Системы рекомендаций для ресторанов
AI и машинное обучение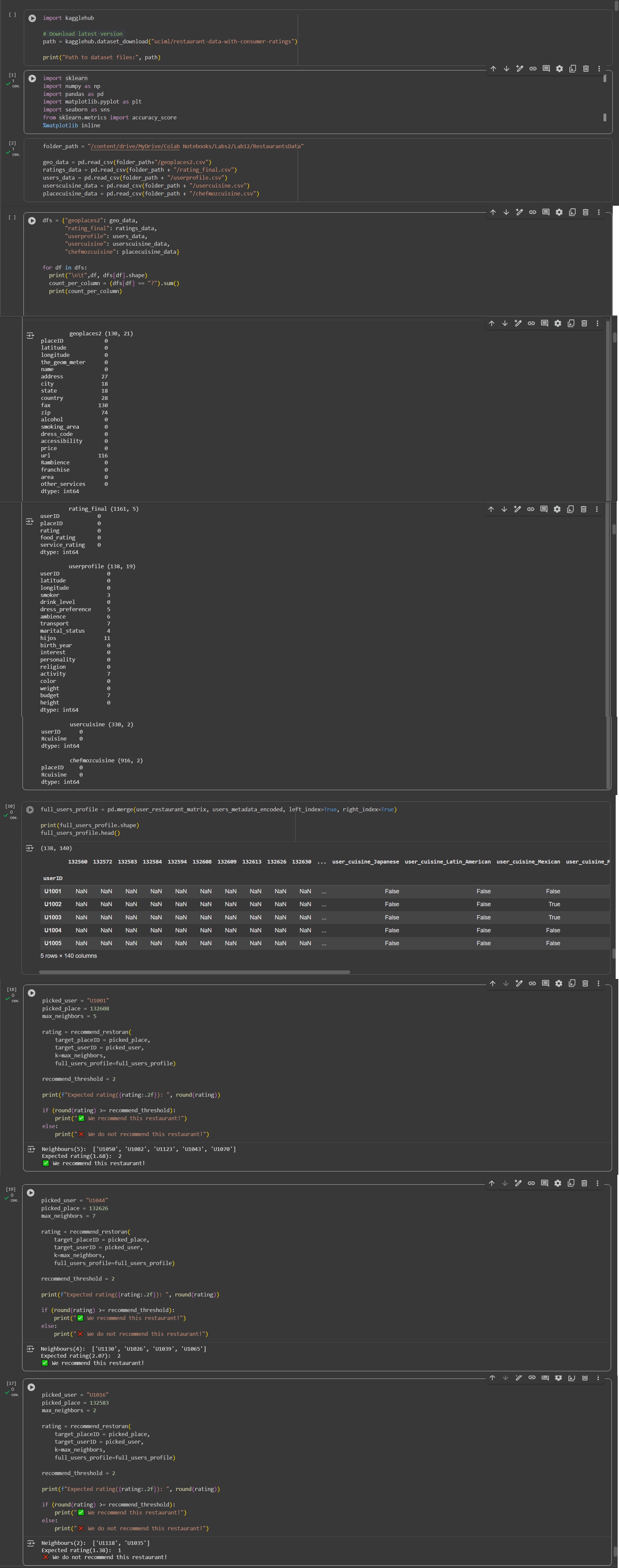
Работа направлена на разработку системы рекомендаций заведений питания (ресторанов) для отдельных пользователей. Основной фокус работы заключался в предварительной обработке сложного, многотабличного набора данных и построении модели, способной прогнозировать, понравится ли конкретный ресторан конкретному пользователю.
Целью было создать функцию прогнозирования (рекомендации) рейтинга ресторана для пользователя на основе данных профилей пользователей и их предыдущих оценок. То есть выполнение задачи User-based collaborative filtering с использованием KNN.
Шаги для выполнения:
• Загрузка и объединение данных из пяти различных источников.
• Выявление и обработка пропущенных и неконсистентных значений в данных.
• Очистка и нормализация географических и мета-данных пользователей и ресторанов.
• Создание модели рекомендательной системы.
Используемые данные
Проект использует набор данных restaurant-data-with-consumer-ratings, состоящий из 9 таблиц, из которых были использованы пять взаимосвязанных CSV-файлов:
1. geoplaces2.csv: Географические характеристики и атрибуты заведений (например, ценовой диапазон, алкоголь, дресс-код и др.).
2. rating_final.csv: Финальные оценки пользователей заведениям (общий рейтинг, рейтинг еды, рейтинг обслуживания).
3. userprofile.csv: Демографические и поведенческие профили пользователей (например, уровень потребления алкоголя, никотина, бюджет и др.).
4. usercuisine.csv: Предпочтения пользователей относительно кухни.
5. chefmozcuisine.csv: Типы кухни, которые предлагают заведения.
Моделирование
• Применена концепция User-Based Collaborative Filtering (UBCF), где KNN использовался для поиска K-ближайших соседей на основе метрик сходства косинуса (Cosine Similarity).
• Оптимизация: Устранены проблемы масштабируемости классического UBCF путем использования оптимизированных методов, подтверждена необходимость перехода к взвешенному среднему (Weighted Average) для точного прогноза рейтинга, который основан на расстояниях и индексах соседей.
• Функция рекомендации: Разработана функция recommend_restoran(), которая принимает целевое заведение (target_placeID), целевого пользователя (target_userID) и количество соседей (k) для прогнозирования рейтинга.
• Критерий рекомендации: Прогнозируемый рейтинг округляется, и если он равен или превышает пороговое значение (recommend_threshold), ресторан рекомендуется.
Используемые технологии
Язык программирования: Python
Библиотеки:
• pandas, numpy: Обработка и манипуляции с данными.
• requests: Для вызова внешнего гео-сервиса (GPS-Coordinates.net).
• sklearn (Scikit-learn): Использование метрик.
P.S На скриншоте показаны количества пропусков данных в таблицах, с которыми я работал, финальная матрица для расчетов и 3 результата работы функции.
#ML #machinelearining #datascience #database #analitycs #dataanalysis
Целью было создать функцию прогнозирования (рекомендации) рейтинга ресторана для пользователя на основе данных профилей пользователей и их предыдущих оценок. То есть выполнение задачи User-based collaborative filtering с использованием KNN.
Шаги для выполнения:
• Загрузка и объединение данных из пяти различных источников.
• Выявление и обработка пропущенных и неконсистентных значений в данных.
• Очистка и нормализация географических и мета-данных пользователей и ресторанов.
• Создание модели рекомендательной системы.
Используемые данные
Проект использует набор данных restaurant-data-with-consumer-ratings, состоящий из 9 таблиц, из которых были использованы пять взаимосвязанных CSV-файлов:
1. geoplaces2.csv: Географические характеристики и атрибуты заведений (например, ценовой диапазон, алкоголь, дресс-код и др.).
2. rating_final.csv: Финальные оценки пользователей заведениям (общий рейтинг, рейтинг еды, рейтинг обслуживания).
3. userprofile.csv: Демографические и поведенческие профили пользователей (например, уровень потребления алкоголя, никотина, бюджет и др.).
4. usercuisine.csv: Предпочтения пользователей относительно кухни.
5. chefmozcuisine.csv: Типы кухни, которые предлагают заведения.
Моделирование
• Применена концепция User-Based Collaborative Filtering (UBCF), где KNN использовался для поиска K-ближайших соседей на основе метрик сходства косинуса (Cosine Similarity).
• Оптимизация: Устранены проблемы масштабируемости классического UBCF путем использования оптимизированных методов, подтверждена необходимость перехода к взвешенному среднему (Weighted Average) для точного прогноза рейтинга, который основан на расстояниях и индексах соседей.
• Функция рекомендации: Разработана функция recommend_restoran(), которая принимает целевое заведение (target_placeID), целевого пользователя (target_userID) и количество соседей (k) для прогнозирования рейтинга.
• Критерий рекомендации: Прогнозируемый рейтинг округляется, и если он равен или превышает пороговое значение (recommend_threshold), ресторан рекомендуется.
Используемые технологии
Язык программирования: Python
Библиотеки:
• pandas, numpy: Обработка и манипуляции с данными.
• requests: Для вызова внешнего гео-сервиса (GPS-Coordinates.net).
• sklearn (Scikit-learn): Использование метрик.
P.S На скриншоте показаны количества пропусков данных в таблицах, с которыми я работал, финальная матрица для расчетов и 3 результата работы функции.
#ML #machinelearining #datascience #database #analitycs #dataanalysis