Trwała Pamięć Wektorowa dla Kodu Claude: Serwer MCP Open-Source
AI i uczenie maszynowe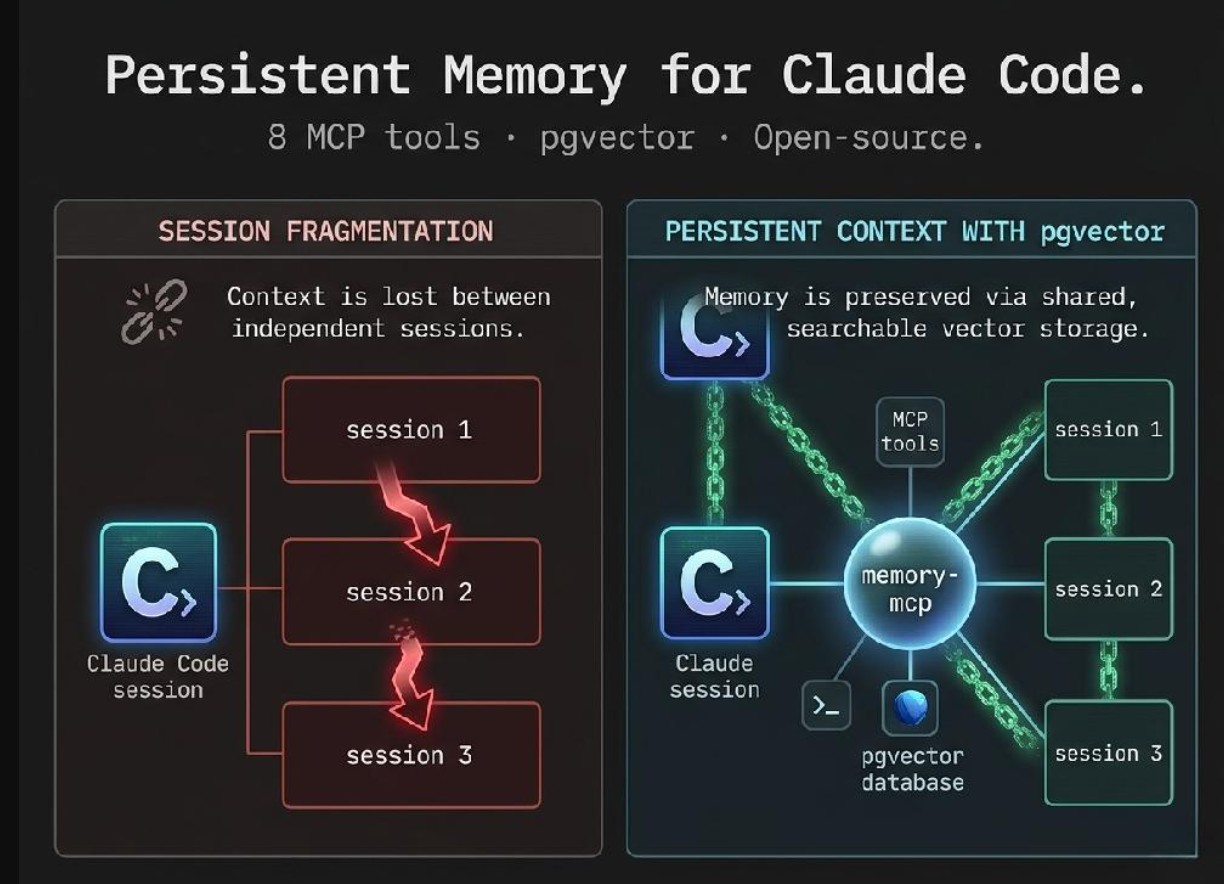
Sytuacja
Claude Code to potężny asystent kodowania AI, ale jest zaprojektowany jako bezstanowy. Każda nowa sesja zaczyna się bez wiedzy o przeszłych decyzjach, błędach czy architekturze. W rzeczywistej pracy produkcyjnej prowadzi to do ciągłej powtarzalności, utraty kontekstu i wolniejszego rozwoju.
Problem
Podstawowy problem: asystent AI pomagający w budowie projektu nie ma pamięci o jego budowie. Odkrywałem te same błędy, ponownie wyjaśniałem tę samą architekturę i traciłem decyzje podjęte w zeszłym tygodniu. Problem wtórny: powtarzające się wzorce w projektach (jak "ustawiliśmy Supabase w ten dokładny sposób 4 razy") pozostawały ukryte w pamięciach sesji zamiast stać się wielokrotnego użytku, udokumentowanymi umiejętnościami.
Rozwiązanie
Zbudowałem memory-mcp, serwer MCP open-source, który daje Claude Code długoterminową pamięć semantyczną. Udostępnia 8 narzędzi: 4 podstawowe narzędzia pamięci (zapamiętaj, przypomnij, zapomnij, status_projektu) oraz 4 narzędzia wzorców umiejętności, które śledzą powtarzające się wzorce pracy i ujawniają kandydatów do formalizacji po ich zobaczeniu 3+ razy.
Pamięci są przechowywane jako osadzenia wektorowe o wymiarach 1536 (OpenAI text-embedding-3-small) w Supabase PostgreSQL z pgvector. Wyszukiwanie odbywa się za pomocą wyszukiwania podobieństwa cosinusowego przez funkcję RPC Postgres z filtrowaniem na poziomie SQL (próg, projekt, typ, data, wygaśnięcie) w jednej rundzie. Odpowiedzi przypomnienia są ograniczone do ~2000 tokenów, aby chronić okno kontekstowe Claude'a.
Serwer działa jako bezstanowy kontener Docker na porcie 3101 za pomocą Express + transportu HTTP Streamable, więc wiele sesji Claude Code dzieli jedną zawsze aktywną instancję. Dostępny jest również tryb transportu stdio do bezpośredniej integracji z natywnym binarnym. Pamięci nigdy nie są trwale usuwane: zapomnienie to miękkie usunięcie przez expires_at, a każde zapytanie filtruje na podstawie statusu aktywnej pamięci.
Stos technologiczny: Node.js 20, TypeScript 5 (ścisły), Express 5, @ modelcontextprotocol/sdk, OpenAI API (text-embedding-3-small), Supabase PostgreSQL, pgvector, indeksy IVFFlat, walidacja Zod, Vitest, Docker Compose.
Wyniki
- 8 narzędzi MCP dostarczonych i przetestowanych end-to-end przez HTTP
- 125 testów jednostkowych z klientami Supabase i OpenAI w pełni zamockowanych
- ~2600 linii TypeScript w 16 plikach źródłowych, 11 commitów w ciągu 11 dni
- 2 tabele, 3 funkcje RPC z filtrowaniem na poziomie SQL przed LIMIT dla poprawności
- Działanie w produkcji jako zawsze aktywna usługa Docker, używana codziennie z rzeczywistymi sesjami Claude Code
- Opublikowane jako open-source na GitHubie z pełną dokumentacją konfiguracji, Docker Compose i przewodnikiem rozwiązywania problemów obejmującym 4 udokumentowane tryby awarii
Kluczowe decyzje inżynieryjne
1. Empiryczne progi podobieństwa. text-embedding-3-small produkuje niższe wyniki cosinusowe niż sugerują dokumenty (niemal identyczne teksty mają wyniki 0.78–0.84). Obniżyłem próg przypomnienia do 0.25 i deduplikacji do 0.75 na podstawie rzeczywistych pomiarów, udokumentowałem tę zasadę dla przyszłych funkcji.
2. Filtrowanie dat na poziomie SQL. Filtr since_days początkowo działał po stronie klienta po LIMIT, co cicho pomijało niedawne pamięci sklasyfikowane poniżej top N. Przeniesienie go do klauzuli WHERE przed LIMIT gwarantuje poprawność niezależnie od objętości danych.
3. Opisy narzędzi jako instrukcje wykonawcze. Opisy narzędzi zostały przepisane z "co robią" na "kiedy je wywołać" (np. "Wywołaj przed rozpoczęciem niebanalnej pracy"), dzięki czemu narzędzia działają poprawnie bez potrzeby utrzymywania CLAUDE.md.
4. Obejście OAuth dla natywnego binarnego Claude Code. Binarne blokuje połączenia HTTP MCP, dopóki odkrycie OAuth się nie zakończy. Dodanie statycznego tokena Bearer do konfiguracji MCP całkowicie pomija odkrycie (token jest arbitralny i nigdy nie jest weryfikowany po stronie serwera).
Dostępne na GitHubie
Pełne źródło, instrukcje konfiguracji i dokumentacja architektury opublikowane dla deweloperów, którzy chcą replikować lub rozszerzać system.
Claude Code to potężny asystent kodowania AI, ale jest zaprojektowany jako bezstanowy. Każda nowa sesja zaczyna się bez wiedzy o przeszłych decyzjach, błędach czy architekturze. W rzeczywistej pracy produkcyjnej prowadzi to do ciągłej powtarzalności, utraty kontekstu i wolniejszego rozwoju.
Problem
Podstawowy problem: asystent AI pomagający w budowie projektu nie ma pamięci o jego budowie. Odkrywałem te same błędy, ponownie wyjaśniałem tę samą architekturę i traciłem decyzje podjęte w zeszłym tygodniu. Problem wtórny: powtarzające się wzorce w projektach (jak "ustawiliśmy Supabase w ten dokładny sposób 4 razy") pozostawały ukryte w pamięciach sesji zamiast stać się wielokrotnego użytku, udokumentowanymi umiejętnościami.
Rozwiązanie
Zbudowałem memory-mcp, serwer MCP open-source, który daje Claude Code długoterminową pamięć semantyczną. Udostępnia 8 narzędzi: 4 podstawowe narzędzia pamięci (zapamiętaj, przypomnij, zapomnij, status_projektu) oraz 4 narzędzia wzorców umiejętności, które śledzą powtarzające się wzorce pracy i ujawniają kandydatów do formalizacji po ich zobaczeniu 3+ razy.
Pamięci są przechowywane jako osadzenia wektorowe o wymiarach 1536 (OpenAI text-embedding-3-small) w Supabase PostgreSQL z pgvector. Wyszukiwanie odbywa się za pomocą wyszukiwania podobieństwa cosinusowego przez funkcję RPC Postgres z filtrowaniem na poziomie SQL (próg, projekt, typ, data, wygaśnięcie) w jednej rundzie. Odpowiedzi przypomnienia są ograniczone do ~2000 tokenów, aby chronić okno kontekstowe Claude'a.
Serwer działa jako bezstanowy kontener Docker na porcie 3101 za pomocą Express + transportu HTTP Streamable, więc wiele sesji Claude Code dzieli jedną zawsze aktywną instancję. Dostępny jest również tryb transportu stdio do bezpośredniej integracji z natywnym binarnym. Pamięci nigdy nie są trwale usuwane: zapomnienie to miękkie usunięcie przez expires_at, a każde zapytanie filtruje na podstawie statusu aktywnej pamięci.
Stos technologiczny: Node.js 20, TypeScript 5 (ścisły), Express 5, @ modelcontextprotocol/sdk, OpenAI API (text-embedding-3-small), Supabase PostgreSQL, pgvector, indeksy IVFFlat, walidacja Zod, Vitest, Docker Compose.
Wyniki
- 8 narzędzi MCP dostarczonych i przetestowanych end-to-end przez HTTP
- 125 testów jednostkowych z klientami Supabase i OpenAI w pełni zamockowanych
- ~2600 linii TypeScript w 16 plikach źródłowych, 11 commitów w ciągu 11 dni
- 2 tabele, 3 funkcje RPC z filtrowaniem na poziomie SQL przed LIMIT dla poprawności
- Działanie w produkcji jako zawsze aktywna usługa Docker, używana codziennie z rzeczywistymi sesjami Claude Code
- Opublikowane jako open-source na GitHubie z pełną dokumentacją konfiguracji, Docker Compose i przewodnikiem rozwiązywania problemów obejmującym 4 udokumentowane tryby awarii
Kluczowe decyzje inżynieryjne
1. Empiryczne progi podobieństwa. text-embedding-3-small produkuje niższe wyniki cosinusowe niż sugerują dokumenty (niemal identyczne teksty mają wyniki 0.78–0.84). Obniżyłem próg przypomnienia do 0.25 i deduplikacji do 0.75 na podstawie rzeczywistych pomiarów, udokumentowałem tę zasadę dla przyszłych funkcji.
2. Filtrowanie dat na poziomie SQL. Filtr since_days początkowo działał po stronie klienta po LIMIT, co cicho pomijało niedawne pamięci sklasyfikowane poniżej top N. Przeniesienie go do klauzuli WHERE przed LIMIT gwarantuje poprawność niezależnie od objętości danych.
3. Opisy narzędzi jako instrukcje wykonawcze. Opisy narzędzi zostały przepisane z "co robią" na "kiedy je wywołać" (np. "Wywołaj przed rozpoczęciem niebanalnej pracy"), dzięki czemu narzędzia działają poprawnie bez potrzeby utrzymywania CLAUDE.md.
4. Obejście OAuth dla natywnego binarnego Claude Code. Binarne blokuje połączenia HTTP MCP, dopóki odkrycie OAuth się nie zakończy. Dodanie statycznego tokena Bearer do konfiguracji MCP całkowicie pomija odkrycie (token jest arbitralny i nigdy nie jest weryfikowany po stronie serwera).
Dostępne na GitHubie
Pełne źródło, instrukcje konfiguracji i dokumentacja architektury opublikowane dla deweloperów, którzy chcą replikować lub rozszerzać system.