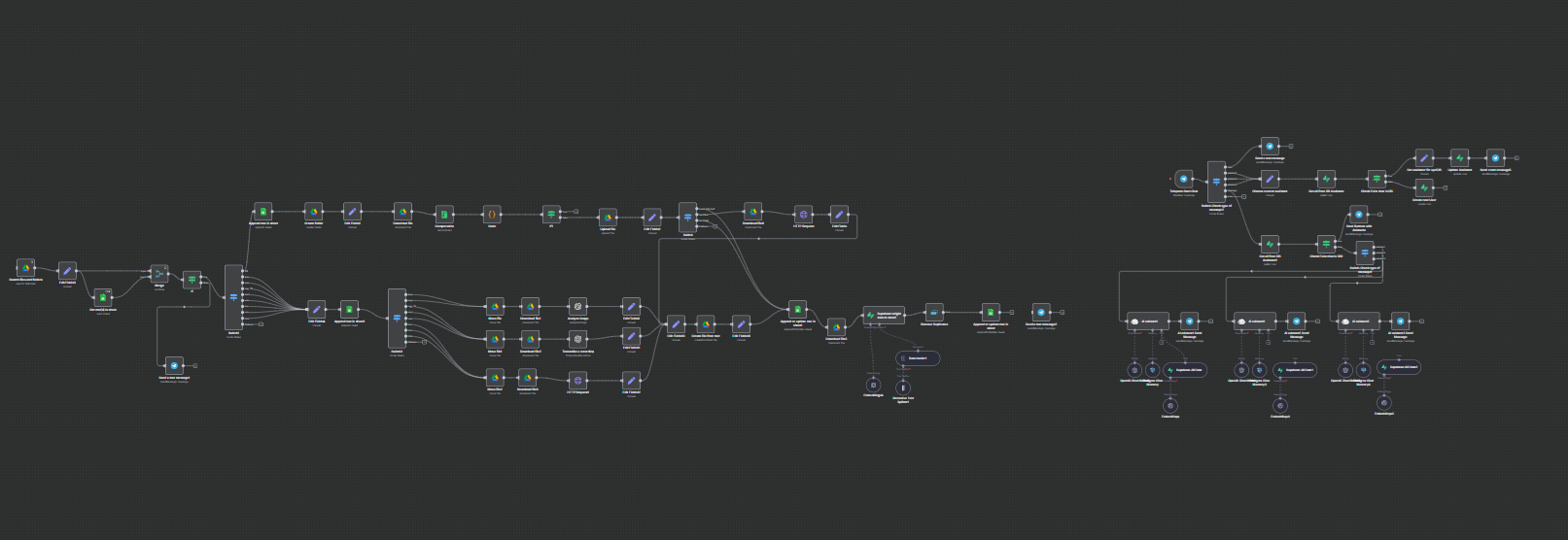
Проєкт: Автоматизована система збору контенту та створення Бази Знань на основі ШІ
Основні функції та технічна реалізація
1. Конвеєр вхідних даних та фільтрації:
Тригер регулярно сканує вказану папку на Google Drive на наявність нових файлів.
Надійний механізм дедуплікації перевіряє "регістр" у Google Sheets, щоб гарантувати, що файли обробляються лише один раз. Нові файли одразу логуються зі статусом pending (в очікуванні).
2. Модульна архітектура обробки ("Роутер"):
Центральна нода Switch діє як маршрутизатор, направляючи файли до різних гілок обробки на основі їхнього MIME-типу. Ця архітектура є легко масштабованою, що дозволяє додавати нові типи файлів з мінімальними змінами.
Гілка для ZIP-архівів:
Архіви розпаковуються, а їхній вміст повторно направляється на початок робочого процесу для індивідуальної обробки. Оригінальний архів негайно логується та переміщується, щоб уникнути повторної обробки.
Гілка для документів (.doc, .docx, .html):
Файли надсилаються на спеціально створений мікросервіс на Node.js для парсингу. Сервіс використовує спеціалізовані бібліотеки (docx-parser, textract, node-html-parser) для вилучення чистого тексту.
Гілка для зображень (.jpeg, .png):
Зображення завантажуються та надсилаються до OpenAI Vision API (gpt-4o) з детальним промптом для виконання оптичного розпізнавання символів (OCR) та опису візуальних елементів, повертаючи структурований текст.
Гілка для аудіо (.mp3, .wav, .ogg):
Аудіофайли надсилаються до OpenAI Whisper API для точної транскрипції мови в текст.
3. Стандартизація та зберігання контенту:
Результат кожної гілки обробки (витягнутий текст) стандартизується у єдиний формат.
Новий текстовий файл, що містить витягнутий контент, створюється та зберігається на Google Drive для архівування.
Далі текст передається в конвеєр на базі LangChain:
Розбиття тексту: Великі документи розбиваються на менші, частково пересічні частини (чанки), щоб відповідати обмеженням контекстного вікна моделей для ембедингів.
Створення ембедингів: Кожна частина тексту перетворюється на числовий вектор за допомогою моделей ембедингів від OpenAI.
Зберігання у векторну базу: Ембединги та пов'язані з ними метадані (ID вихідного файлу, ім'я, посилання на джерело) зберігаються в базі даних Supabase з використанням розширення pgvector.
4. Управління станом та сповіщення:
Після успішної обробки та збереження у векторну базу, відповідний запис у регістрі Google Sheets оновлюється до статусу completed.
Оригінальний вихідний файл переміщується з вхідної папки до архівного каталогу "Processed" на Google Drive.
Сповіщення в реальному часі, що містить деталі обробленого файлу та посилання на оригінал, надсилається у визначений чат Telegram.
5. Інтеграція з AI-асистентом (компонент для користувача):
Система включає багатоагентного Telegram-бота, де користувачі можуть обирати різних "асистентів".
Кожен асистент налаштований з унікальним системним промптом і може бути підключений до власної виділеної векторної бази або джерела знань.
Історія чату для кожного користувача та асистента зберігається в базі даних Postgres, що забезпечує контекстні, безперервні розмови.
Використані технології
Оркестрація: n8n (self-hosted)
Джерела даних та зберігання: Google Drive, Google Sheets
Векторна база даних: Supabase (з Postgres та pgvector)
Штучний інтелект та Ембединги: OpenAI (GPT-4o для Vision, Whisper для Audio, моделі для Text Embedding), LangChain.js (в рамках n8n)
Кастомний парсинг: Node.js, Express.js, docx-parser, textract, node-html-parser
Інтерфейс користувача: Telegram Bot API
Основні функції та технічна реалізація
1. Конвеєр вхідних даних та фільтрації:
Тригер регулярно сканує вказану папку на Google Drive на наявність нових файлів.
Надійний механізм дедуплікації перевіряє "регістр" у Google Sheets, щоб гарантувати, що файли обробляються лише один раз. Нові файли одразу логуються зі статусом pending (в очікуванні).
2. Модульна архітектура обробки ("Роутер"):
Центральна нода Switch діє як маршрутизатор, направляючи файли до різних гілок обробки на основі їхнього MIME-типу. Ця архітектура є легко масштабованою, що дозволяє додавати нові типи файлів з мінімальними змінами.
Гілка для ZIP-архівів:
Архіви розпаковуються, а їхній вміст повторно направляється на початок робочого процесу для індивідуальної обробки. Оригінальний архів негайно логується та переміщується, щоб уникнути повторної обробки.
Гілка для документів (.doc, .docx, .html):
Файли надсилаються на спеціально створений мікросервіс на Node.js для парсингу. Сервіс використовує спеціалізовані бібліотеки (docx-parser, textract, node-html-parser) для вилучення чистого тексту.
Гілка для зображень (.jpeg, .png):
Зображення завантажуються та надсилаються до OpenAI Vision API (gpt-4o) з детальним промптом для виконання оптичного розпізнавання символів (OCR) та опису візуальних елементів, повертаючи структурований текст.
Гілка для аудіо (.mp3, .wav, .ogg):
Аудіофайли надсилаються до OpenAI Whisper API для точної транскрипції мови в текст.
3. Стандартизація та зберігання контенту:
Результат кожної гілки обробки (витягнутий текст) стандартизується у єдиний формат.
Новий текстовий файл, що містить витягнутий контент, створюється та зберігається на Google Drive для архівування.
Далі текст передається в конвеєр на базі LangChain:
Розбиття тексту: Великі документи розбиваються на менші, частково пересічні частини (чанки), щоб відповідати обмеженням контекстного вікна моделей для ембедингів.
Створення ембедингів: Кожна частина тексту перетворюється на числовий вектор за допомогою моделей ембедингів від OpenAI.
Зберігання у векторну базу: Ембединги та пов'язані з ними метадані (ID вихідного файлу, ім'я, посилання на джерело) зберігаються в базі даних Supabase з використанням розширення pgvector.
4. Управління станом та сповіщення:
Після успішної обробки та збереження у векторну базу, відповідний запис у регістрі Google Sheets оновлюється до статусу completed.
Оригінальний вихідний файл переміщується з вхідної папки до архівного каталогу "Processed" на Google Drive.
Сповіщення в реальному часі, що містить деталі обробленого файлу та посилання на оригінал, надсилається у визначений чат Telegram.
5. Інтеграція з AI-асистентом (компонент для користувача):
Система включає багатоагентного Telegram-бота, де користувачі можуть обирати різних "асистентів".
Кожен асистент налаштований з унікальним системним промптом і може бути підключений до власної виділеної векторної бази або джерела знань.
Історія чату для кожного користувача та асистента зберігається в базі даних Postgres, що забезпечує контекстні, безперервні розмови.
Використані технології
Оркестрація: n8n (self-hosted)
Джерела даних та зберігання: Google Drive, Google Sheets
Векторна база даних: Supabase (з Postgres та pgvector)
Штучний інтелект та Ембединги: OpenAI (GPT-4o для Vision, Whisper для Audio, моделі для Text Embedding), LangChain.js (в рамках n8n)
Кастомний парсинг: Node.js, Express.js, docx-parser, textract, node-html-parser
Інтерфейс користувача: Telegram Bot API