Smart Chunker: подготовка документов для RAG и векторных баз
AI и машинное обучение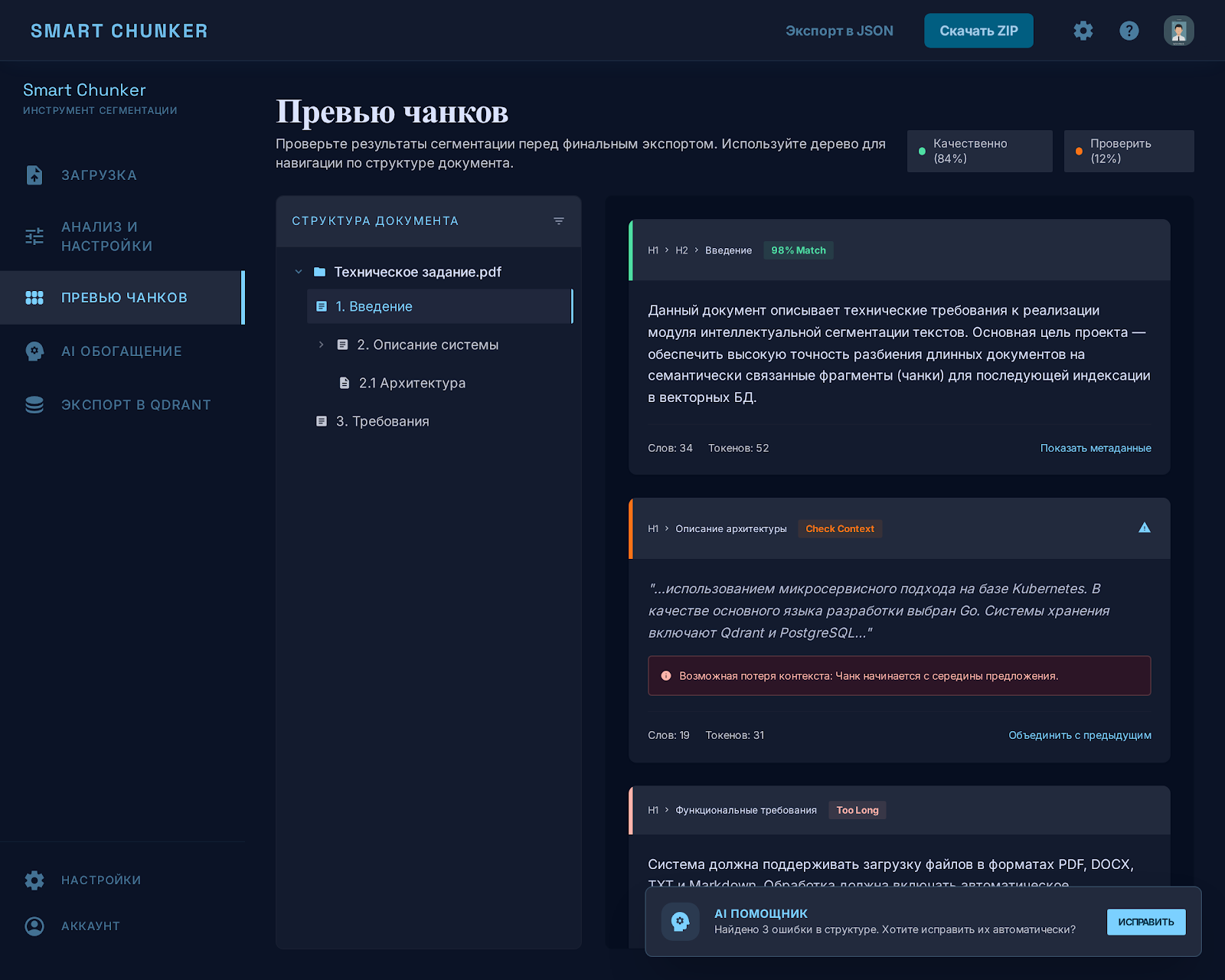
AI-агент отвечает настолько хорошо, насколько подготовлен его контекст. Чтобы готовить большую базу знаний к RAG, я сделал Smart Chunker: он режет Markdown на содержательные чанки, показывает проблемные места и загружает готовые данные в векторную базу. Перед поиском знания приводятся к нормальному виду, без обрывков и дубликатов.
Что внутри:
- Детерминированное ядро: разбор Markdown в дерево заголовков H1-H3 и 7 правил чанкинга, без overlap.
- Автоподбор размеров чанков перебором сетки до 2500 комбинаций.
- Контроль качества виден в интерфейсе: проблемные чанки подсвечиваются, система подсказывает, что поправить.
- AI-слой: архитектор предлагает схему метаданных, агент обогащает чанки пакетами, результат проходит валидацию.
- Загрузка в Qdrant: dense-векторы через embeddings, sparse через локальный BM25, обновление через Smart Match. 20 API-точек.
API-ключи живут только в браузере и не хранятся на сервере. Базовый чанкинг работает и без внешних моделей.
#Python #RAG #Qdrant #FastAPI #AI #VectorDB #LLM #NLP #VanillaJS #OpenAI #Anthropic #BM25 #SSE
Что внутри:
- Детерминированное ядро: разбор Markdown в дерево заголовков H1-H3 и 7 правил чанкинга, без overlap.
- Автоподбор размеров чанков перебором сетки до 2500 комбинаций.
- Контроль качества виден в интерфейсе: проблемные чанки подсвечиваются, система подсказывает, что поправить.
- AI-слой: архитектор предлагает схему метаданных, агент обогащает чанки пакетами, результат проходит валидацию.
- Загрузка в Qdrant: dense-векторы через embeddings, sparse через локальный BM25, обновление через Smart Match. 20 API-точек.
API-ключи живут только в браузере и не хранятся на сервере. Базовый чанкинг работает и без внешних моделей.
#Python #RAG #Qdrant #FastAPI #AI #VectorDB #LLM #NLP #VanillaJS #OpenAI #Anthropic #BM25 #SSE