Автономная AI RAG-система с векторной базой знаний
AI и машинное обучение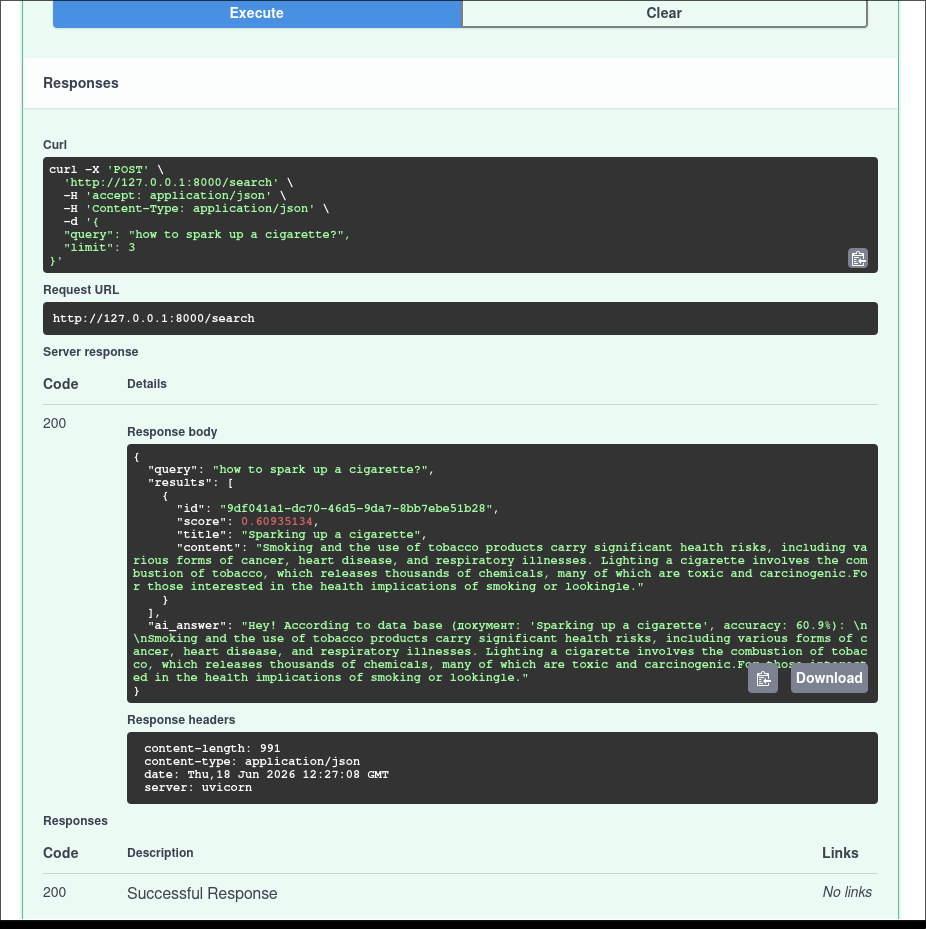
Спроектировал и реализовал с нуля асинхронную RAG-систему (Retrieval-Augmented Generation) для интеллектуального анализа и поиска по сложной технической документации или внутренним базам знаний компании.
Что реализовано в проекте:
• Асинхронный бэкенд: Высокопроизводительный API на FastAPI с runtime-валидацией входных данных через Pydantic v2.
• Векторное ядро: Нативный семантический поиск в базе данных Qdrant по метрике косинусного сходства с использованием локальных эмбеддингов (размерность вектора — 384, float32).
• Оркестрация ИИ: Логика работы агента построена на основе графовых структур LangGraph (StateGraph) с единственным потокобезопасным состоянием, что позволяет легко добавлять циклы перегенерации или узлы валидации ответов.
• Стратегия чанков: Внедрена интеллектуальная нарезка текста на чанки (400 символов) с перекрытием (overlap в 100 символов), что полностью устранило потерю контекста на стыках предложений и исключило галлюцинации модели.
Система гибкая: может работать как с локальными моделями (через Ollama), так и с облачными API (Gemini, Claude, OpenAI). Вся инфраструктура полностью контейнеризована с помощью Docker Compose и готова к деплою на сервер.
Что реализовано в проекте:
• Асинхронный бэкенд: Высокопроизводительный API на FastAPI с runtime-валидацией входных данных через Pydantic v2.
• Векторное ядро: Нативный семантический поиск в базе данных Qdrant по метрике косинусного сходства с использованием локальных эмбеддингов (размерность вектора — 384, float32).
• Оркестрация ИИ: Логика работы агента построена на основе графовых структур LangGraph (StateGraph) с единственным потокобезопасным состоянием, что позволяет легко добавлять циклы перегенерации или узлы валидации ответов.
• Стратегия чанков: Внедрена интеллектуальная нарезка текста на чанки (400 символов) с перекрытием (overlap в 100 символов), что полностью устранило потерю контекста на стыках предложений и исключило галлюцинации модели.
Система гибкая: может работать как с локальными моделями (через Ollama), так и с облачными API (Gemini, Claude, OpenAI). Вся инфраструктура полностью контейнеризована с помощью Docker Compose и готова к деплою на сервер.