Autonomiczny system AI RAG z wektorową bazą wiedzy
AI i uczenie maszynowe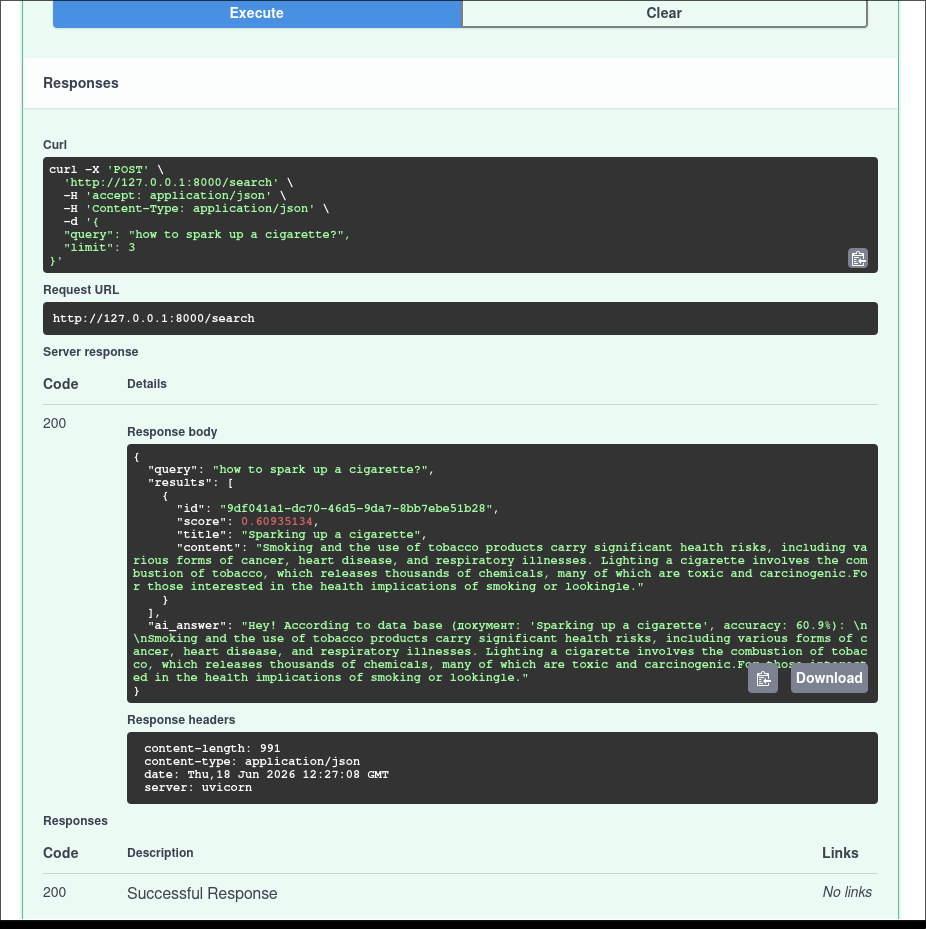
Zaprojektowałem i zrealizowałem od podstaw asynchroniczny system RAG (Retrieval-Augmented Generation) do inteligentnej analizy i wyszukiwania w skomplikowanej dokumentacji technicznej oraz wewnętrznych bazach wiedzy firmy.
Co zostało zrealizowane w projekcie:
• Asynchroniczny backend: Wysokowydajne API na FastAPI z walidacją danych wejściowych w czasie rzeczywistym za pomocą Pydantic v2.
• Wektorowe jądro: Nattywny semantyczny wyszukiwanie w bazie danych Qdrant według metryki kosinusowego podobieństwa z wykorzystaniem lokalnych embeddingów (wymiar wektora — 384, float32).
• Orkiestracja AI: Logika działania agenta oparta na strukturach grafowych LangGraph (StateGraph) z jedynym wątkowo bezpiecznym stanem, co umożliwia łatwe dodawanie cykli regeneracji lub węzłów walidacji odpowiedzi.
• Strategia chunkowania: Wdrożono inteligentne dzielenie tekstu na chunki (400 znaków) z nakładaniem (overlap 100 znaków), co całkowicie wyeliminowało utratę kontekstu na styku zdań i usunęło halucynacje modelu.
System jest elastyczny: może działać zarówno z lokalnymi modelami (przez Ollama), jak i z chmurowymi API (Gemini, Claude, OpenAI). Cała infrastruktura jest w pełni konteneryzowana za pomocą Docker Compose i gotowa do wdrożenia na serwer.
Co zostało zrealizowane w projekcie:
• Asynchroniczny backend: Wysokowydajne API na FastAPI z walidacją danych wejściowych w czasie rzeczywistym za pomocą Pydantic v2.
• Wektorowe jądro: Nattywny semantyczny wyszukiwanie w bazie danych Qdrant według metryki kosinusowego podobieństwa z wykorzystaniem lokalnych embeddingów (wymiar wektora — 384, float32).
• Orkiestracja AI: Logika działania agenta oparta na strukturach grafowych LangGraph (StateGraph) z jedynym wątkowo bezpiecznym stanem, co umożliwia łatwe dodawanie cykli regeneracji lub węzłów walidacji odpowiedzi.
• Strategia chunkowania: Wdrożono inteligentne dzielenie tekstu na chunki (400 znaków) z nakładaniem (overlap 100 znaków), co całkowicie wyeliminowało utratę kontekstu na styku zdań i usunęło halucynacje modelu.
System jest elastyczny: może działać zarówno z lokalnymi modelami (przez Ollama), jak i z chmurowymi API (Gemini, Claude, OpenAI). Cała infrastruktura jest w pełni konteneryzowana za pomocą Docker Compose i gotowa do wdrożenia na serwer.