#Kubernetes #Security #Automation #GPT #DataAnalysis #DevSecOps #AI #PromptEngineering #BigData
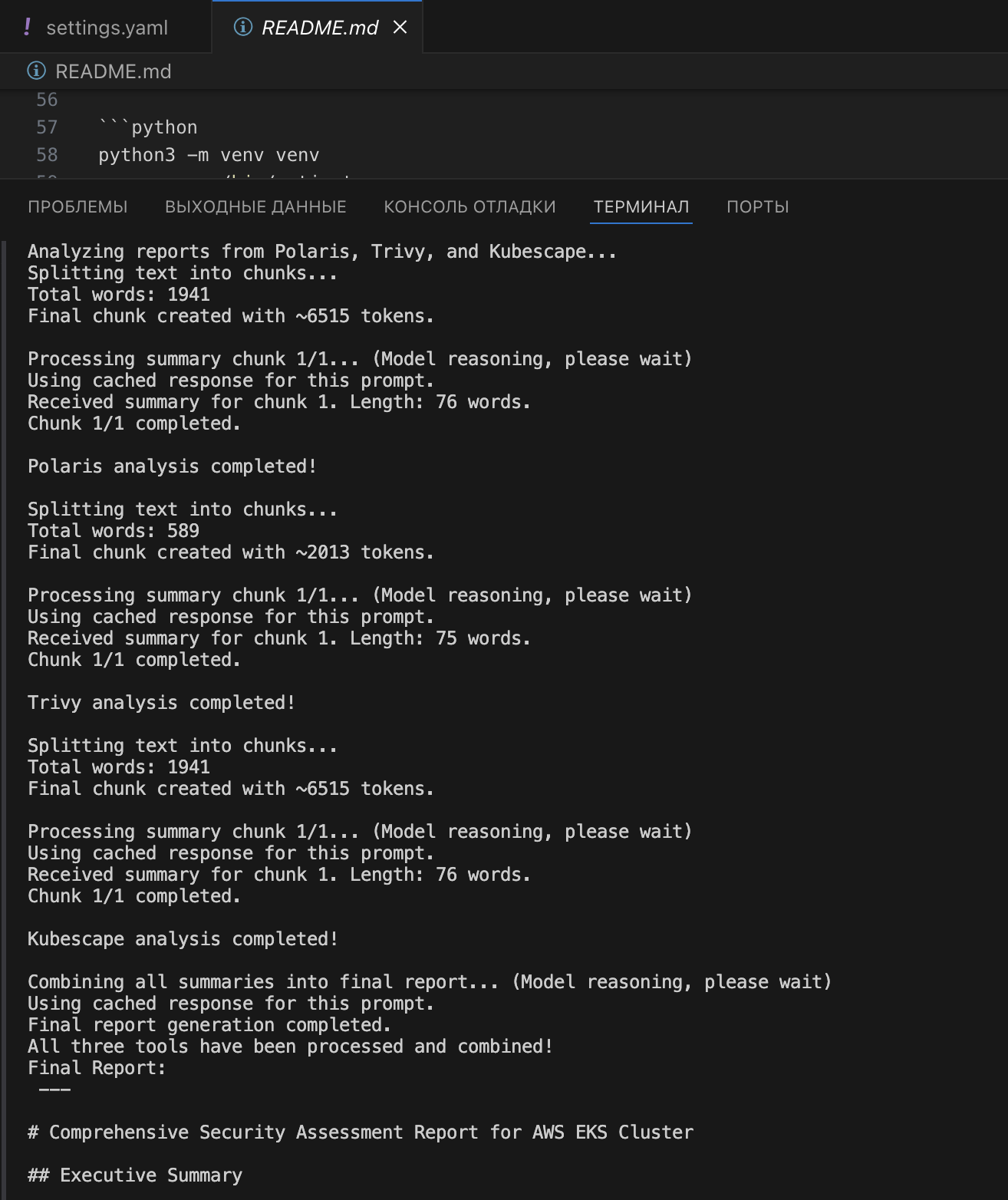
Цей проєкт покликаний автоматизувати аналіз великих JSON-звітів безпеки Kubernetes (#Polaris, #Trivy, #Kubescape). Замовниця потребувала зручного інструмента для перетворення сирих даних на корисний звіт із ключовими висновками, найкращими практиками, рекомендаціями та оцінкою зрілості. Результат мав бути готовим до презентацій для технічної й нетехнічної аудиторії.
Завдання та Виклики
• Обробка величезних обсягів даних (#BigData) без перевищення контексту GPT.
• Окремі #Prompts для кожного інструмента для підвищення точності (#PromptEngineering).
• Збалансувати витрати: початковий рівень узагальнення має бути дешевшим (#gpt-3.5-turbo), фінальний — глибшим (#o1-mini), щоб зберегти якість (#CostOptimization).
• Ієрархічний підхід (#HierarchicalAnalysis) та кешування (#Caching) для прискорення повторних запусків.
Рішення
1. Ієрархічний аналіз: Дані розбиваються на чанки, узагальнюються gpt-3.5-turbo, потім підсумки трьох інструментів об’єднує o1-mini.
2. Окремі промти: Кожен інструмент має свій промт, підлаштований під формат даних (#Polaris, #Trivy, #Kubescape).
3. Кешування: Зменшує час і вартість повторних запусків.
4. Модульність: Код розділено на модулі, що спростило майбутні оновлення (#Modularity).
Результати
• Повна автоматизація аналізу (#Automation): Величезні файли обробляються без ручної праці.
• Оптимізація витрат (#CostEffective): Початкові узагальнення гpt-3.5-turbo дешеві, кешування швидке.
• Якісний фінальний звіт (#QualityOutput): Завдяки гібридному підходу й промтам звіт точний, релевантний і готовий для презентацій.
Висновок
Цей кейс демонструє ефективність #AI, #LLM та #PromptEngineering у задачах #DevSecOps та #DataAnalysis. Поєднання різних моделей, ієрархічний аналіз, модульна архітектура й чітка документація зробили рішення гнучким, масштабованим і економічним.
Цей проєкт покликаний автоматизувати аналіз великих JSON-звітів безпеки Kubernetes (#Polaris, #Trivy, #Kubescape). Замовниця потребувала зручного інструмента для перетворення сирих даних на корисний звіт із ключовими висновками, найкращими практиками, рекомендаціями та оцінкою зрілості. Результат мав бути готовим до презентацій для технічної й нетехнічної аудиторії.
Завдання та Виклики
• Обробка величезних обсягів даних (#BigData) без перевищення контексту GPT.
• Окремі #Prompts для кожного інструмента для підвищення точності (#PromptEngineering).
• Збалансувати витрати: початковий рівень узагальнення має бути дешевшим (#gpt-3.5-turbo), фінальний — глибшим (#o1-mini), щоб зберегти якість (#CostOptimization).
• Ієрархічний підхід (#HierarchicalAnalysis) та кешування (#Caching) для прискорення повторних запусків.
Рішення
1. Ієрархічний аналіз: Дані розбиваються на чанки, узагальнюються gpt-3.5-turbo, потім підсумки трьох інструментів об’єднує o1-mini.
2. Окремі промти: Кожен інструмент має свій промт, підлаштований під формат даних (#Polaris, #Trivy, #Kubescape).
3. Кешування: Зменшує час і вартість повторних запусків.
4. Модульність: Код розділено на модулі, що спростило майбутні оновлення (#Modularity).
Результати
• Повна автоматизація аналізу (#Automation): Величезні файли обробляються без ручної праці.
• Оптимізація витрат (#CostEffective): Початкові узагальнення гpt-3.5-turbo дешеві, кешування швидке.
• Якісний фінальний звіт (#QualityOutput): Завдяки гібридному підходу й промтам звіт точний, релевантний і готовий для презентацій.
Висновок
Цей кейс демонструє ефективність #AI, #LLM та #PromptEngineering у задачах #DevSecOps та #DataAnalysis. Поєднання різних моделей, ієрархічний аналіз, модульна архітектура й чітка документація зробили рішення гнучким, масштабованим і економічним.