НейроЛабиринт — платформа параллельного обучения агентов
AI и машинное обучение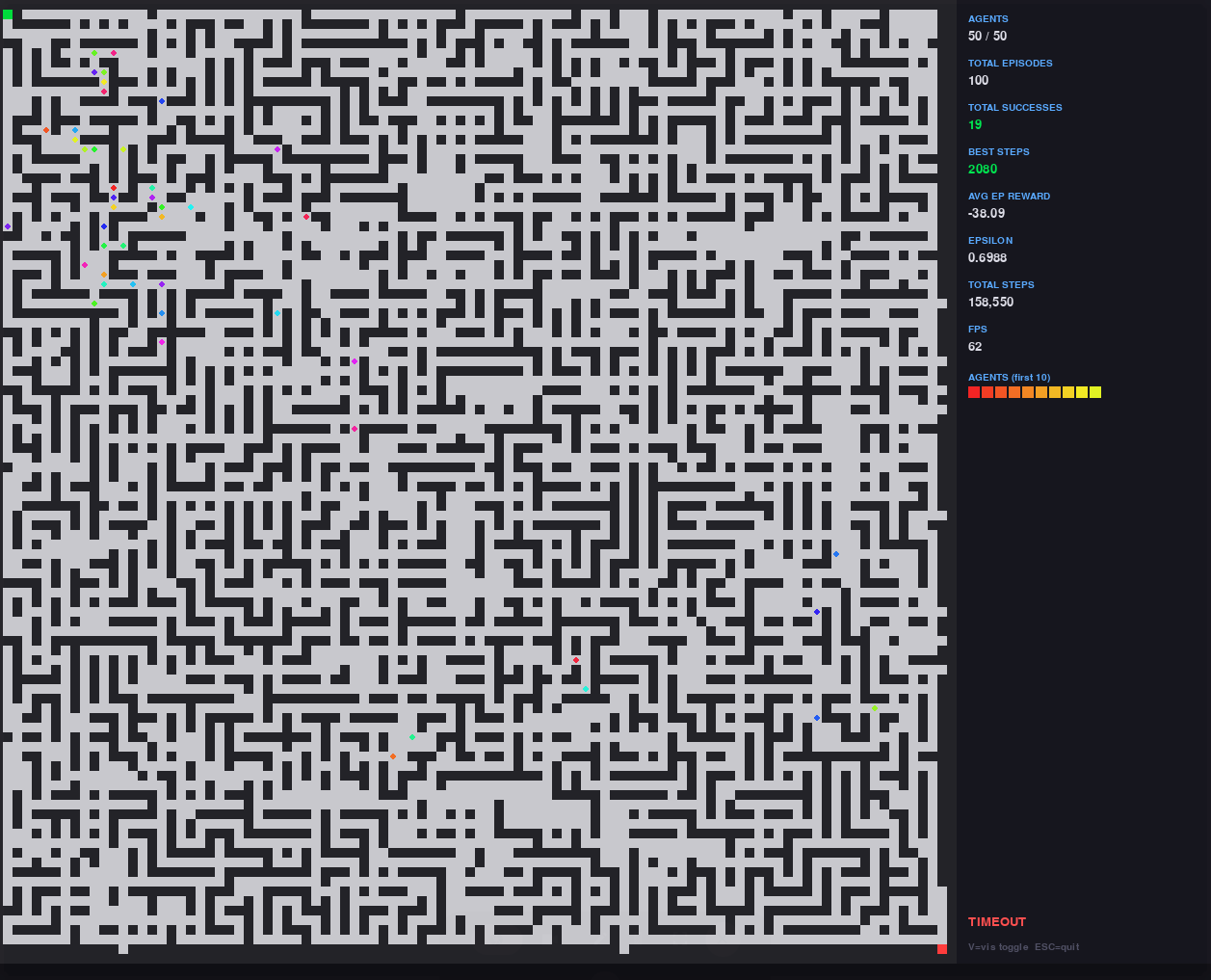
Это высокопроизводительная система обучения с подкреплением, построенная вокруг многoагентной среды Maze RL, оптимизированная под реальные вычислительные нагрузки и масштабирование.
Проект реализует полностью векторизованную симуляцию, где одновременно обучаются десятки агентов в одной и той же среде. Архитектура специально спроектирована так, чтобы уходить от классического single-agent подхода и заменять его на параллельное обучение с общей средой, что радикально увеличивает эффективность использования вычислительных ресурсов.
Каждый агент работает независимо, но в рамках единой среды, что позволяет моделировать конкурентное и коллективное поведение одновременно. Система поддерживает батчевую обработку наблюдений и действий, где все агенты проходят forward pass одной операцией, без N отдельных вызовов модели. Это даёт существенный прирост производительности и делает систему пригодной для масштабирования до сотен агентов.
Среда построена на процедурной генерации сложных лабиринтов с контролируемой структурной энтропией: циклы, ловушки, тупики, ложные пути и узкие коридоры. Это создаёт богатое пространство для обучения, где агент не может полагаться на тривиальные стратегии и вынужден формировать устойчивую политику навигации.
Система поддерживает динамическую визуализацию на Pygame, где одновременно отображаются все агенты в реальном времени, включая их позиции, прогресс и агрегированную статистику обучения. При необходимости визуализация отключается, и система переходит в высокоскоростной headless режим, достигая тысяч агент-steps в секунду на CPU.
Обучение построено на DQN-архитектуре с replay buffer, target network и epsilon decay, адаптированными под многoагентный режим. Вместо классического эпизодического цикла используется потоковый шаговый тренинг, где обновления модели происходят непрерывно по мере поступления опыта от всех агентов.
В результате получается система, которая одновременно является исследовательской платформой и инженерным инструментом: она демонстрирует поведение сложных RL-агентов в условиях плотной параллелизации, позволяет тестировать стратегии масштабирования и визуально наблюдать коллективное обучение в реальном времени.
По сути это не просто тренажёр агента, а полноценная среда для разработки и стресс-тестирования алгоритмов обучения с подкреплением в мультиагентных сценариях с высокой плотностью взаимодействия.
Проект реализует полностью векторизованную симуляцию, где одновременно обучаются десятки агентов в одной и той же среде. Архитектура специально спроектирована так, чтобы уходить от классического single-agent подхода и заменять его на параллельное обучение с общей средой, что радикально увеличивает эффективность использования вычислительных ресурсов.
Каждый агент работает независимо, но в рамках единой среды, что позволяет моделировать конкурентное и коллективное поведение одновременно. Система поддерживает батчевую обработку наблюдений и действий, где все агенты проходят forward pass одной операцией, без N отдельных вызовов модели. Это даёт существенный прирост производительности и делает систему пригодной для масштабирования до сотен агентов.
Среда построена на процедурной генерации сложных лабиринтов с контролируемой структурной энтропией: циклы, ловушки, тупики, ложные пути и узкие коридоры. Это создаёт богатое пространство для обучения, где агент не может полагаться на тривиальные стратегии и вынужден формировать устойчивую политику навигации.
Система поддерживает динамическую визуализацию на Pygame, где одновременно отображаются все агенты в реальном времени, включая их позиции, прогресс и агрегированную статистику обучения. При необходимости визуализация отключается, и система переходит в высокоскоростной headless режим, достигая тысяч агент-steps в секунду на CPU.
Обучение построено на DQN-архитектуре с replay buffer, target network и epsilon decay, адаптированными под многoагентный режим. Вместо классического эпизодического цикла используется потоковый шаговый тренинг, где обновления модели происходят непрерывно по мере поступления опыта от всех агентов.
В результате получается система, которая одновременно является исследовательской платформой и инженерным инструментом: она демонстрирует поведение сложных RL-агентов в условиях плотной параллелизации, позволяет тестировать стратегии масштабирования и визуально наблюдать коллективное обучение в реальном времени.
По сути это не просто тренажёр агента, а полноценная среда для разработки и стресс-тестирования алгоритмов обучения с подкреплением в мультиагентных сценариях с высокой плотностью взаимодействия.