Система веб-скрейпинга и обработки данных
Парсинг данных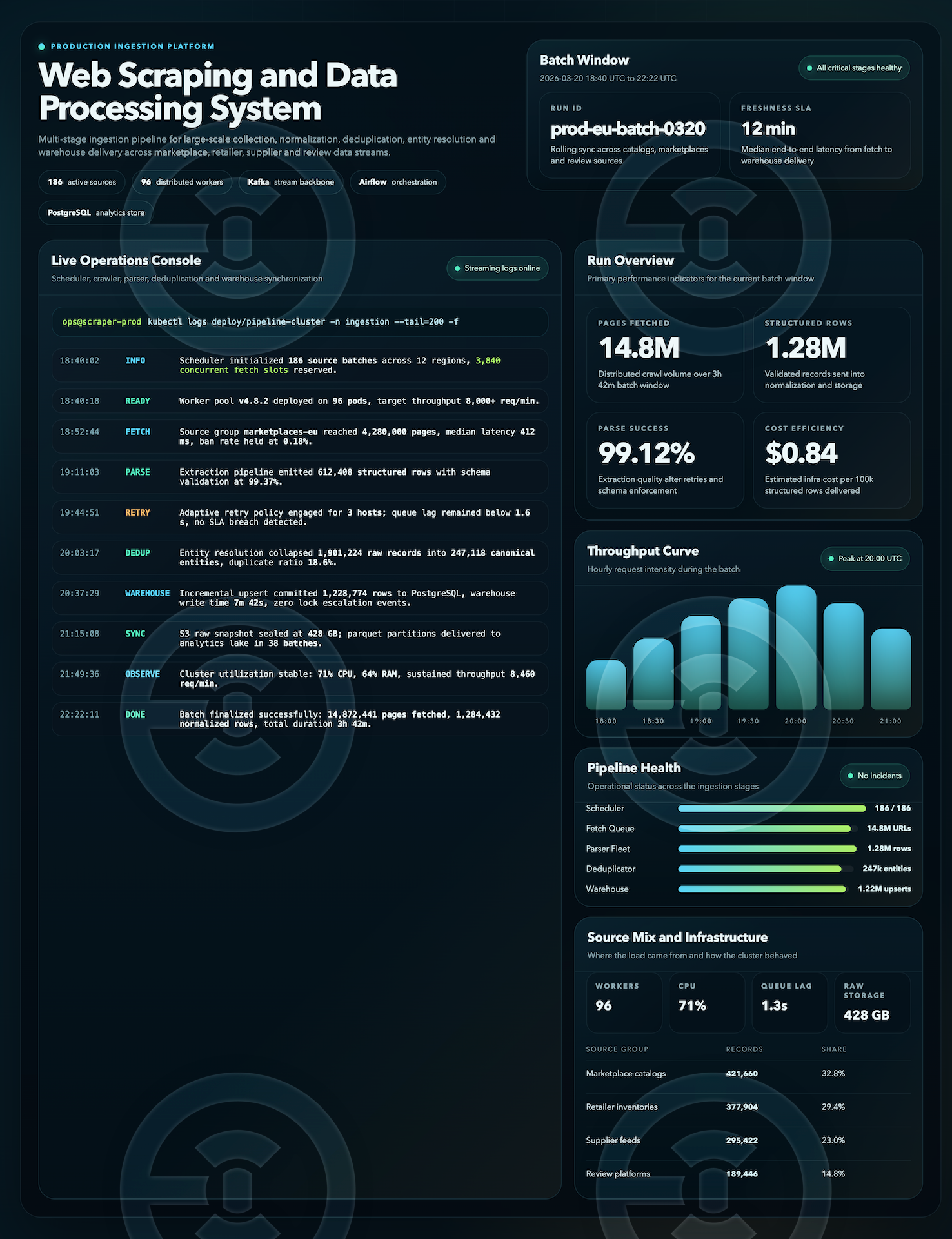
Разработка системы веб-скрейпинга и обработки данных для многоэтапного сбора, нормализации, дедупликации и подготовки больших массивов информации к дальнейшему использованию в аналитике и внутренних бизнес-процессах.
В рамках работы была продумана структура ingestion pipeline для массового сбора данных из нескольких типов источников с дальнейшей обработкой через очереди, нормализацию сущностей, валидацию структуры, дедупликацию и подготовку к загрузке в хранилище. Отдельное внимание уделено стабильности batch-обработки, качеству данных и наблюдаемости всех ключевых этапов пайплайна.
Что реализовано по логике проекта:
— многоэтапный pipeline сбора и обработки данных
— распределённая обработка источников и batch-задач
— нормализация и дедупликация записей
— контроль latency, throughput и качества обработки
— подготовка данных для warehouse / analytics use cases
— мониторинг состояния пайплайна, логов и операционных метрик
Стек и подход:
web scraping, data processing, batch pipelines, normalization, deduplication, PostgreSQL, Kafka, Airflow, warehouse-oriented ingestion, operational monitoring.
Результат:
получилась структурированная система для массового сбора и обработки данных с акцентом на стабильность, качество данных, прозрачность pipeline-процессов и удобство дальнейшего масштабирования.
В рамках работы была продумана структура ingestion pipeline для массового сбора данных из нескольких типов источников с дальнейшей обработкой через очереди, нормализацию сущностей, валидацию структуры, дедупликацию и подготовку к загрузке в хранилище. Отдельное внимание уделено стабильности batch-обработки, качеству данных и наблюдаемости всех ключевых этапов пайплайна.
Что реализовано по логике проекта:
— многоэтапный pipeline сбора и обработки данных
— распределённая обработка источников и batch-задач
— нормализация и дедупликация записей
— контроль latency, throughput и качества обработки
— подготовка данных для warehouse / analytics use cases
— мониторинг состояния пайплайна, логов и операционных метрик
Стек и подход:
web scraping, data processing, batch pipelines, normalization, deduplication, PostgreSQL, Kafka, Airflow, warehouse-oriented ingestion, operational monitoring.
Результат:
получилась структурированная система для массового сбора и обработки данных с акцентом на стабильность, качество данных, прозрачность pipeline-процессов и удобство дальнейшего масштабирования.