Python текстовый токен
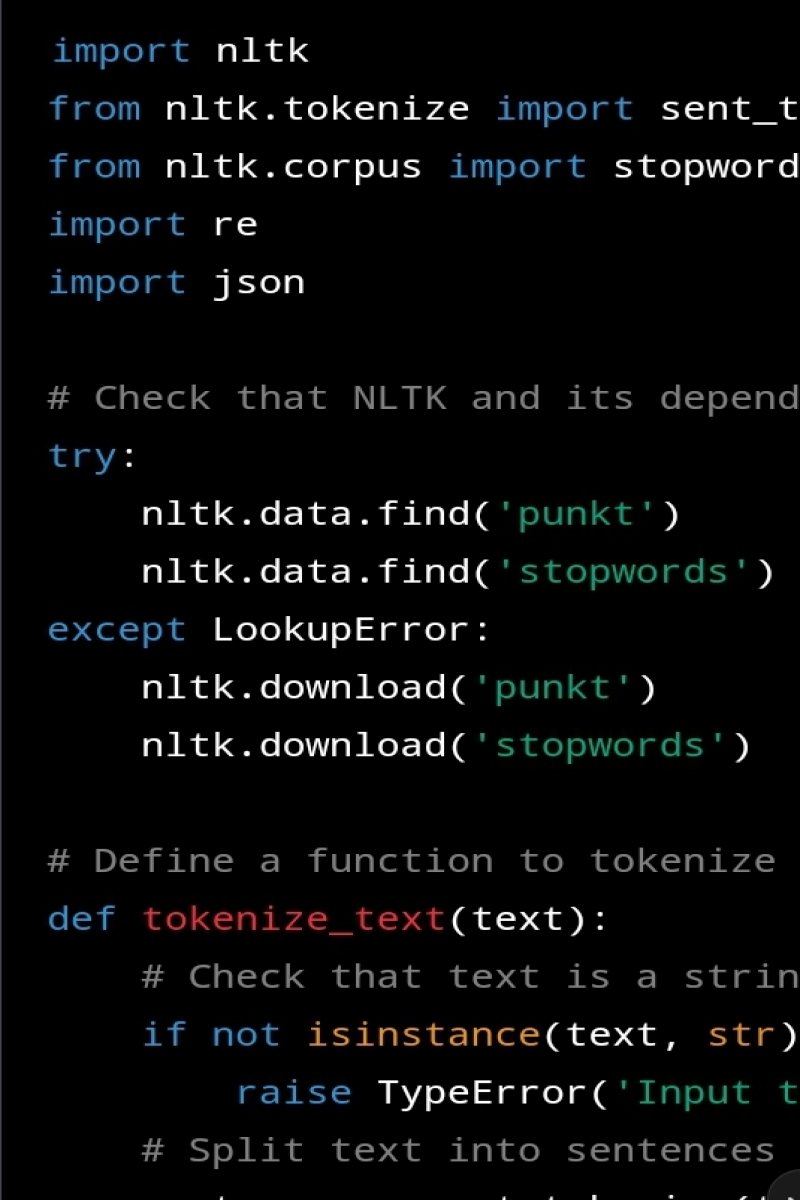
Итак, посмотрите на то, что робит этот код:
Импортуе Необхідные Библиотеки: Нltк Для Обробки Природных Явов, ре Для Регулярных Виразов Та Джсон Для Роботи З Об'Ектами Джсон.Перевиряее, что ненужные Дани Нltк Загружены.Если нет, то они загружаются.Визначає Функцию Tokenize_Text (текст), Яка Приймає Рядок текст Як Вхідни Дани Та Повертає Об'Ект Джсон, Что Мистить Кожне Слово В Тексти Та Речення, У Яких Воно Зустричается.Функция Tokenize_Text (текст) Спочатку Розбиває Текст На Окреми Речення За Допомогою Sent_Tokenize (текст) З Модуля Nltk.Tokenize.
Потем Она Створює Порожній Словник Word_Dict Для Зберігання Слово Та Їх Речень.Для Кожного Речення В Тексти Функция Токенизирует Речення На Окреми Слова За Допомогою Word_Tokenize (свенция) З Модуля Nltk.Tokenize.
Функция Потем Фильтруе Будь-Яки Зупинни Слова (Звичайные Слова, Такие Как "с" Та "и", Какие обычно не являются полезными для анализа) Та Небажані Слова (Такие Как Знаки Пунктуации Та Числа) За Допомогою Спискового Включения, Яке Перебирае Слова Та Перевиряе, Что Кожне Слово Не Миститься В Множини Английских Зупинных Слова (Stopwords.Words ('English')) Та Что Воно Не Складается Виключно З Символов, Какие Не Є Словами (За Допомогою ReMatch ('^ [W_] + $', слово).Функция Потім Перебирае Отфильтрованы Слова Та Додае Кожне Слово Та Индекс Речення, В Яком Воно Зустрічается, До Word_Dict.Если Слово Вже Е У Словнику, Функция Додае Индекс Речення До Списка Речень, У Яких Зустрічается Слово.Нарешті, Word_Dict Перетворюется На Об'Ект Json За Допомогою Json.Dumps (Word_Dict)
Импортуе Необхідные Библиотеки: Нltк Для Обробки Природных Явов, ре Для Регулярных Виразов Та Джсон Для Роботи З Об'Ектами Джсон.Перевиряее, что ненужные Дани Нltк Загружены.Если нет, то они загружаются.Визначає Функцию Tokenize_Text (текст), Яка Приймає Рядок текст Як Вхідни Дани Та Повертає Об'Ект Джсон, Что Мистить Кожне Слово В Тексти Та Речення, У Яких Воно Зустричается.Функция Tokenize_Text (текст) Спочатку Розбиває Текст На Окреми Речення За Допомогою Sent_Tokenize (текст) З Модуля Nltk.Tokenize.
Потем Она Створює Порожній Словник Word_Dict Для Зберігання Слово Та Їх Речень.Для Кожного Речення В Тексти Функция Токенизирует Речення На Окреми Слова За Допомогою Word_Tokenize (свенция) З Модуля Nltk.Tokenize.
Функция Потем Фильтруе Будь-Яки Зупинни Слова (Звичайные Слова, Такие Как "с" Та "и", Какие обычно не являются полезными для анализа) Та Небажані Слова (Такие Как Знаки Пунктуации Та Числа) За Допомогою Спискового Включения, Яке Перебирае Слова Та Перевиряе, Что Кожне Слово Не Миститься В Множини Английских Зупинных Слова (Stopwords.Words ('English')) Та Что Воно Не Складается Виключно З Символов, Какие Не Є Словами (За Допомогою ReMatch ('^ [W_] + $', слово).Функция Потім Перебирае Отфильтрованы Слова Та Додае Кожне Слово Та Индекс Речення, В Яком Воно Зустрічается, До Word_Dict.Если Слово Вже Е У Словнику, Функция Додае Индекс Речення До Списка Речень, У Яких Зустрічается Слово.Нарешті, Word_Dict Перетворюется На Об'Ект Json За Допомогою Json.Dumps (Word_Dict)
 Киев
Киев