System web scraping i przetwarzania danych
Parsowanie danych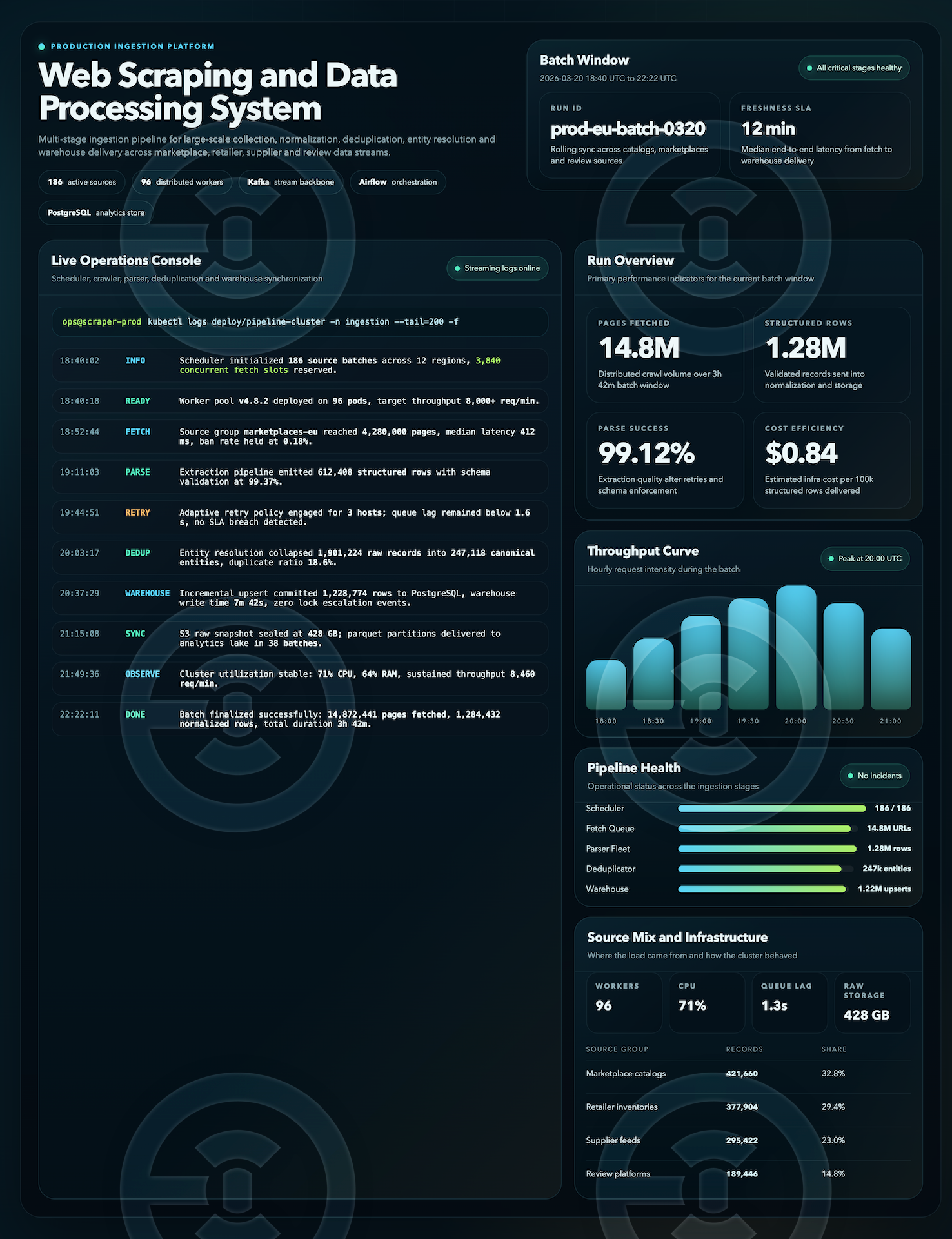
Opracowanie systemu web scrapingu i przetwarzania danych do wieloetapowego zbierania, normalizacji, deduplikacji i przygotowania dużych zbiorów informacji do dalszego wykorzystania w analizie i wewnętrznych procesach biznesowych.
W ramach pracy została przemyślana struktura pipeline'u do zbierania danych do masowego zbierania danych z kilku typów źródeł z dalszym przetwarzaniem przez kolejki, normalizację encji, walidację struktury, deduplikację i przygotowanie do załadunku do magazynu. Szczególną uwagę poświęcono stabilności przetwarzania wsadowego, jakości danych i obserwowalności wszystkich kluczowych etapów pipeline'u.
Co zostało zrealizowane w logice projektu:
— wieloetapowy pipeline zbierania i przetwarzania danych
— rozproszona obróbka źródeł i zadań wsadowych
— normalizacja i deduplikacja rekordów
— kontrola opóźnienia, przepustowości i jakości przetwarzania
— przygotowanie danych do przypadków użycia w magazynie / analizie
— monitorowanie stanu pipeline'u, logów i metryk operacyjnych
Stos i podejście:
web scraping, przetwarzanie danych, pipeline'y wsadowe, normalizacja, deduplikacja, PostgreSQL, Kafka, Airflow, magazynowe zbieranie danych, monitorowanie operacyjne.
Wynik:
uzyskano usystematyzowany system do masowego zbierania i przetwarzania danych z naciskiem na stabilność, jakość danych, przejrzystość procesów pipeline'u i wygodę dalszego skalowania.
W ramach pracy została przemyślana struktura pipeline'u do zbierania danych do masowego zbierania danych z kilku typów źródeł z dalszym przetwarzaniem przez kolejki, normalizację encji, walidację struktury, deduplikację i przygotowanie do załadunku do magazynu. Szczególną uwagę poświęcono stabilności przetwarzania wsadowego, jakości danych i obserwowalności wszystkich kluczowych etapów pipeline'u.
Co zostało zrealizowane w logice projektu:
— wieloetapowy pipeline zbierania i przetwarzania danych
— rozproszona obróbka źródeł i zadań wsadowych
— normalizacja i deduplikacja rekordów
— kontrola opóźnienia, przepustowości i jakości przetwarzania
— przygotowanie danych do przypadków użycia w magazynie / analizie
— monitorowanie stanu pipeline'u, logów i metryk operacyjnych
Stos i podejście:
web scraping, przetwarzanie danych, pipeline'y wsadowe, normalizacja, deduplikacja, PostgreSQL, Kafka, Airflow, magazynowe zbieranie danych, monitorowanie operacyjne.
Wynik:
uzyskano usystematyzowany system do masowego zbierania i przetwarzania danych z naciskiem na stabilność, jakość danych, przejrzystość procesów pipeline'u i wygodę dalszego skalowania.