает дополнительные страницы через AJAX-запросы к API в формате JSON. Полученные данные обрабатываются и сохраняются в формате Excel (.xlsx) с постепенным обновлением файла после каждой страницы, что обеспечивает надежность работы даже при прерывании процесса.
Используемые технологии: Python, библиотеки requests (HTTP-запросы), BeautifulSoup (парсинг HTML), openpyxl (работа с Excel), регулярные выражения (извлечение ID петиции), а также базовые механизмы обработки JSON. Парсер ориентирован на стабильную работу с большими объемами данных и учитывает особенности динамической загрузки контента.