Парсинг захищеного SPA-сайту, Обхід Cloudflare та антибот-систем
Парсинг даних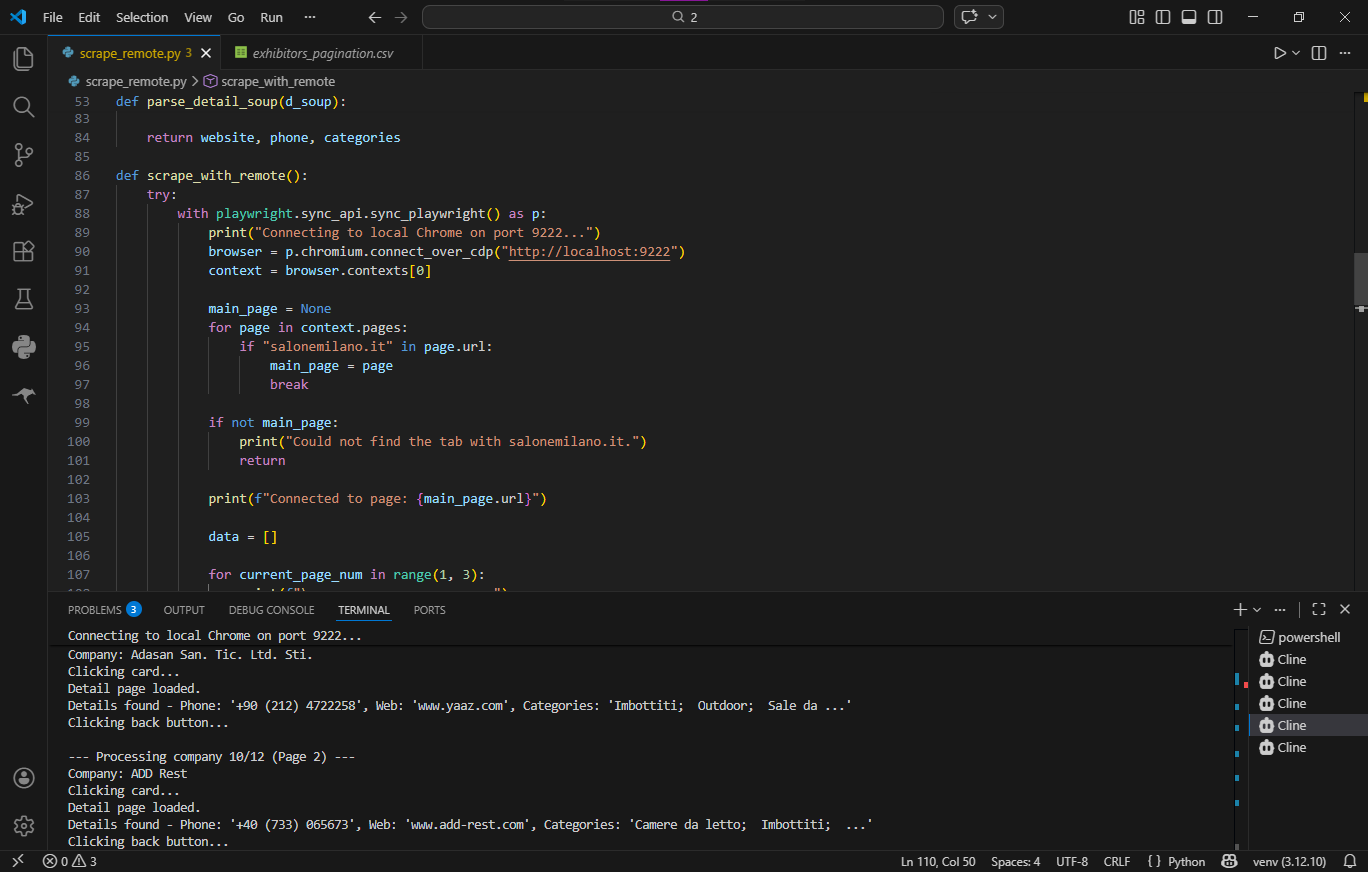
Мета: Зібрати 100% точні дані про понад 1000 експонентів (назва, країна, номер стенда, приховані email та телефони, категорії) з офіційного сайту Salone del Mobile.
Головні виклики:
Агресивний антибот-захист (Cloudflare): Стандартні запити (requests/httpx) повертали 403 Forbidden. Звичайні headless-браузери (Selenium, Playwright) та навіть фреймворки на кшталт undetected-chromedriver миттєво блокувалися.
Складна SPA-архітектура (React / Next.js): На сайті не було стандартних HTML-посилань (). Уся навігація відбувалася виключно через обробники подій React (onClick), що робило традиційний збір URL неможливим. Крім того, контактні дані були заховані в несемантичних тегах (наприклад, ).
Моє рішення:
Щоб досягти ідеальної точності та обійти захист, я розробив кастомний гібридний підхід:
Підключення через Chrome DevTools Protocol (CDP): Замість запуску нового екземпляра автоматизованого браузера, мій скрипт використовував Playwright для підключення до вже запущеної, "живої" сесії Google Chrome (http://localhost:9222). Це дало 100% "траст-фактор" легітимного користувача (разом із реальними cookies, історією та відбитками Canvas). Cloudflare було обійдено без жодної розв'язаної капчі.
Інтелектуальна навігація: Скрипт візуально імітував поведінку людини — перехоплював динамічні локатори, фізично клікав мишкою для виклику React-станів та використовував внутрішній роутер сайту для повернення до списку, зберігаючи пагінацію.
Парсинг HTML: Захоплений стан сторінки оброблявся через BeautifulSoup та складні регулярні вирази (Regex) для точного витягування "битих" або погано відформатованих посилань та номерів телефонів.
Використані технології:
Python 3.12
Playwright (Sync API): взаємодія з DOM та підключення через CDP.
BeautifulSoup4 & Regex: точний пошук та витягування даних.
Pandas: структурування та експорт даних у чистий CSV (UTF-8 з BOM) та Excel.
Результат:
Скрипт повністю автономно зібрав та ідеально відформатував дані понад 1200 компаній. Створена архітектура дозволяє масштабувати парсинг без ризику отримати бан по IP.
Головні виклики:
Агресивний антибот-захист (Cloudflare): Стандартні запити (requests/httpx) повертали 403 Forbidden. Звичайні headless-браузери (Selenium, Playwright) та навіть фреймворки на кшталт undetected-chromedriver миттєво блокувалися.
Складна SPA-архітектура (React / Next.js): На сайті не було стандартних HTML-посилань (). Уся навігація відбувалася виключно через обробники подій React (onClick), що робило традиційний збір URL неможливим. Крім того, контактні дані були заховані в несемантичних тегах (наприклад, ).
Моє рішення:
Щоб досягти ідеальної точності та обійти захист, я розробив кастомний гібридний підхід:
Підключення через Chrome DevTools Protocol (CDP): Замість запуску нового екземпляра автоматизованого браузера, мій скрипт використовував Playwright для підключення до вже запущеної, "живої" сесії Google Chrome (http://localhost:9222). Це дало 100% "траст-фактор" легітимного користувача (разом із реальними cookies, історією та відбитками Canvas). Cloudflare було обійдено без жодної розв'язаної капчі.
Інтелектуальна навігація: Скрипт візуально імітував поведінку людини — перехоплював динамічні локатори, фізично клікав мишкою для виклику React-станів та використовував внутрішній роутер сайту для повернення до списку, зберігаючи пагінацію.
Парсинг HTML: Захоплений стан сторінки оброблявся через BeautifulSoup та складні регулярні вирази (Regex) для точного витягування "битих" або погано відформатованих посилань та номерів телефонів.
Використані технології:
Python 3.12
Playwright (Sync API): взаємодія з DOM та підключення через CDP.
BeautifulSoup4 & Regex: точний пошук та витягування даних.
Pandas: структурування та експорт даних у чистий CSV (UTF-8 з BOM) та Excel.
Результат:
Скрипт повністю автономно зібрав та ідеально відформатував дані понад 1200 компаній. Створена архітектура дозволяє масштабувати парсинг без ризику отримати бан по IP.