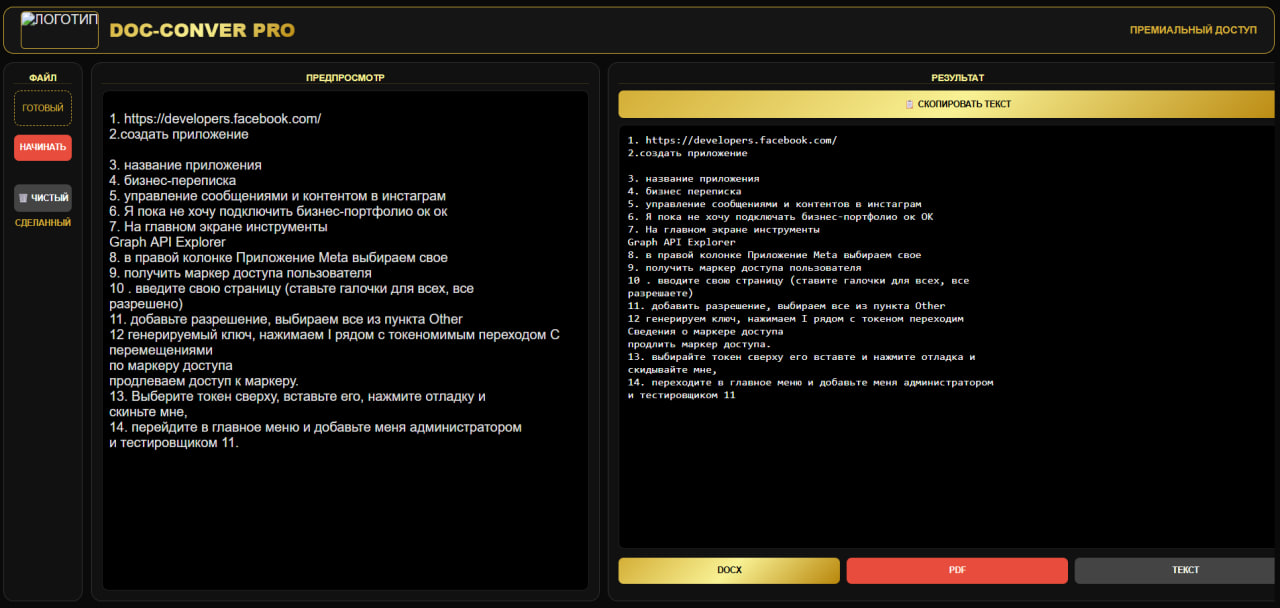
Profesjonalne rozwiązanie do automatyzacji obiegu dokumentów z naciskiem na prywatność danych.
Kluczowa funkcjonalność:
Wielojęzyczny OCR: rozpoznawanie tekstu w języku ukraińskim, angielskim, polskim, niemieckim i rosyjskim za pomocą Tesseract.
Konwersja: wsparcie dla formatów PDF, DOCX i obrazów.
Bezpieczeństwo: możliwość wdrożenia w zamkniętej infrastrukturze klienta (Self-hosted), dane nie są przesyłane na zewnętrzne serwery.
Infrastruktura: projekt w pełni konteneryzowany (Docker, Docker Compose), skonfigurowany serwer WWW Nginx z obsługą SSL (HTTPS).
Stos technologiczny: Python (Flask), Tesseract OCR, Docker, Nginx, JavaScript (podgląd plików).
System gotowy do integracji w projektach B2B lub do użycia jako samodzielna usługa.
Kluczowa funkcjonalność:
Wielojęzyczny OCR: rozpoznawanie tekstu w języku ukraińskim, angielskim, polskim, niemieckim i rosyjskim za pomocą Tesseract.
Konwersja: wsparcie dla formatów PDF, DOCX i obrazów.
Bezpieczeństwo: możliwość wdrożenia w zamkniętej infrastrukturze klienta (Self-hosted), dane nie są przesyłane na zewnętrzne serwery.
Infrastruktura: projekt w pełni konteneryzowany (Docker, Docker Compose), skonfigurowany serwer WWW Nginx z obsługą SSL (HTTPS).
Stos technologiczny: Python (Flask), Tesseract OCR, Docker, Nginx, JavaScript (podgląd plików).
System gotowy do integracji w projektach B2B lub do użycia jako samodzielna usługa.