Smart Chunker: przygotowanie dokumentów dla RAG i baz wektorowych
AI i uczenie maszynowe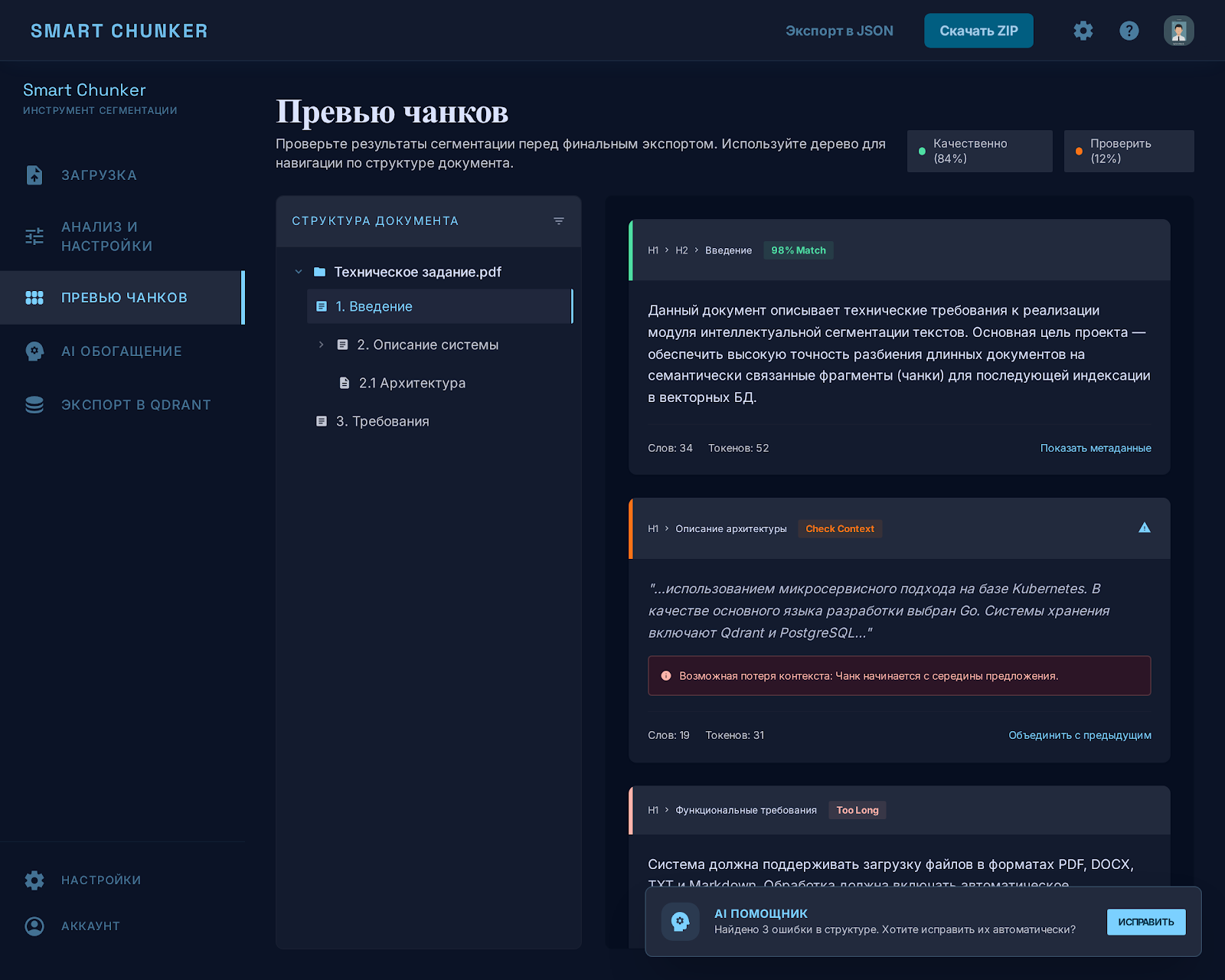
AI-agent odpowiada tak dobrze, jak dobrze przygotowany jest jego kontekst. Aby przygotować dużą bazę wiedzy do RAG, stworzyłem Smart Chunker: tnie Markdown na sensowne kawałki, pokazuje problematyczne miejsca i ładuje gotowe dane do bazy wektorowej. Przed wyszukiwaniem wiedza jest przekształcana do normalnej postaci, bez urwanych fragmentów i duplikatów.
Co w środku:
- Deterministyczne jądro: analiza Markdown w drzewo nagłówków H1-H3 i 7 zasad chunkowania, bez nakładania się.
- Automatyczny dobór rozmiarów kawałków przez przeszukiwanie siatki do 2500 kombinacji.
- Kontrola jakości widoczna w interfejsie: problematyczne kawałki są podświetlane, system podpowiada, co poprawić.
- Warstwa AI: architekt proponuje schemat metadanych, agent wzbogaca kawałki pakietami, wynik przechodzi walidację.
- Ładowanie do Qdrant: gęste wektory przez embeddings, rzadkie przez lokalny BM25, aktualizacja przez Smart Match. 20 punktów API.
Klucze API żyją tylko w przeglądarce i nie są przechowywane na serwerze. Podstawowe chunkowanie działa również bez zewnętrznych modeli.
#Python #RAG #Qdrant #FastAPI #AI #VectorDB #LLM #NLP #VanillaJS #OpenAI #Anthropic #BM25 #SSE
Co w środku:
- Deterministyczne jądro: analiza Markdown w drzewo nagłówków H1-H3 i 7 zasad chunkowania, bez nakładania się.
- Automatyczny dobór rozmiarów kawałków przez przeszukiwanie siatki do 2500 kombinacji.
- Kontrola jakości widoczna w interfejsie: problematyczne kawałki są podświetlane, system podpowiada, co poprawić.
- Warstwa AI: architekt proponuje schemat metadanych, agent wzbogaca kawałki pakietami, wynik przechodzi walidację.
- Ładowanie do Qdrant: gęste wektory przez embeddings, rzadkie przez lokalny BM25, aktualizacja przez Smart Match. 20 punktów API.
Klucze API żyją tylko w przeglądarce i nie są przechowywane na serwerze. Podstawowe chunkowanie działa również bez zewnętrznych modeli.
#Python #RAG #Qdrant #FastAPI #AI #VectorDB #LLM #NLP #VanillaJS #OpenAI #Anthropic #BM25 #SSE