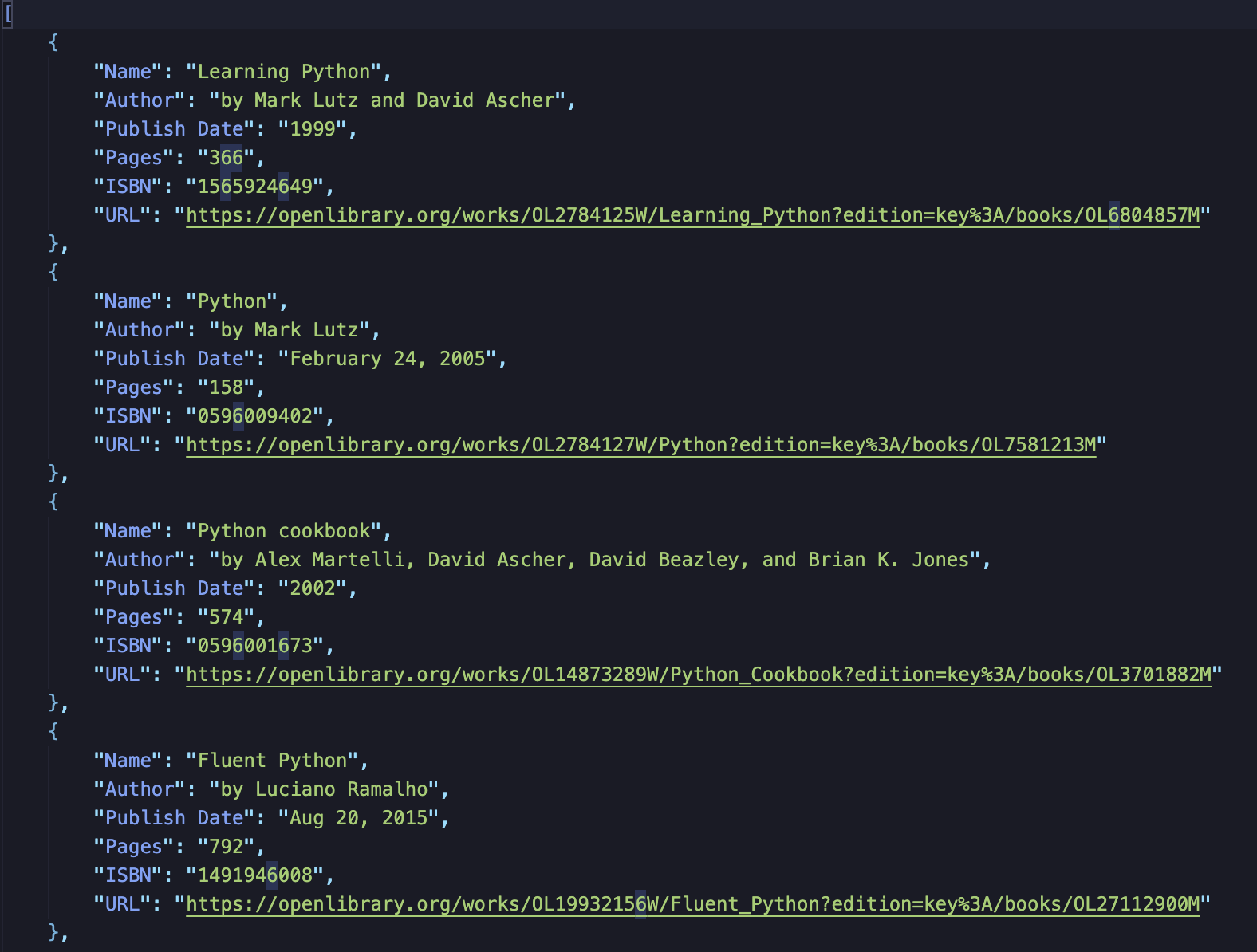
Opracowałem parser w Pythonie dla katalogu Open Library, przetwarzając ponad 300 stron i ponad 6000 rekordów książek. Zrealizowałem niezawodne przetwarzanie błędów z logiką ponownych prób i weryfikacją danych. Eksportuje czyste, uporządkowane dane w formatach JSON/CSV z śledzeniem postępu dla programów badawczych i analityki biznesowej.