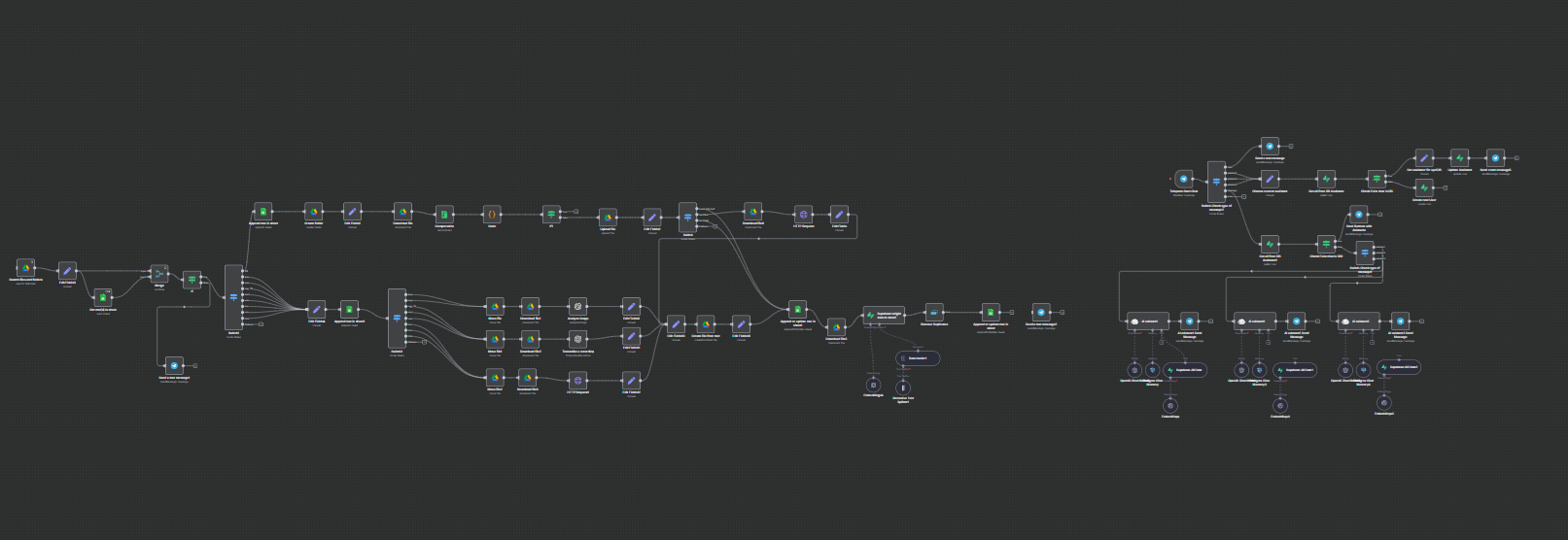
Projekt: Zautomatyzowany system zbierania treści i tworzenia Bazy Wiedzy na podstawie AI
Główne funkcje i realizacja techniczna
1. Przepływ danych wejściowych i filtracja:
Trigger regularnie skanuje wskazany folder na Google Drive w poszukiwaniu nowych plików.
Niezawodny mechanizm deduplikacji sprawdza "rejestr" w Google Sheets, aby zapewnić, że pliki są przetwarzane tylko raz. Nowe pliki są natychmiast rejestrowane ze statusem pending (oczekujące).
2. Modularna architektura przetwarzania ("Router"):
Centralny węzeł Switch działa jako router, kierując pliki do różnych gałęzi przetwarzania na podstawie ich typu MIME. Ta architektura jest łatwo skalowalna, co pozwala na dodawanie nowych typów plików przy minimalnych zmianach.
Gałąź dla archiwów ZIP:
Archiwa są rozpakowywane, a ich zawartość jest kierowana z powrotem na początek procesu roboczego do indywidualnego przetwarzania. Oryginalne archiwum jest natychmiast rejestrowane i przenoszone, aby uniknąć ponownego przetwarzania.
Gałąź dla dokumentów (.doc, .docx, .html):
Pliki są wysyłane do specjalnie stworzonego mikroserwisu na Node.js do parsowania. Serwis wykorzystuje specjalistyczne biblioteki (docx-parser, textract, node-html-parser) do wydobywania czystego tekstu.
Gałąź dla obrazów (.jpeg, .png):
Obrazy są przesyłane i wysyłane do OpenAI Vision API (gpt-4o) z szczegółowym promptem do wykonania optycznego rozpoznawania znaków (OCR) oraz opisu elementów wizualnych, zwracając strukturalny tekst.
Gałąź dla audio (.mp3, .wav, .ogg):
Pliki audio są wysyłane do OpenAI Whisper API w celu dokładnej transkrypcji mowy na tekst.
3. Standaryzacja i przechowywanie treści:
Wynik każdej gałęzi przetwarzania (wydobyty tekst) jest standaryzowany do jednolitego formatu.
Nowy plik tekstowy zawierający wydobytą treść jest tworzony i przechowywany na Google Drive w celu archiwizacji.
Następnie tekst jest przekazywany do przepływu opartego na LangChain:
Podział tekstu: Duże dokumenty są dzielone na mniejsze, częściowo nakładające się fragmenty (chunki), aby spełnić ograniczenia okna kontekstowego modeli dla embeddingów.
Tworzenie embeddingów: Każda część tekstu jest przekształcana na wektor numeryczny za pomocą modeli embeddingów od OpenAI.
Przechowywanie w bazie wektorowej: Embeddingi i powiązane z nimi metadane (ID pliku źródłowego, nazwa, link do źródła) są przechowywane w bazie danych Supabase z wykorzystaniem rozszerzenia pgvector.
4. Zarządzanie stanem i powiadomienia:
Po pomyślnym przetworzeniu i zapisaniu w bazie wektorowej, odpowiedni wpis w rejestrze Google Sheets jest aktualizowany do statusu completed.
Oryginalny plik źródłowy jest przenoszony z folderu wejściowego do katalogu archiwalnego "Processed" na Google Drive.
Powiadomienie w czasie rzeczywistym, zawierające szczegóły przetworzonego pliku oraz link do oryginału, jest wysyłane do określonego czatu Telegram.
5. Integracja z asystentem AI (komponent dla użytkownika):
System obejmuje wieloagentowego bota Telegram, gdzie użytkownicy mogą wybierać różnych "asystentów".
Każdy asystent jest skonfigurowany z unikalnym systemowym promptem i może być podłączony do własnej dedykowanej bazy wektorowej lub źródła wiedzy.
Historia czatu dla każdego użytkownika i asystenta jest przechowywana w bazie danych Postgres, co zapewnia kontekstowe, ciągłe rozmowy.
Wykorzystane technologie
Orkiestracja: n8n (self-hosted)
Źródła danych i przechowywanie: Google Drive, Google Sheets
Baza danych wektorowa: Supabase (z Postgres i pgvector)
Sztuczna inteligencja i embeddingi: OpenAI (GPT-4o dla Vision, Whisper dla Audio, modele dla Text Embedding), LangChain.js (w ramach n8n)
Niestandardowe parsowanie: Node.js, Express.js, docx-parser, textract, node-html-parser
Interfejs użytkownika: Telegram Bot API
Główne funkcje i realizacja techniczna
1. Przepływ danych wejściowych i filtracja:
Trigger regularnie skanuje wskazany folder na Google Drive w poszukiwaniu nowych plików.
Niezawodny mechanizm deduplikacji sprawdza "rejestr" w Google Sheets, aby zapewnić, że pliki są przetwarzane tylko raz. Nowe pliki są natychmiast rejestrowane ze statusem pending (oczekujące).
2. Modularna architektura przetwarzania ("Router"):
Centralny węzeł Switch działa jako router, kierując pliki do różnych gałęzi przetwarzania na podstawie ich typu MIME. Ta architektura jest łatwo skalowalna, co pozwala na dodawanie nowych typów plików przy minimalnych zmianach.
Gałąź dla archiwów ZIP:
Archiwa są rozpakowywane, a ich zawartość jest kierowana z powrotem na początek procesu roboczego do indywidualnego przetwarzania. Oryginalne archiwum jest natychmiast rejestrowane i przenoszone, aby uniknąć ponownego przetwarzania.
Gałąź dla dokumentów (.doc, .docx, .html):
Pliki są wysyłane do specjalnie stworzonego mikroserwisu na Node.js do parsowania. Serwis wykorzystuje specjalistyczne biblioteki (docx-parser, textract, node-html-parser) do wydobywania czystego tekstu.
Gałąź dla obrazów (.jpeg, .png):
Obrazy są przesyłane i wysyłane do OpenAI Vision API (gpt-4o) z szczegółowym promptem do wykonania optycznego rozpoznawania znaków (OCR) oraz opisu elementów wizualnych, zwracając strukturalny tekst.
Gałąź dla audio (.mp3, .wav, .ogg):
Pliki audio są wysyłane do OpenAI Whisper API w celu dokładnej transkrypcji mowy na tekst.
3. Standaryzacja i przechowywanie treści:
Wynik każdej gałęzi przetwarzania (wydobyty tekst) jest standaryzowany do jednolitego formatu.
Nowy plik tekstowy zawierający wydobytą treść jest tworzony i przechowywany na Google Drive w celu archiwizacji.
Następnie tekst jest przekazywany do przepływu opartego na LangChain:
Podział tekstu: Duże dokumenty są dzielone na mniejsze, częściowo nakładające się fragmenty (chunki), aby spełnić ograniczenia okna kontekstowego modeli dla embeddingów.
Tworzenie embeddingów: Każda część tekstu jest przekształcana na wektor numeryczny za pomocą modeli embeddingów od OpenAI.
Przechowywanie w bazie wektorowej: Embeddingi i powiązane z nimi metadane (ID pliku źródłowego, nazwa, link do źródła) są przechowywane w bazie danych Supabase z wykorzystaniem rozszerzenia pgvector.
4. Zarządzanie stanem i powiadomienia:
Po pomyślnym przetworzeniu i zapisaniu w bazie wektorowej, odpowiedni wpis w rejestrze Google Sheets jest aktualizowany do statusu completed.
Oryginalny plik źródłowy jest przenoszony z folderu wejściowego do katalogu archiwalnego "Processed" na Google Drive.
Powiadomienie w czasie rzeczywistym, zawierające szczegóły przetworzonego pliku oraz link do oryginału, jest wysyłane do określonego czatu Telegram.
5. Integracja z asystentem AI (komponent dla użytkownika):
System obejmuje wieloagentowego bota Telegram, gdzie użytkownicy mogą wybierać różnych "asystentów".
Każdy asystent jest skonfigurowany z unikalnym systemowym promptem i może być podłączony do własnej dedykowanej bazy wektorowej lub źródła wiedzy.
Historia czatu dla każdego użytkownika i asystenta jest przechowywana w bazie danych Postgres, co zapewnia kontekstowe, ciągłe rozmowy.
Wykorzystane technologie
Orkiestracja: n8n (self-hosted)
Źródła danych i przechowywanie: Google Drive, Google Sheets
Baza danych wektorowa: Supabase (z Postgres i pgvector)
Sztuczna inteligencja i embeddingi: OpenAI (GPT-4o dla Vision, Whisper dla Audio, modele dla Text Embedding), LangChain.js (w ramach n8n)
Niestandardowe parsowanie: Node.js, Express.js, docx-parser, textract, node-html-parser
Interfejs użytkownika: Telegram Bot API