Система вебскрейпінгу та обробки даних
Парсинг даних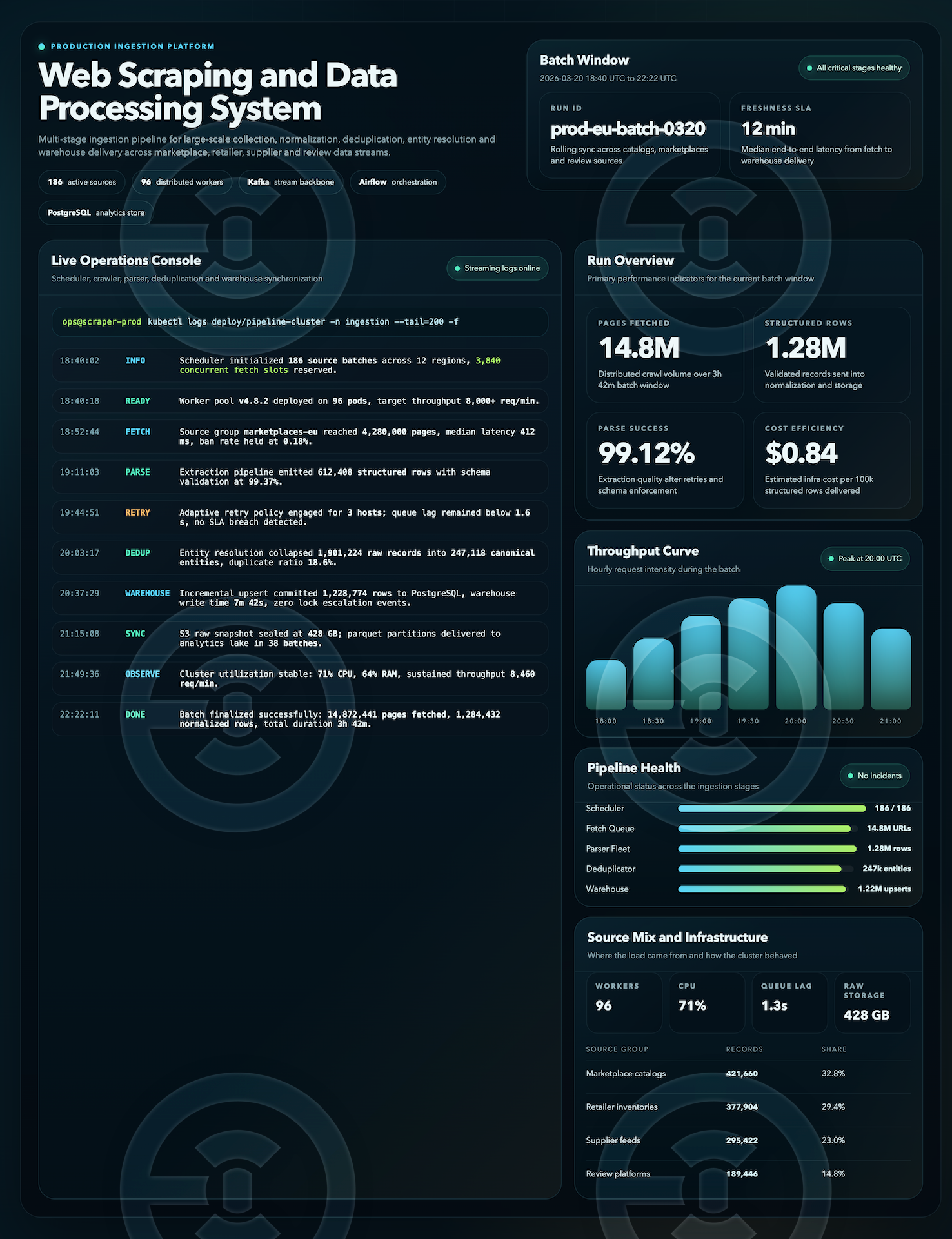
Розробка системи вебскрейпінгу та обробки даних для багатокрокового збору, нормалізації, дедуплікації та підготовки великих масивів інформації до подальшого використання в аналітиці та внутрішніх бізнес-процесах.
У межах роботи була спроєктована структура ingestion pipeline для масового збору даних із кількох типів джерел із подальшою обробкою через черги, нормалізацією сутностей, валідацією структури, дедуплікацією та підготовкою до завантаження в сховище. Окрему увагу приділено стабільності batch-обробки, якості даних і спостережуваності всіх ключових етапів пайплайна.
Що реалізовано за логікою проєкту:
— багатокроковий pipeline збору та обробки даних
— розподілена обробка джерел і batch-задач
— нормалізація та дедуплікація записів
— контроль latency, throughput і якості обробки
— підготовка даних для warehouse / analytics use cases
— моніторинг стану пайплайна, логів і операційних метрик
Стек і підхід:
web scraping, data processing, batch pipelines, normalization, deduplication, PostgreSQL, Kafka, Airflow, warehouse-oriented ingestion, operational monitoring.
Результат:
створено структуровану систему для масового збору та обробки даних з акцентом на стабільність, якість даних, прозорість pipeline-процесів і зручність подальшого масштабування.
У межах роботи була спроєктована структура ingestion pipeline для масового збору даних із кількох типів джерел із подальшою обробкою через черги, нормалізацією сутностей, валідацією структури, дедуплікацією та підготовкою до завантаження в сховище. Окрему увагу приділено стабільності batch-обробки, якості даних і спостережуваності всіх ключових етапів пайплайна.
Що реалізовано за логікою проєкту:
— багатокроковий pipeline збору та обробки даних
— розподілена обробка джерел і batch-задач
— нормалізація та дедуплікація записів
— контроль latency, throughput і якості обробки
— підготовка даних для warehouse / analytics use cases
— моніторинг стану пайплайна, логів і операційних метрик
Стек і підхід:
web scraping, data processing, batch pipelines, normalization, deduplication, PostgreSQL, Kafka, Airflow, warehouse-oriented ingestion, operational monitoring.
Результат:
створено структуровану систему для масового збору та обробки даних з акцентом на стабільність, якість даних, прозорість pipeline-процесів і зручність подальшого масштабування.