Парсинг защищенного SPA-сайта, Обход Cloudflare и антибот-систем.
Парсинг данных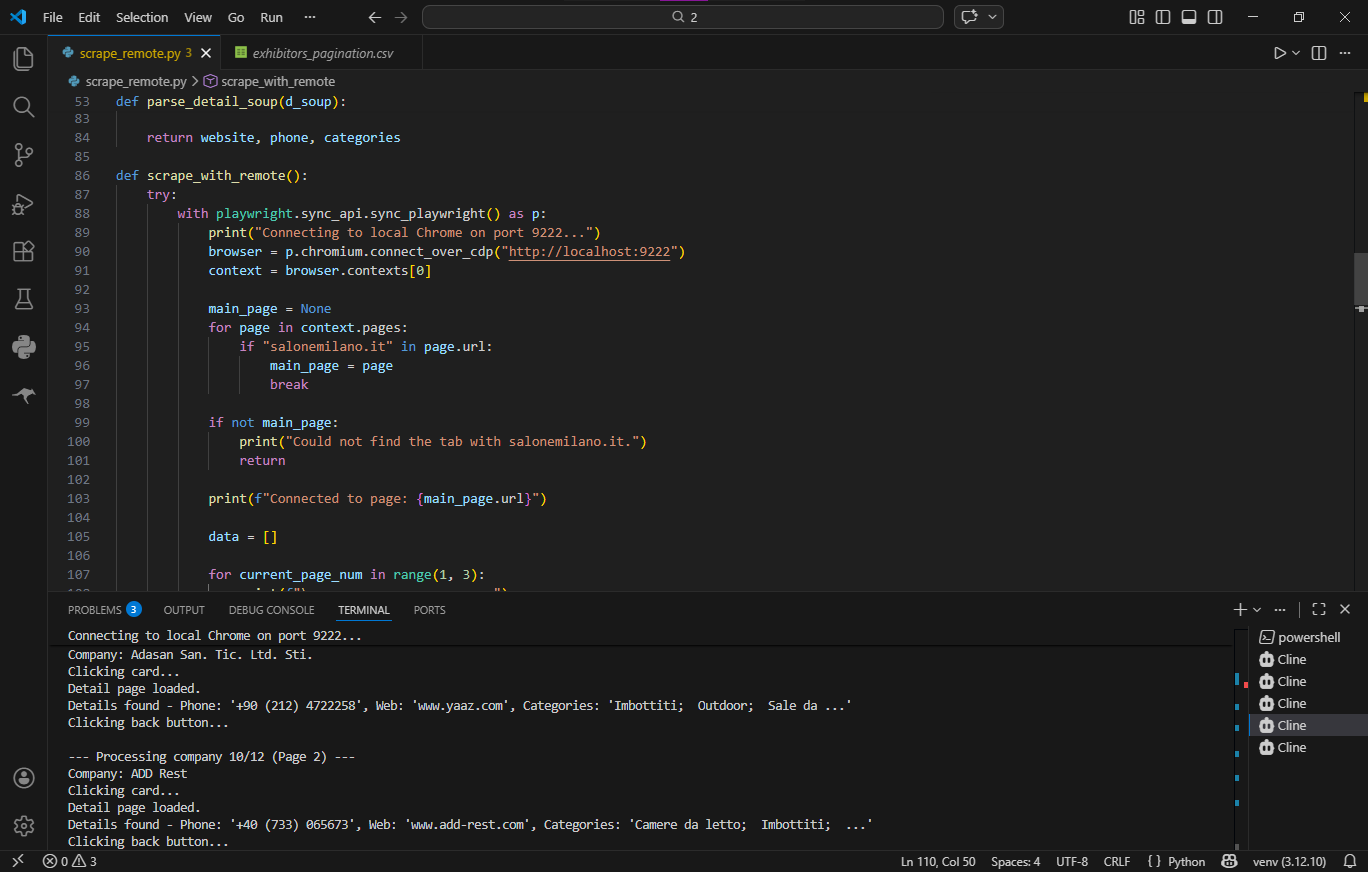
Мета: Собрать 100% точные данные о более чем 1000 экспонентах (название, страна, номер стенда, скрытые email и телефоны, категории) с официального сайта Salone del Mobile.
Главные вызовы:
Агрессивная антибот-защита (Cloudflare): Стандартные запросы (requests/httpx) возвращали 403 Forbidden. Обычные headless-браузеры (Selenium, Playwright) и даже фреймворки вроде undetected-chromedriver мгновенно блокировались.
Сложная SPA-архитектура (React / Next.js): На сайте не было стандартных HTML-ссылок (). Вся навигация происходила исключительно через обработчики событий React (onClick), что делало традиционный сбор URL невозможным. Кроме того, контактные данные были скрыты в несемантических тегах (например, ).
Мое решение:
Чтобы достичь идеальной точности и обойти защиту, я разработал кастомный гибридный подход:
Подключение через Chrome DevTools Protocol (CDP): Вместо запуска нового экземпляра автоматизированного браузера, мой скрипт использовал Playwright для подключения к уже запущенной, "живой" сессии Google Chrome (http://localhost:9222). Это дало 100% "траст-фактор" легитимного пользователя (вместе с реальными cookies, историей и отпечатками Canvas). Cloudflare было обойдено без какой-либо решенной капчи.
Интеллектуальная навигация: Скрипт визуально имитировал поведение человека — перехватывал динамические локаторы, физически кликал мышкой для вызова React-состояний и использовал внутренний роутер сайта для возврата к списку, сохраняя пагинацию.
Парсинг HTML: Захваченный состояние страницы обрабатывался через BeautifulSoup и сложные регулярные выражения (Regex) для точного извлечения "битых" или плохо отформатированных ссылок и номеров телефонов.
Использованные технологии:
Python 3.12
Playwright (Sync API): взаимодействие с DOM и подключение через CDP.
BeautifulSoup4 & Regex: точный поиск и извлечение данных.
Pandas: структурирование и экспорт данных в чистый CSV (UTF-8 с BOM) и Excel.
Результат:
Скрипт полностью автономно собрал и идеально отформатировал данные более чем 1200 компаний. Созданная архитектура позволяет масштабировать парсинг без риска получить бан по IP.
Главные вызовы:
Агрессивная антибот-защита (Cloudflare): Стандартные запросы (requests/httpx) возвращали 403 Forbidden. Обычные headless-браузеры (Selenium, Playwright) и даже фреймворки вроде undetected-chromedriver мгновенно блокировались.
Сложная SPA-архитектура (React / Next.js): На сайте не было стандартных HTML-ссылок (). Вся навигация происходила исключительно через обработчики событий React (onClick), что делало традиционный сбор URL невозможным. Кроме того, контактные данные были скрыты в несемантических тегах (например, ).
Мое решение:
Чтобы достичь идеальной точности и обойти защиту, я разработал кастомный гибридный подход:
Подключение через Chrome DevTools Protocol (CDP): Вместо запуска нового экземпляра автоматизированного браузера, мой скрипт использовал Playwright для подключения к уже запущенной, "живой" сессии Google Chrome (http://localhost:9222). Это дало 100% "траст-фактор" легитимного пользователя (вместе с реальными cookies, историей и отпечатками Canvas). Cloudflare было обойдено без какой-либо решенной капчи.
Интеллектуальная навигация: Скрипт визуально имитировал поведение человека — перехватывал динамические локаторы, физически кликал мышкой для вызова React-состояний и использовал внутренний роутер сайта для возврата к списку, сохраняя пагинацию.
Парсинг HTML: Захваченный состояние страницы обрабатывался через BeautifulSoup и сложные регулярные выражения (Regex) для точного извлечения "битых" или плохо отформатированных ссылок и номеров телефонов.
Использованные технологии:
Python 3.12
Playwright (Sync API): взаимодействие с DOM и подключение через CDP.
BeautifulSoup4 & Regex: точный поиск и извлечение данных.
Pandas: структурирование и экспорт данных в чистый CSV (UTF-8 с BOM) и Excel.
Результат:
Скрипт полностью автономно собрал и идеально отформатировал данные более чем 1200 компаний. Созданная архитектура позволяет масштабировать парсинг без риска получить бан по IP.