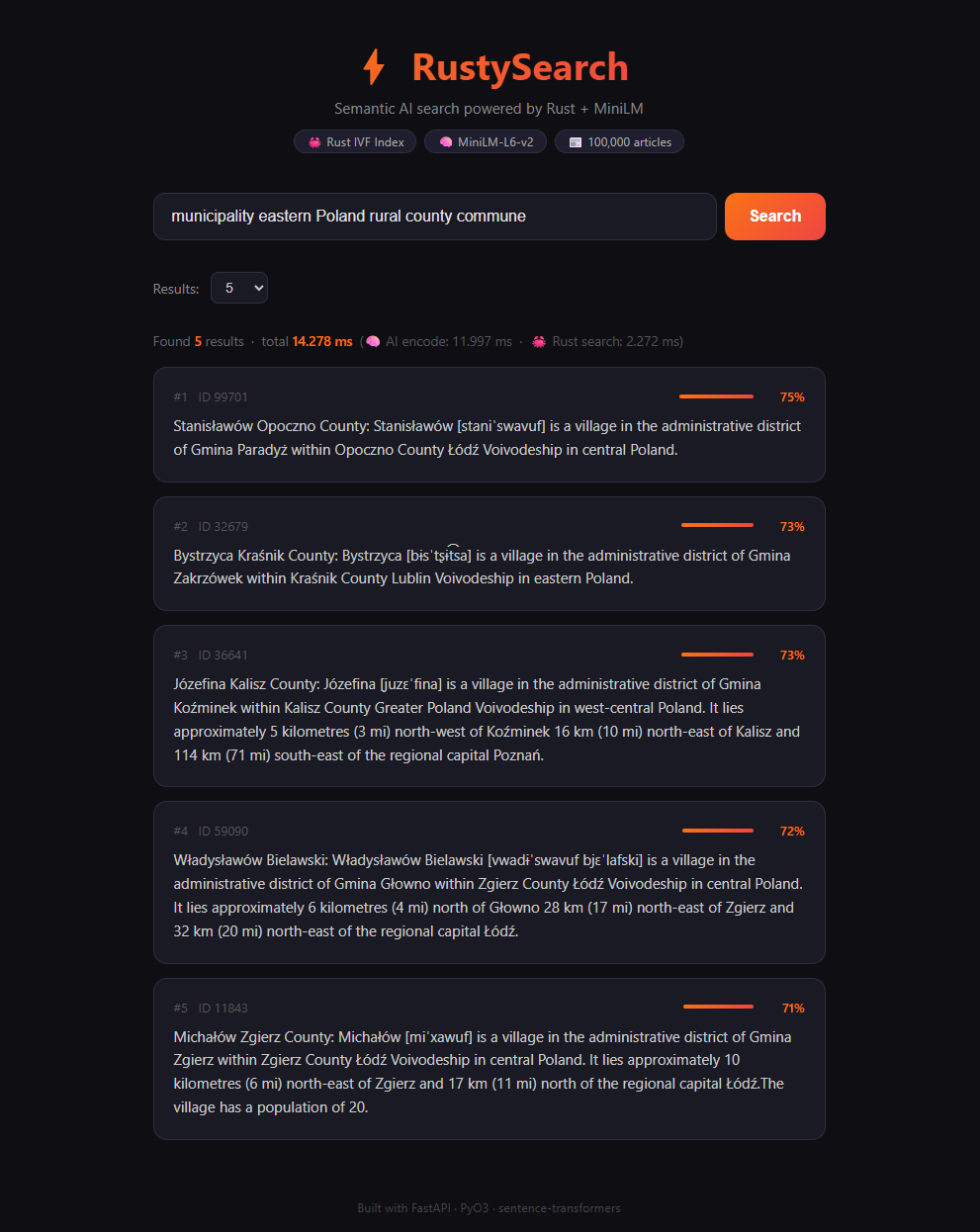
RustySearch — це обчислювальне ядро, написане на Rust, яке перетворює будь-яку базу даних на інтелектуальну систему відповідей. Замість класичного пошуку за збігом слів система розуміє семантику тексту, поєднуючи моделі машинного навчання зі швидкістю низькорівневої мови програмування.
Архітектура: від тексту до вектора
Процес пошуку побудований на гібридному підході та складається з двох етапів:
1. AI-векторизація: Нейромережа (на базі архітектури Transformer) аналізує вхідний запит і перетворює
його на багатовимірний вектор (ембеддінг), фіксуючи зміст та контекст.
2. Rust-ядро: Алгоритм пошуку миттєво обчислює відстань між векторами та знаходить найбільш
релевантні результати у великих масивах даних.
Технічна інновація під капотом
Щоб уникнути повільного лінійного пошуку, у системі реалізовано Inverted File Index (IVF). За допомогою алгоритму кластеризації K-means векторний простір розбивається на комірки Вороного. Завдяки цьому рушій не перевіряє кожен запис у базі, а одразу звертається до потрібного кластера, кардинально прискорюючи видачу.
Ключові переваги системи
Продуктивність: Час пошуку серед сотень тисяч записів становить менше ніж 2 мс — це у 30–50 разів
швидше за аналогічні скрипти на Python.
Універсальність: Ядро працює з будь-якими джерелами даних, від локальних файлів (JSON/CSV) до
промислових баз (SQL/NoSQL).
Гнучкість налаштувань: Архітектура на Rust дозволяє легко адаптувати систему під специфічні бізнес
задачі, змінювати метрики схожості або інтегрувати її у складні розподілені мережі.
Автономність: Продуктивність рівня хмарних векторних БД (наприклад, Pinecone), але з повним
контролем над власними даними та без щомісячних підписок.
Сфери застосування
RAG-системи (Retrieval-Augmented Generation): Створення розумних асистентів, які відповідають на
запитання на основі внутрішньої документації.
E-commerce: Точні рекомендаційні системи, які пропонують товари за описовими або нестандартними
запитами користувачів.
Big Data аналітика: Пошук схожих патернів, дублікатів або аномалій у великих датасетах.
Ефективність у цифрах
Алгоритмічна складність: Знижена з лінійної O(N) до сублінійної O(√N).
Точність (Recall): 90–98% при збереженні високої швидкості обробки.
Час відгуку: Середня затримка пошукового запиту — 1.4 мс.
#AI #MachineLearning #SemanticSearchс #nlp #RAG #highload #LowLatency #PerformanceOptimization #Algorithms #SystemProgramming #Backend #Rust
Архітектура: від тексту до вектора
Процес пошуку побудований на гібридному підході та складається з двох етапів:
1. AI-векторизація: Нейромережа (на базі архітектури Transformer) аналізує вхідний запит і перетворює
його на багатовимірний вектор (ембеддінг), фіксуючи зміст та контекст.
2. Rust-ядро: Алгоритм пошуку миттєво обчислює відстань між векторами та знаходить найбільш
релевантні результати у великих масивах даних.
Технічна інновація під капотом
Щоб уникнути повільного лінійного пошуку, у системі реалізовано Inverted File Index (IVF). За допомогою алгоритму кластеризації K-means векторний простір розбивається на комірки Вороного. Завдяки цьому рушій не перевіряє кожен запис у базі, а одразу звертається до потрібного кластера, кардинально прискорюючи видачу.
Ключові переваги системи
Продуктивність: Час пошуку серед сотень тисяч записів становить менше ніж 2 мс — це у 30–50 разів
швидше за аналогічні скрипти на Python.
Універсальність: Ядро працює з будь-якими джерелами даних, від локальних файлів (JSON/CSV) до
промислових баз (SQL/NoSQL).
Гнучкість налаштувань: Архітектура на Rust дозволяє легко адаптувати систему під специфічні бізнес
задачі, змінювати метрики схожості або інтегрувати її у складні розподілені мережі.
Автономність: Продуктивність рівня хмарних векторних БД (наприклад, Pinecone), але з повним
контролем над власними даними та без щомісячних підписок.
Сфери застосування
RAG-системи (Retrieval-Augmented Generation): Створення розумних асистентів, які відповідають на
запитання на основі внутрішньої документації.
E-commerce: Точні рекомендаційні системи, які пропонують товари за описовими або нестандартними
запитами користувачів.
Big Data аналітика: Пошук схожих патернів, дублікатів або аномалій у великих датасетах.
Ефективність у цифрах
Алгоритмічна складність: Знижена з лінійної O(N) до сублінійної O(√N).
Точність (Recall): 90–98% при збереженні високої швидкості обробки.
Час відгуку: Середня затримка пошукового запиту — 1.4 мс.
#AI #MachineLearning #SemanticSearchс #nlp #RAG #highload #LowLatency #PerformanceOptimization #Algorithms #SystemProgramming #Backend #Rust