3M+ Deed Records Processed: Property Research from Days to Minut
AI и машинное обучение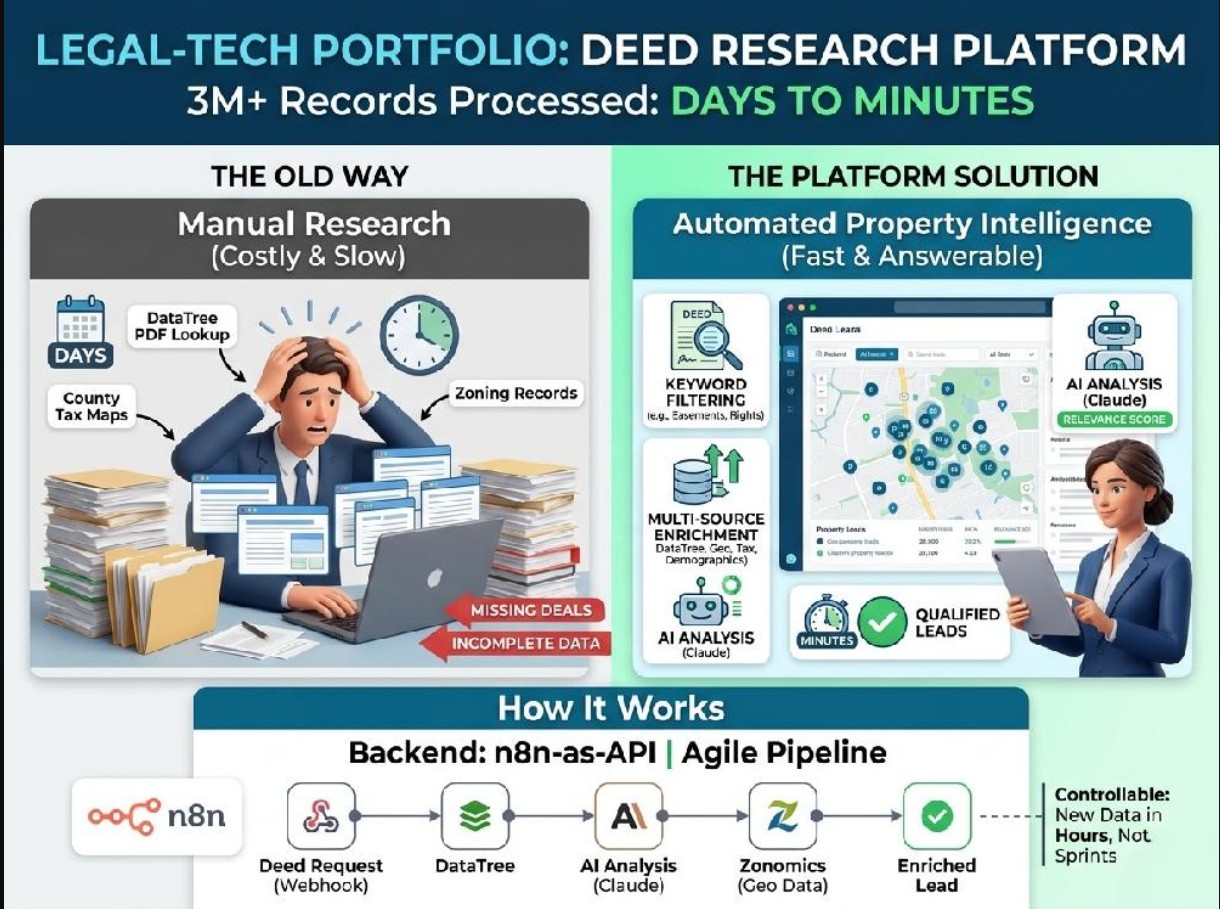
The Situation
A US-based legal-tech founder was building a property research platform for real estate attorneys: lawyers who hunt for undervalued land parcels as investment opportunities for their clients. Their work depends on finding specific language buried inside deed records such as easements, restrictions, access rights, and boundary clauses.
Before this project, finding the right parcels meant manually searching DataTree and county databases, reading individual deed PDFs, and cross-referencing with tax maps, zoning data, and demographics across separate tabs. A single qualified lead could take days. Some questions couldn't be answered at all.
The Problem
Attorneys were missing deals because the research cost was too high. Every property had to be hand-checked against keyword criteria, then enriched with geo data and infrastructure records from four different sources. The founder had tried manual workarounds and off-the-shelf tools. Nothing connected the sources. Nothing filtered by the specific legal language his clients needed to find.
The question wasn't "can we make this faster?" It was "can we make questions answerable that weren't answerable before?"
The Solution
I built an end-to-end property intelligence platform with two layers.
The frontend is a React SPA deployed on Vercel where attorneys search, filter, and review properties. Each result opens into a detail view with deed history, lot-size restrictions, tax maps, infrastructure, and county demographics, all rendered dynamically from a Supabase backend with row-level security.
The backend is n8n-as-API. Rather than running n8n as "automation glue," I used it as the production API layer for the deed-processing pipeline. When an attorney runs a keyword search, the request routes through a Supabase Edge Function to n8n webhooks. The pipeline fetches deed records from DataTree, filters by legal keywords, enriches matches with Zonomics geo data, runs AI analysis via Claude (OpenRouter), and writes progress back to Supabase in real time. Attorneys see staged progress as records are matched and enriched.
This architecture gave the founder a backend that's fully controllable, easy to modify, and fast to extend: new data sources or analysis steps ship in hours, not sprints. To support that velocity, I built a custom Claude Code toolkit that manages n8n workflows programmatically (creating, syncing, and debugging them from natural-language specs).
Tech Stack: n8n, Supabase (PostgreSQL, Auth, Storage, Edge Functions), React 19, TypeScript, Vite, Vercel, DataTree API, Zonomics API, Claude API (via OpenRouter), OpenAI API, Google Maps Embed API, Node.js, Zod, Anthropic SDK
The Results
- 3M+ deed records processed through the pipeline
- Days to minutes per qualified research query
- Questions now answerable that weren't before (multi-source queries that were economically infeasible manually)
- Production system actively used by the founder's team, serving legal clients
- Backend fully controllable: new data sources, keywords, and AI analysis steps ship without rebuilding
- Architected for microSaaS: system is already being prepared for external access by a limited set of attorneys
How It Works
1. Attorney enters keyword criteria (legal language they need in deeds) and geographic scope
2. Request routes through Supabase Edge Function to n8n webhook
3. n8n pipeline fetches matching deed records from DataTree
4. Matches enriched with Zonomics geo data, tax maps, infrastructure, demographics
5. Claude analyzes each deed for relevance; results scored and sorted
6. Attorney downloads only the deeds that match all their criteria via signed Supabase URLs
A US-based legal-tech founder was building a property research platform for real estate attorneys: lawyers who hunt for undervalued land parcels as investment opportunities for their clients. Their work depends on finding specific language buried inside deed records such as easements, restrictions, access rights, and boundary clauses.
Before this project, finding the right parcels meant manually searching DataTree and county databases, reading individual deed PDFs, and cross-referencing with tax maps, zoning data, and demographics across separate tabs. A single qualified lead could take days. Some questions couldn't be answered at all.
The Problem
Attorneys were missing deals because the research cost was too high. Every property had to be hand-checked against keyword criteria, then enriched with geo data and infrastructure records from four different sources. The founder had tried manual workarounds and off-the-shelf tools. Nothing connected the sources. Nothing filtered by the specific legal language his clients needed to find.
The question wasn't "can we make this faster?" It was "can we make questions answerable that weren't answerable before?"
The Solution
I built an end-to-end property intelligence platform with two layers.
The frontend is a React SPA deployed on Vercel where attorneys search, filter, and review properties. Each result opens into a detail view with deed history, lot-size restrictions, tax maps, infrastructure, and county demographics, all rendered dynamically from a Supabase backend with row-level security.
The backend is n8n-as-API. Rather than running n8n as "automation glue," I used it as the production API layer for the deed-processing pipeline. When an attorney runs a keyword search, the request routes through a Supabase Edge Function to n8n webhooks. The pipeline fetches deed records from DataTree, filters by legal keywords, enriches matches with Zonomics geo data, runs AI analysis via Claude (OpenRouter), and writes progress back to Supabase in real time. Attorneys see staged progress as records are matched and enriched.
This architecture gave the founder a backend that's fully controllable, easy to modify, and fast to extend: new data sources or analysis steps ship in hours, not sprints. To support that velocity, I built a custom Claude Code toolkit that manages n8n workflows programmatically (creating, syncing, and debugging them from natural-language specs).
Tech Stack: n8n, Supabase (PostgreSQL, Auth, Storage, Edge Functions), React 19, TypeScript, Vite, Vercel, DataTree API, Zonomics API, Claude API (via OpenRouter), OpenAI API, Google Maps Embed API, Node.js, Zod, Anthropic SDK
The Results
- 3M+ deed records processed through the pipeline
- Days to minutes per qualified research query
- Questions now answerable that weren't before (multi-source queries that were economically infeasible manually)
- Production system actively used by the founder's team, serving legal clients
- Backend fully controllable: new data sources, keywords, and AI analysis steps ship without rebuilding
- Architected for microSaaS: system is already being prepared for external access by a limited set of attorneys
How It Works
1. Attorney enters keyword criteria (legal language they need in deeds) and geographic scope
2. Request routes through Supabase Edge Function to n8n webhook
3. n8n pipeline fetches matching deed records from DataTree
4. Matches enriched with Zonomics geo data, tax maps, infrastructure, demographics
5. Claude analyzes each deed for relevance; results scored and sorted
6. Attorney downloads only the deeds that match all their criteria via signed Supabase URLs