System rozpoznawania tablic rejestracyjnych (ALPR)
AI i uczenie maszynowe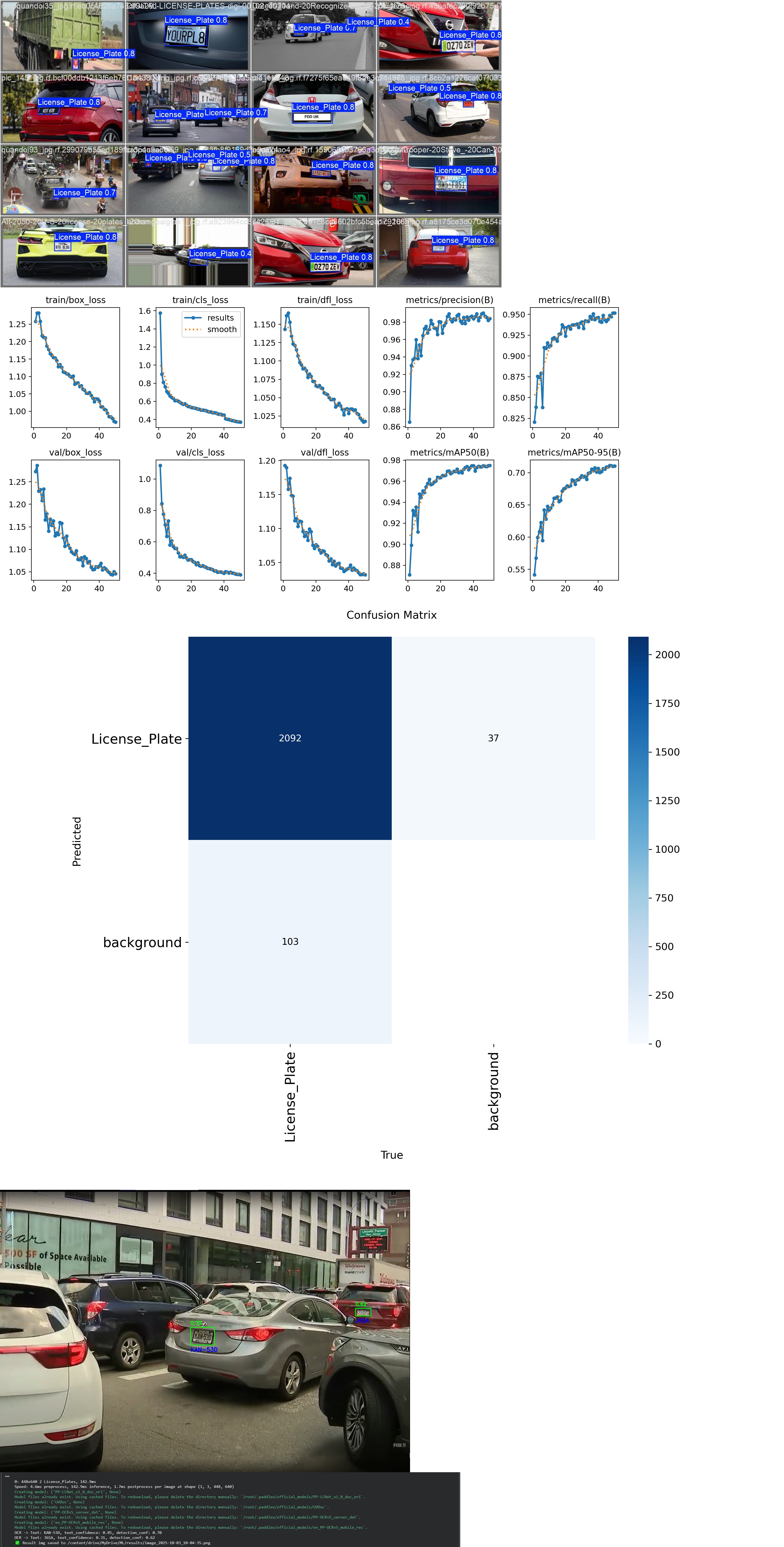
O projekcie
Projekt ma na celu stworzenie systemu komputerowego widzenia do automatycznej identyfikacji pojazdów poprzez odczytywanie ich tablic rejestracyjnych. System działa w dwóch etapach: najpierw znajduje numer na obrazie, a następnie rozpoznaje tekst na nim.
Wytrenuj model na niestandardowym zbiorze danych, osiągając wysoką dokładność lokalizacji numeru.
Zintegrowałem bibliotekę PaddleOCR do wyodrębniania tekstu z przyciętych (cropped) obrazów numerów.
Zrealizowałem skrypt w Pythonie z użyciem OpenCV do wizualizacji wyników (ramki ograniczające + tekst) oraz filtrowania prognoz według progu pewności (confidence threshold).
Pipeline inferencji:
1. Obraz jest podawany na wejście modelu.
2. Otrzymane współrzędne (xyxy) są używane do wycięcia obszaru numeru (ROI crop).
3. Wycięty fragment jest przekazywany do PaddleOCR w celu rozpoznania tekstu.
4. Wynik jest filtrowany według progu pewności (conf_thresh=0.5).
Wizualizacja:
Za pomocą OpenCV na oryginalny obraz nakładane są ramki oraz rozpoznany tekst, wynik jest zapisywany lokalnie.
Stos technologiczny
• Język: Python
• Frameworki ML/DL: PyTorch, PaddlePaddle
• Biblioteki CV: Ultralytics (YOLO), PaddleOCR, OpenCV
#machinelearning #computervision #ML #AI
Projekt ma na celu stworzenie systemu komputerowego widzenia do automatycznej identyfikacji pojazdów poprzez odczytywanie ich tablic rejestracyjnych. System działa w dwóch etapach: najpierw znajduje numer na obrazie, a następnie rozpoznaje tekst na nim.
Wytrenuj model na niestandardowym zbiorze danych, osiągając wysoką dokładność lokalizacji numeru.
Zintegrowałem bibliotekę PaddleOCR do wyodrębniania tekstu z przyciętych (cropped) obrazów numerów.
Zrealizowałem skrypt w Pythonie z użyciem OpenCV do wizualizacji wyników (ramki ograniczające + tekst) oraz filtrowania prognoz według progu pewności (confidence threshold).
Pipeline inferencji:
1. Obraz jest podawany na wejście modelu.
2. Otrzymane współrzędne (xyxy) są używane do wycięcia obszaru numeru (ROI crop).
3. Wycięty fragment jest przekazywany do PaddleOCR w celu rozpoznania tekstu.
4. Wynik jest filtrowany według progu pewności (conf_thresh=0.5).
Wizualizacja:
Za pomocą OpenCV na oryginalny obraz nakładane są ramki oraz rozpoznany tekst, wynik jest zapisywany lokalnie.
Stos technologiczny
• Język: Python
• Frameworki ML/DL: PyTorch, PaddlePaddle
• Biblioteki CV: Ultralytics (YOLO), PaddleOCR, OpenCV
#machinelearning #computervision #ML #AI