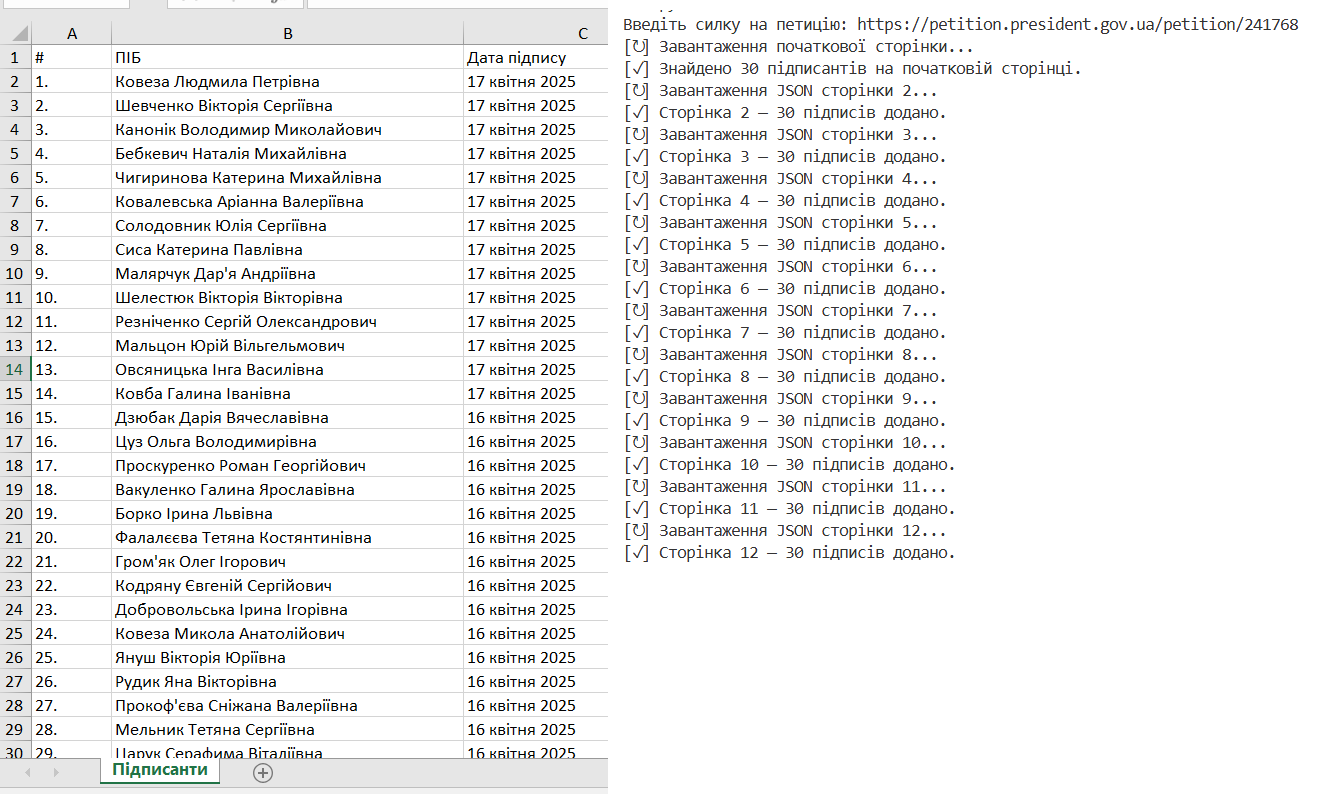
Цей парсер автоматизує збір інформації про підписантів електронних петицій з офіційного сайту Президента України. Він приймає посилання на конкретну петицію і послідовно збирає дані з усіх сторінок підписів, включаючи ім'я, прізвище та дату підпису кожного користувача.
Парсер працює у два етапи: спершу завантажує і парсить статичний HTML першої сторінки петиції, де відображена частина підписантів, а потім динамічно отримує додаткові сторінки через AJAX-запити до API у форматі JSON. Отримані дані обробляються та зберігаються у форматі Excel (.xlsx) з поступовим оновленням файлу після кожної сторінки, що забезпечує надійність роботи навіть при перериванні процесу.
Використані технології: Python, бібліотеки requests (HTTP-запити), BeautifulSoup (парсинг HTML), openpyxl (робота з Excel), регулярні вирази (вилучення ID петиції), а також базові механізми обробки JSON. Парсер орієнтований на стійку роботу з великими обсягами даних та враховує особливості динамічного завантаження контенту.
Парсер працює у два етапи: спершу завантажує і парсить статичний HTML першої сторінки петиції, де відображена частина підписантів, а потім динамічно отримує додаткові сторінки через AJAX-запити до API у форматі JSON. Отримані дані обробляються та зберігаються у форматі Excel (.xlsx) з поступовим оновленням файлу після кожної сторінки, що забезпечує надійність роботи навіть при перериванні процесу.
Використані технології: Python, бібліотеки requests (HTTP-запити), BeautifulSoup (парсинг HTML), openpyxl (робота з Excel), регулярні вирази (вилучення ID петиції), а також базові механізми обробки JSON. Парсер орієнтований на стійку роботу з великими обсягами даних та враховує особливості динамічного завантаження контенту.