Система розпізнавання номерних знаків (ALPR)
AI та машинне навчання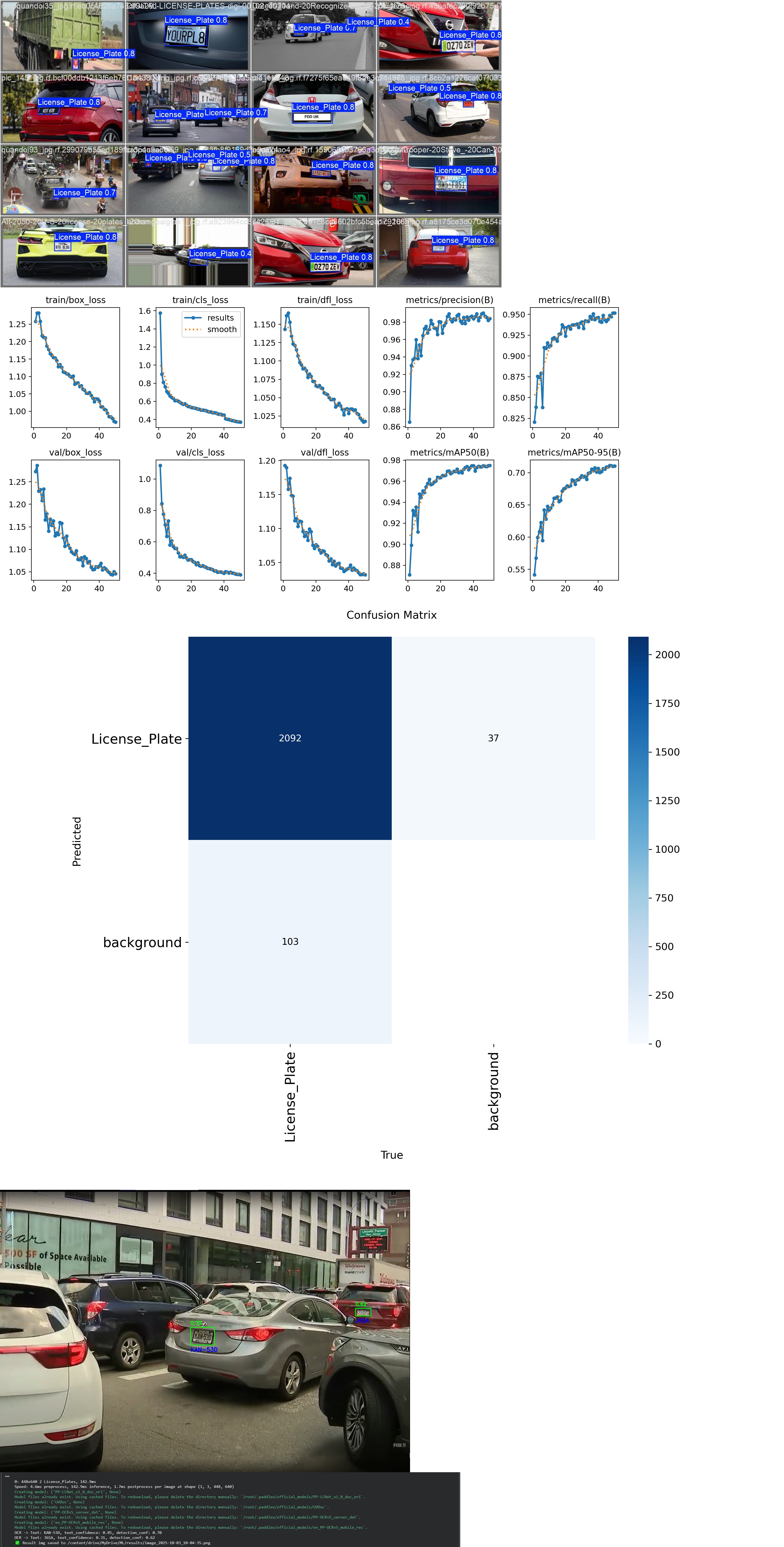
Про проект
Проект спрямований на створення системи комп'ютерного зору для автоматичної ідентифікації транспортних засобів шляхом зчитування їхніх номерних знаків. Система працює у два етапи: спочатку знаходить номер на зображенні, а потім розпізнає текст на ньому.
Натренував модель на кастомному датасеті, досягнувши високої точності виявлення локалізації номера.
Інтегрував бібліотеку PaddleOCR для витягування тексту з вирізаних (cropped) зображень номерів.
Реалізував скрипт на Python з використанням OpenCV для візуалізації результатів (bounding boxes + текст) та фільтрації передбачень за порогом впевненості (confidence threshold).
Пайплайн інференсу:
1. Зображення подається на вхід моделі.
2. Отримані координати (xyxy) використовуються для вирізання області номера (ROI crop).
3. Вирізаний фрагмент передається в PaddleOCR для розпізнавання тексту.
4. Результат фільтрується за порогом впевненості (conf_thresh=0.5).
Візуалізація:
За допомогою OpenCV на оригінальне зображення наносяться рамки та розпізнаний текст, результат зберігається локально.
Технічний стек
• Мова: Python
• ML/DL Frameworks: PyTorch, PaddlePaddle
• CV Libraries: Ultralytics (YOLO), PaddleOCR, OpenCV
#machinelearining #computervision #ML #AI
Проект спрямований на створення системи комп'ютерного зору для автоматичної ідентифікації транспортних засобів шляхом зчитування їхніх номерних знаків. Система працює у два етапи: спочатку знаходить номер на зображенні, а потім розпізнає текст на ньому.
Натренував модель на кастомному датасеті, досягнувши високої точності виявлення локалізації номера.
Інтегрував бібліотеку PaddleOCR для витягування тексту з вирізаних (cropped) зображень номерів.
Реалізував скрипт на Python з використанням OpenCV для візуалізації результатів (bounding boxes + текст) та фільтрації передбачень за порогом впевненості (confidence threshold).
Пайплайн інференсу:
1. Зображення подається на вхід моделі.
2. Отримані координати (xyxy) використовуються для вирізання області номера (ROI crop).
3. Вирізаний фрагмент передається в PaddleOCR для розпізнавання тексту.
4. Результат фільтрується за порогом впевненості (conf_thresh=0.5).
Візуалізація:
За допомогою OpenCV на оригінальне зображення наносяться рамки та розпізнаний текст, результат зберігається локально.
Технічний стек
• Мова: Python
• ML/DL Frameworks: PyTorch, PaddlePaddle
• CV Libraries: Ultralytics (YOLO), PaddleOCR, OpenCV
#machinelearining #computervision #ML #AI