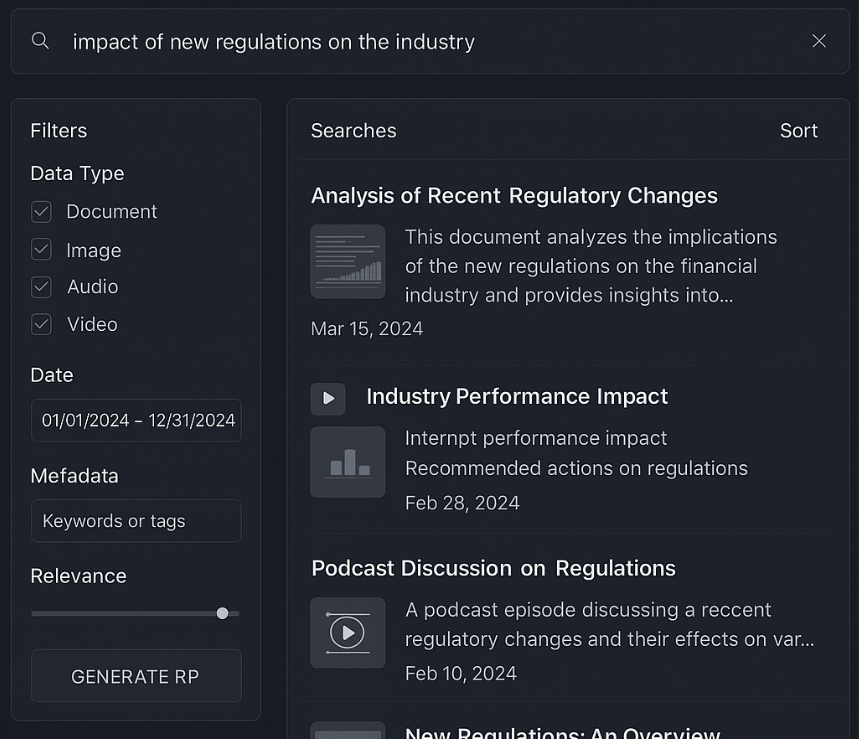
System analityki niestrukturalnych danych (tekstów i mediów), która realizuje podejście RAG w celu zapewnienia wyszukiwania semantycznego oraz tworzenia ustrukturyzowanych raportów na podstawie przefiltrowanych wyników. Interfejs umożliwia użytkownikom przeprowadzanie głębokiego wyszukiwania w bazie dokumentów tekstowych, obrazów, wideo i audio z uwzględnieniem różnych filtrów: typ danych, zakres dat, metadane.
Po wyszukiwaniu użytkownik ma możliwość tworzenia spersonalizowanych raportów analitycznych, generowanych za pomocą modeli LLM (w tym lokalnych lub API) na podstawie wybranego kontentu.
Kluczowe funkcje:
* Wyszukiwanie semantyczne za pomocą RAG (połączenie wyszukiwania wektorowego i generowania odpowiedzi),
* Zintegrowane filtry do precyzowania wyników (typ, data, metadane, trafność),
* Obsługa wielu typów kontentu: dokumenty, audio, wideo, obrazy,
* Generowanie raportów lokalnymi modelami LLM do przetwarzania danych prywatnych.
Technologiczny stos:
* Python — główna logika, przetwarzanie danych, integracja z LLM,
* Elasticsearch — przechowywanie i wyszukiwanie semantyczne danych wektorowych,
* OpenAI — wykorzystanie modeli GPT do budowy pipeline'ów RAG,
* Docker, Git, Linux — platforma, wdrożenie, CI/CD.
Moja rola:
Architektura systemu, implementacja mechanizmu indeksowania i wyszukiwania semantycznego, integracja API OpenAI i lokalnych LLM, konfiguracja środowiska wdrożeniowego z użyciem Dockera, automatyzacja tworzenia raportów.
#python #elasticsearch #openai #llama #docker #git
Po wyszukiwaniu użytkownik ma możliwość tworzenia spersonalizowanych raportów analitycznych, generowanych za pomocą modeli LLM (w tym lokalnych lub API) na podstawie wybranego kontentu.
Kluczowe funkcje:
* Wyszukiwanie semantyczne za pomocą RAG (połączenie wyszukiwania wektorowego i generowania odpowiedzi),
* Zintegrowane filtry do precyzowania wyników (typ, data, metadane, trafność),
* Obsługa wielu typów kontentu: dokumenty, audio, wideo, obrazy,
* Generowanie raportów lokalnymi modelami LLM do przetwarzania danych prywatnych.
Technologiczny stos:
* Python — główna logika, przetwarzanie danych, integracja z LLM,
* Elasticsearch — przechowywanie i wyszukiwanie semantyczne danych wektorowych,
* OpenAI — wykorzystanie modeli GPT do budowy pipeline'ów RAG,
* Docker, Git, Linux — platforma, wdrożenie, CI/CD.
Moja rola:
Architektura systemu, implementacja mechanizmu indeksowania i wyszukiwania semantycznego, integracja API OpenAI i lokalnych LLM, konfiguracja środowiska wdrożeniowego z użyciem Dockera, automatyzacja tworzenia raportów.
#python #elasticsearch #openai #llama #docker #git