Parsowanie zabezpieczonej strony SPA, Ominięcie Cloudflare i systemu antybotowego
Parsowanie danych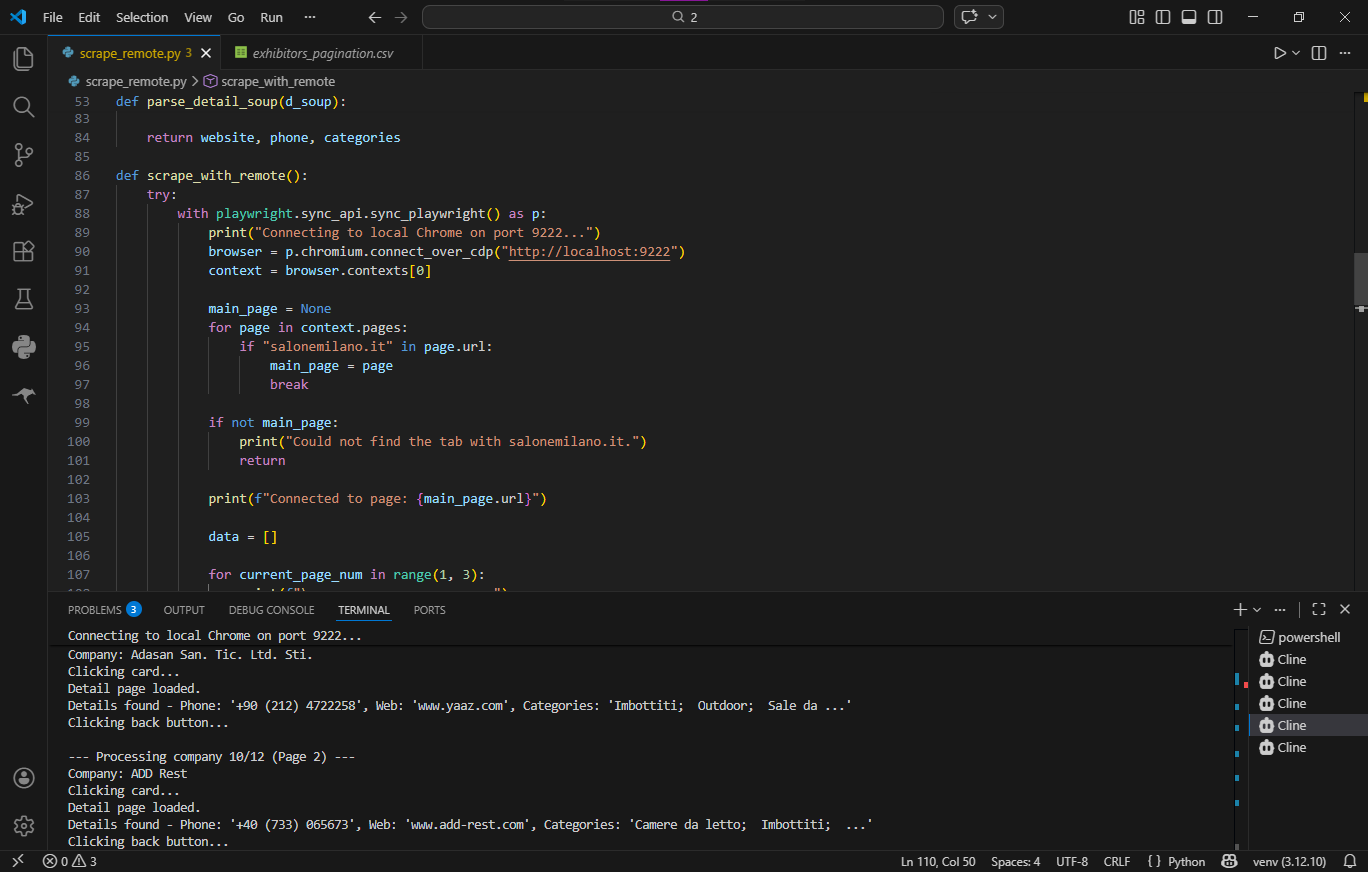
Cel: Zgromadzić 100% dokładne dane o ponad 1000 wystawcach (nazwa, kraj, numer stoiska, ukryte e-maile i telefony, kategorie) z oficjalnej strony Salone del Mobile.
Główne wyzwania:
Agresywna ochrona antybotowa (Cloudflare): Standardowe zapytania (requests/httpx) zwracały 403 Forbidden. Zwykłe przeglądarki headless (Selenium, Playwright) oraz nawet frameworki takie jak undetected-chromedriver były natychmiast blokowane.
Skomplikowana architektura SPA (React / Next.js): Na stronie nie było standardowych linków HTML. Cała nawigacja odbywała się wyłącznie przez obsługiwacze zdarzeń React (onClick), co uniemożliwiało tradycyjne zbieranie URL. Ponadto dane kontaktowe były ukryte w nie-semantycznych tagach.
Moje rozwiązanie:
Aby osiągnąć idealną dokładność i obejść ochronę, opracowałem niestandardowe podejście hybrydowe:
Połączenie przez Chrome DevTools Protocol (CDP): Zamiast uruchamiać nową instancję zautomatyzowanej przeglądarki, mój skrypt używał Playwright do połączenia z już uruchomioną, "żywą" sesją Google Chrome (http://localhost:9222). To dało 100% "czynnik zaufania" legalnego użytkownika (razem z rzeczywistymi ciasteczkami, historią i odciskami Canvas). Cloudflare zostało ominięte bez żadnej rozwiązanej captchy.
Inteligentna nawigacja: Skrypt wizualnie naśladował zachowanie człowieka — przechwytywał dynamiczne lokalizatory, fizycznie klikał myszką, aby wywołać stany React i używał wewnętrznego routera strony, aby wrócić do listy, zachowując paginację.
Parsowanie HTML: Przechwycony stan strony był przetwarzany przez BeautifulSoup oraz złożone wyrażenia regularne (Regex) w celu dokładnego wyodrębnienia "zepsutych" lub źle sformatowanych linków oraz numerów telefonów.
Wykorzystane technologie:
Python 3.12
Playwright (Sync API): interakcja z DOM i połączenie przez CDP.
BeautifulSoup4 & Regex: dokładne wyszukiwanie i wyodrębnianie danych.
Pandas: strukturyzacja i eksport danych do czystego CSV (UTF-8 z BOM) oraz Excel.
Wynik:
Skrypt całkowicie autonomicznie zgromadził i idealnie sformatował dane ponad 1200 firm. Stworzona architektura pozwala na skalowanie parsowania bez ryzyka uzyskania bana po IP.
Główne wyzwania:
Agresywna ochrona antybotowa (Cloudflare): Standardowe zapytania (requests/httpx) zwracały 403 Forbidden. Zwykłe przeglądarki headless (Selenium, Playwright) oraz nawet frameworki takie jak undetected-chromedriver były natychmiast blokowane.
Skomplikowana architektura SPA (React / Next.js): Na stronie nie było standardowych linków HTML. Cała nawigacja odbywała się wyłącznie przez obsługiwacze zdarzeń React (onClick), co uniemożliwiało tradycyjne zbieranie URL. Ponadto dane kontaktowe były ukryte w nie-semantycznych tagach.
Moje rozwiązanie:
Aby osiągnąć idealną dokładność i obejść ochronę, opracowałem niestandardowe podejście hybrydowe:
Połączenie przez Chrome DevTools Protocol (CDP): Zamiast uruchamiać nową instancję zautomatyzowanej przeglądarki, mój skrypt używał Playwright do połączenia z już uruchomioną, "żywą" sesją Google Chrome (http://localhost:9222). To dało 100% "czynnik zaufania" legalnego użytkownika (razem z rzeczywistymi ciasteczkami, historią i odciskami Canvas). Cloudflare zostało ominięte bez żadnej rozwiązanej captchy.
Inteligentna nawigacja: Skrypt wizualnie naśladował zachowanie człowieka — przechwytywał dynamiczne lokalizatory, fizycznie klikał myszką, aby wywołać stany React i używał wewnętrznego routera strony, aby wrócić do listy, zachowując paginację.
Parsowanie HTML: Przechwycony stan strony był przetwarzany przez BeautifulSoup oraz złożone wyrażenia regularne (Regex) w celu dokładnego wyodrębnienia "zepsutych" lub źle sformatowanych linków oraz numerów telefonów.
Wykorzystane technologie:
Python 3.12
Playwright (Sync API): interakcja z DOM i połączenie przez CDP.
BeautifulSoup4 & Regex: dokładne wyszukiwanie i wyodrębnianie danych.
Pandas: strukturyzacja i eksport danych do czystego CSV (UTF-8 z BOM) oraz Excel.
Wynik:
Skrypt całkowicie autonomicznie zgromadził i idealnie sformatował dane ponad 1200 firm. Stworzona architektura pozwala na skalowanie parsowania bez ryzyka uzyskania bana po IP.