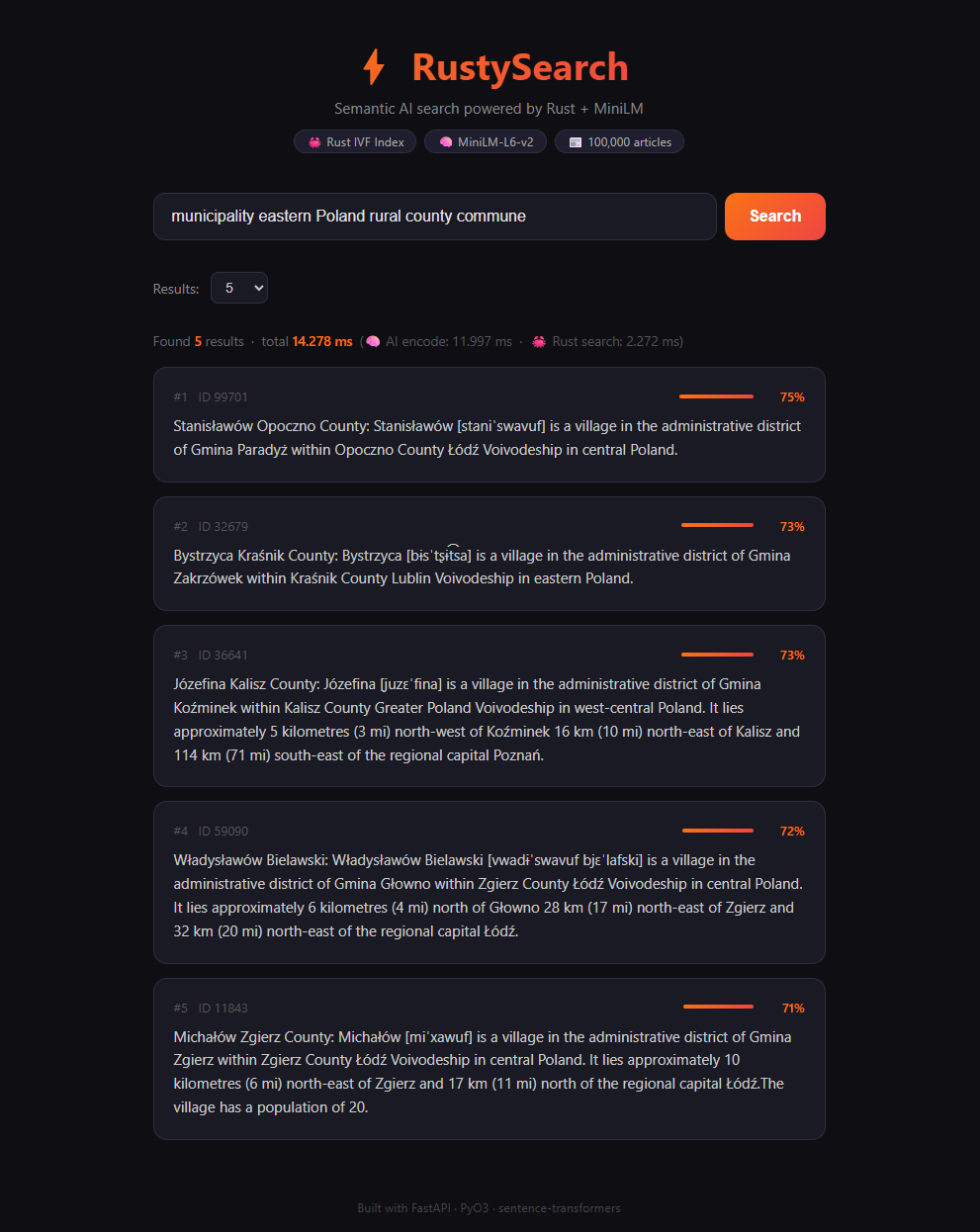
RustySearch — to rdzeń obliczeniowy napisany w Rust, który przekształca dowolną bazę danych w inteligentny system odpowiedzi. Zamiast klasycznego wyszukiwania opartego na dopasowaniu słów, system rozumie semantykę tekstu, łącząc modele uczenia maszynowego z szybkością niskopoziomowego języka programowania.
Architektura: od tekstu do wektora
Proces wyszukiwania oparty jest na hybrydowym podejściu i składa się z dwóch etapów:
1. AI-wektoryzacja: Sieć neuronowa (oparta na architekturze Transformer) analizuje wejściowe zapytanie i przekształca je w wielowymiarowy wektor (embedding), uchwycając treść i kontekst.
2. Rust-rdzeń: Algorytm wyszukiwania natychmiast oblicza odległość między wektorami i znajduje najbardziej relewantne wyniki w dużych zbiorach danych.
Innowacja techniczna pod maską
Aby uniknąć wolnego liniowego wyszukiwania, w systemie zaimplementowano Inverted File Index (IVF). Dzięki algorytmowi klasteryzacji K-means przestrzeń wektorowa dzielona jest na komórki Voronoi. Dzięki temu silnik nie sprawdza każdego rekordu w bazie, lecz od razu zwraca się do odpowiedniego klastra, co radykalnie przyspiesza wydajność.
Kluczowe zalety systemu
Wydajność: Czas wyszukiwania wśród setek tysięcy rekordów wynosi mniej niż 2 ms — to 30–50 razy szybciej niż podobne skrypty w Pythonie.
Uniwersalność: Rdzeń działa z dowolnymi źródłami danych, od lokalnych plików (JSON/CSV) po przemysłowe bazy (SQL/NoSQL).
Elastyczność ustawień: Architektura w Rust pozwala łatwo dostosować system do specyficznych zadań biznesowych, zmieniać metryki podobieństwa lub integrować go w złożone rozproszone sieci.
Autonomia: Wydajność na poziomie chmurowych baz danych wektorowych (np. Pinecone), ale z pełną kontrolą nad własnymi danymi i bez miesięcznych subskrypcji.
Obszary zastosowania
RAG-systemy (Retrieval-Augmented Generation): Tworzenie inteligentnych asystentów, którzy odpowiadają na pytania na podstawie wewnętrznej dokumentacji.
E-commerce: Dokładne systemy rekomendacyjne, które oferują produkty na podstawie opisowych lub nietypowych zapytań użytkowników.
Analiza Big Data: Wyszukiwanie podobnych wzorców, duplikatów lub anomalii w dużych zbiorach danych.
Efektywność w liczbach
Złożoność algorytmiczna: Zredukowana z liniowej O(N) do subliniowej O(√N).
Dokładność (Recall): 90–98% przy zachowaniu wysokiej prędkości przetwarzania.
Czas odpowiedzi: Średnie opóźnienie zapytania wyszukującego — 1.4 ms.
#AI #UczenieMaszynowe #WyszukiwanieSemantyczne #nlp #RAG #wysokieobciążenie #NiskaLatencja #OptymalizacjaWydajności #Algorytmy #ProgramowanieSystemowe #Backend #Rust
Architektura: od tekstu do wektora
Proces wyszukiwania oparty jest na hybrydowym podejściu i składa się z dwóch etapów:
1. AI-wektoryzacja: Sieć neuronowa (oparta na architekturze Transformer) analizuje wejściowe zapytanie i przekształca je w wielowymiarowy wektor (embedding), uchwycając treść i kontekst.
2. Rust-rdzeń: Algorytm wyszukiwania natychmiast oblicza odległość między wektorami i znajduje najbardziej relewantne wyniki w dużych zbiorach danych.
Innowacja techniczna pod maską
Aby uniknąć wolnego liniowego wyszukiwania, w systemie zaimplementowano Inverted File Index (IVF). Dzięki algorytmowi klasteryzacji K-means przestrzeń wektorowa dzielona jest na komórki Voronoi. Dzięki temu silnik nie sprawdza każdego rekordu w bazie, lecz od razu zwraca się do odpowiedniego klastra, co radykalnie przyspiesza wydajność.
Kluczowe zalety systemu
Wydajność: Czas wyszukiwania wśród setek tysięcy rekordów wynosi mniej niż 2 ms — to 30–50 razy szybciej niż podobne skrypty w Pythonie.
Uniwersalność: Rdzeń działa z dowolnymi źródłami danych, od lokalnych plików (JSON/CSV) po przemysłowe bazy (SQL/NoSQL).
Elastyczność ustawień: Architektura w Rust pozwala łatwo dostosować system do specyficznych zadań biznesowych, zmieniać metryki podobieństwa lub integrować go w złożone rozproszone sieci.
Autonomia: Wydajność na poziomie chmurowych baz danych wektorowych (np. Pinecone), ale z pełną kontrolą nad własnymi danymi i bez miesięcznych subskrypcji.
Obszary zastosowania
RAG-systemy (Retrieval-Augmented Generation): Tworzenie inteligentnych asystentów, którzy odpowiadają na pytania na podstawie wewnętrznej dokumentacji.
E-commerce: Dokładne systemy rekomendacyjne, które oferują produkty na podstawie opisowych lub nietypowych zapytań użytkowników.
Analiza Big Data: Wyszukiwanie podobnych wzorców, duplikatów lub anomalii w dużych zbiorach danych.
Efektywność w liczbach
Złożoność algorytmiczna: Zredukowana z liniowej O(N) do subliniowej O(√N).
Dokładność (Recall): 90–98% przy zachowaniu wysokiej prędkości przetwarzania.
Czas odpowiedzi: Średnie opóźnienie zapytania wyszukującego — 1.4 ms.
#AI #UczenieMaszynowe #WyszukiwanieSemantyczne #nlp #RAG #wysokieobciążenie #NiskaLatencja #OptymalizacjaWydajności #Algorytmy #ProgramowanieSystemowe #Backend #Rust