Zadanie: Zautomatyzować zbieranie "gorących" leadów (właścicieli firm, przeciwko którym wniesiono pozwy) dla firm prawniczych w USA, wyciągając dane z trudnych stron rządowych i zeskanowanych dokumentów.
Rozwiązanie: Napisano zautomatyzowany parser, który omija podstawowe zabezpieczenia strony sądu (NYSCEF), znajduje potrzebne sprawy, pobiera dokumenty PDF (skargi) i za pomocą analizy tekstu wyciąga imiona właścicieli firm oraz ich adresy.
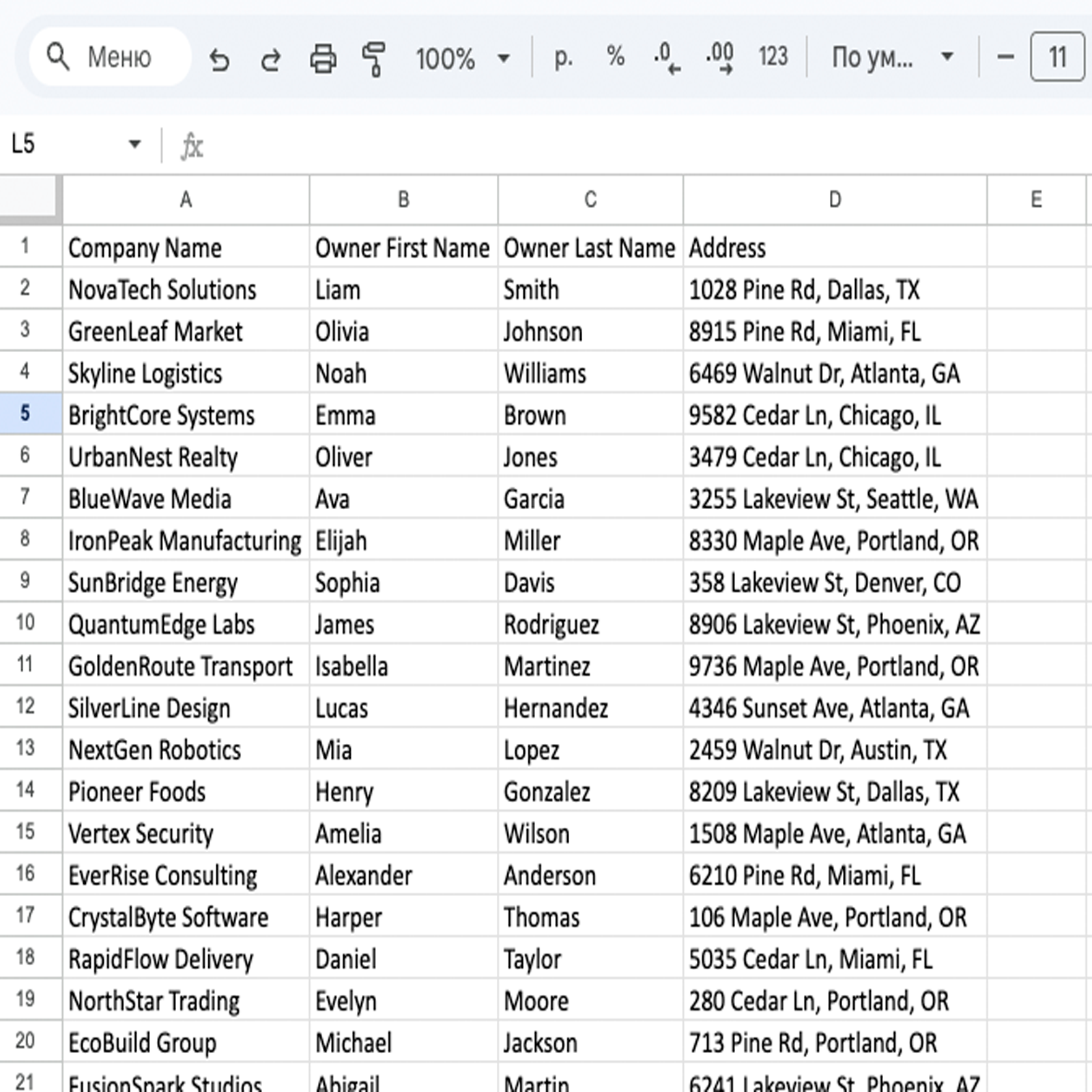
Wynik: Zautomatyzowano generację tabel Excel/CSV z gotowymi kontaktami dla działu sprzedaży, co zastąpiło tygodnie ręcznego poszukiwania.
Stos technologii: Python, Playwright (do omijania blokad i nawigacji), PyMuPDF / pdfplumber (do odczytu PDF), Pandas (do eksportu do tabeli).
Rozwiązanie: Napisano zautomatyzowany parser, który omija podstawowe zabezpieczenia strony sądu (NYSCEF), znajduje potrzebne sprawy, pobiera dokumenty PDF (skargi) i za pomocą analizy tekstu wyciąga imiona właścicieli firm oraz ich adresy.
Wynik: Zautomatyzowano generację tabel Excel/CSV z gotowymi kontaktami dla działu sprzedaży, co zastąpiło tygodnie ręcznego poszukiwania.
Stos technologii: Python, Playwright (do omijania blokad i nawigacji), PyMuPDF / pdfplumber (do odczytu PDF), Pandas (do eksportu do tabeli).