Prognozowanie cen kryptowalut za pomocą sieci neuronowych
Python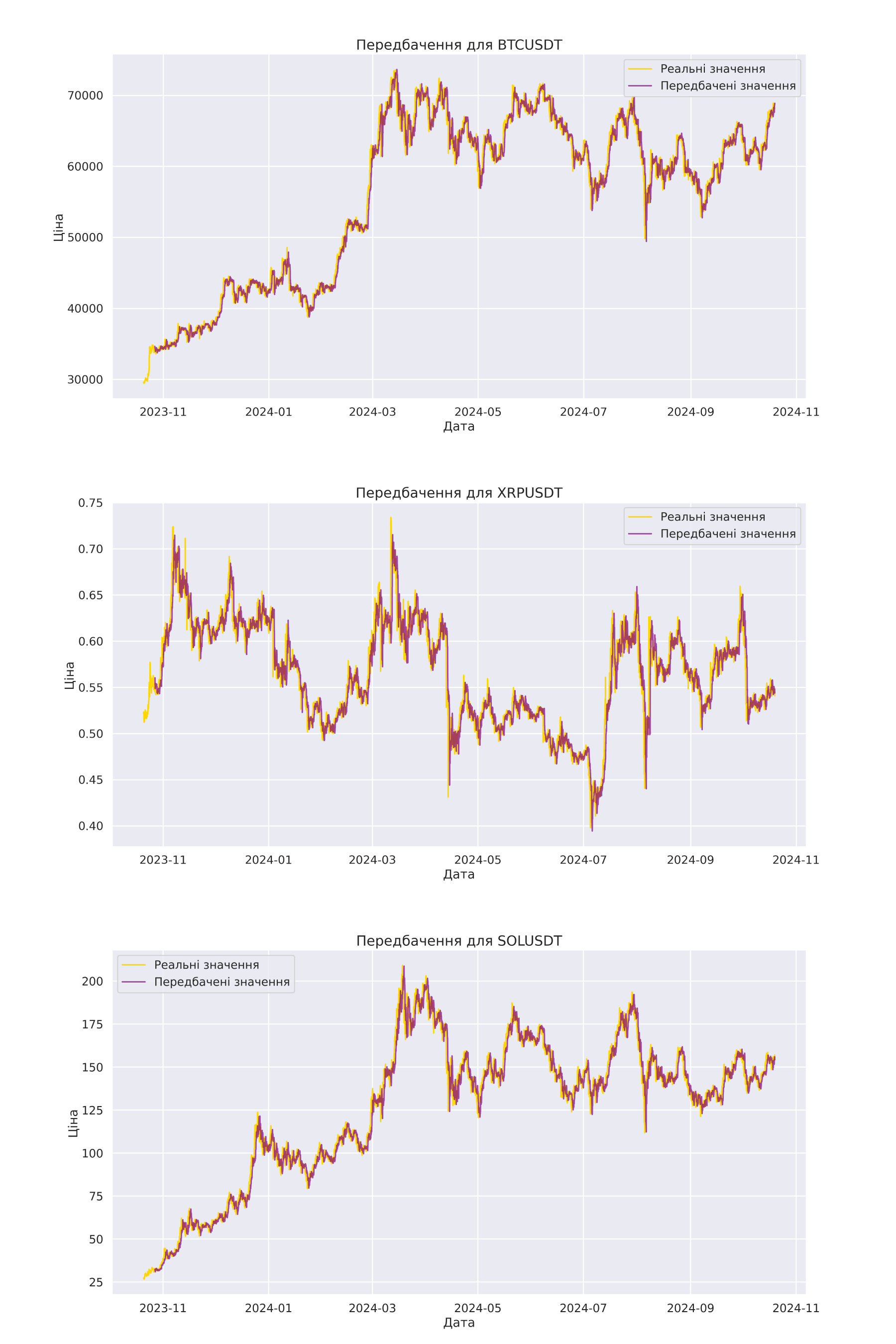
Wykorzystane biblioteki:
● aiohttp: do zbierania danych historycznych z Binance API
● PyTorch i PyTorch Lightning: do budowy i trenowania modelu
● pandas, numpy: do pracy z szeregami czasowymi, przygotowania i analizy danych
● seaborn, matplotlib: do wizualizacji danych
● DeepSpeed: do optymalizacji uczenia na dużych zbiorach danych
Główne zadania:
● Zbieranie i normalizacja danych, przygotowanie szeregów czasowych dla kryptowalut
● Budowa i trenowanie zoptymalizowanego modelu DeepAR
● Prognozowanie danych za pomocą stworzonego modelu
● Wizualizacja wyników w celu oceny jakości modelu
Proces realizacji:
1. Przygotowanie danych:
Funkcja get_klines_for_train pobiera dane historyczne o zmianach cen w określonym interwale czasowym oraz oblicza wskaźniki techniczne, takie jak RSI, EMA i inne. Następnie dane są zapisywane do pliku CSV do dalszego wykorzystania. Do trenowania modelu wybrano parę walutową JUP/USDT z interwałem 1 godzina, a do testowania pary BTC/USDT, SOL/USDT i XRP/USDT. Chociaż liczba danych była ograniczona, wystarczyło to do efektywnego uczenia.
W głównym module dane są ładowane z pliku CSV, a zbiór danych jest normalizowany za pomocą specjalnie zaimplementowanej metody MinMax.
2. Tworzenie i trenowanie modelu DeepAR:
Model oparty jest na dostosowanej wersji DeepAREnhanced, która jest zoptymalizowaną wersją klasycznej DeepAR. Aby zwiększyć dokładność na dużych szeregach czasowych, wprowadzono specjalną wersję ScaledNormalLoss, która poprawia funkcję strat. Trenowanie odbywało się z użyciem DeepSpeed w celu przyspieszenia procesu oraz EarlyStopping, aby uniknąć przeuczenia.
3. Prognozowanie i wizualizacja:
Po treningu model był używany do prognozowania cen na zestawie testowym. Wyniki prognozowania były porównywane z rzeczywistymi wartościami za pomocą funkcji plot_comparison(), która wizualnie demonstruje dokładność modelu i jego skuteczność w przewidywaniu przyszłych trendów.
Etykiety:
#python #pytorch #binance #binance.com #datascience #cryptocurrency #криптовалюты #ai
● aiohttp: do zbierania danych historycznych z Binance API
● PyTorch i PyTorch Lightning: do budowy i trenowania modelu
● pandas, numpy: do pracy z szeregami czasowymi, przygotowania i analizy danych
● seaborn, matplotlib: do wizualizacji danych
● DeepSpeed: do optymalizacji uczenia na dużych zbiorach danych
Główne zadania:
● Zbieranie i normalizacja danych, przygotowanie szeregów czasowych dla kryptowalut
● Budowa i trenowanie zoptymalizowanego modelu DeepAR
● Prognozowanie danych za pomocą stworzonego modelu
● Wizualizacja wyników w celu oceny jakości modelu
Proces realizacji:
1. Przygotowanie danych:
Funkcja get_klines_for_train pobiera dane historyczne o zmianach cen w określonym interwale czasowym oraz oblicza wskaźniki techniczne, takie jak RSI, EMA i inne. Następnie dane są zapisywane do pliku CSV do dalszego wykorzystania. Do trenowania modelu wybrano parę walutową JUP/USDT z interwałem 1 godzina, a do testowania pary BTC/USDT, SOL/USDT i XRP/USDT. Chociaż liczba danych była ograniczona, wystarczyło to do efektywnego uczenia.
W głównym module dane są ładowane z pliku CSV, a zbiór danych jest normalizowany za pomocą specjalnie zaimplementowanej metody MinMax.
2. Tworzenie i trenowanie modelu DeepAR:
Model oparty jest na dostosowanej wersji DeepAREnhanced, która jest zoptymalizowaną wersją klasycznej DeepAR. Aby zwiększyć dokładność na dużych szeregach czasowych, wprowadzono specjalną wersję ScaledNormalLoss, która poprawia funkcję strat. Trenowanie odbywało się z użyciem DeepSpeed w celu przyspieszenia procesu oraz EarlyStopping, aby uniknąć przeuczenia.
3. Prognozowanie i wizualizacja:
Po treningu model był używany do prognozowania cen na zestawie testowym. Wyniki prognozowania były porównywane z rzeczywistymi wartościami za pomocą funkcji plot_comparison(), która wizualnie demonstruje dokładność modelu i jego skuteczność w przewidywaniu przyszłych trendów.
Etykiety:
#python #pytorch #binance #binance.com #datascience #cryptocurrency #криптовалюты #ai