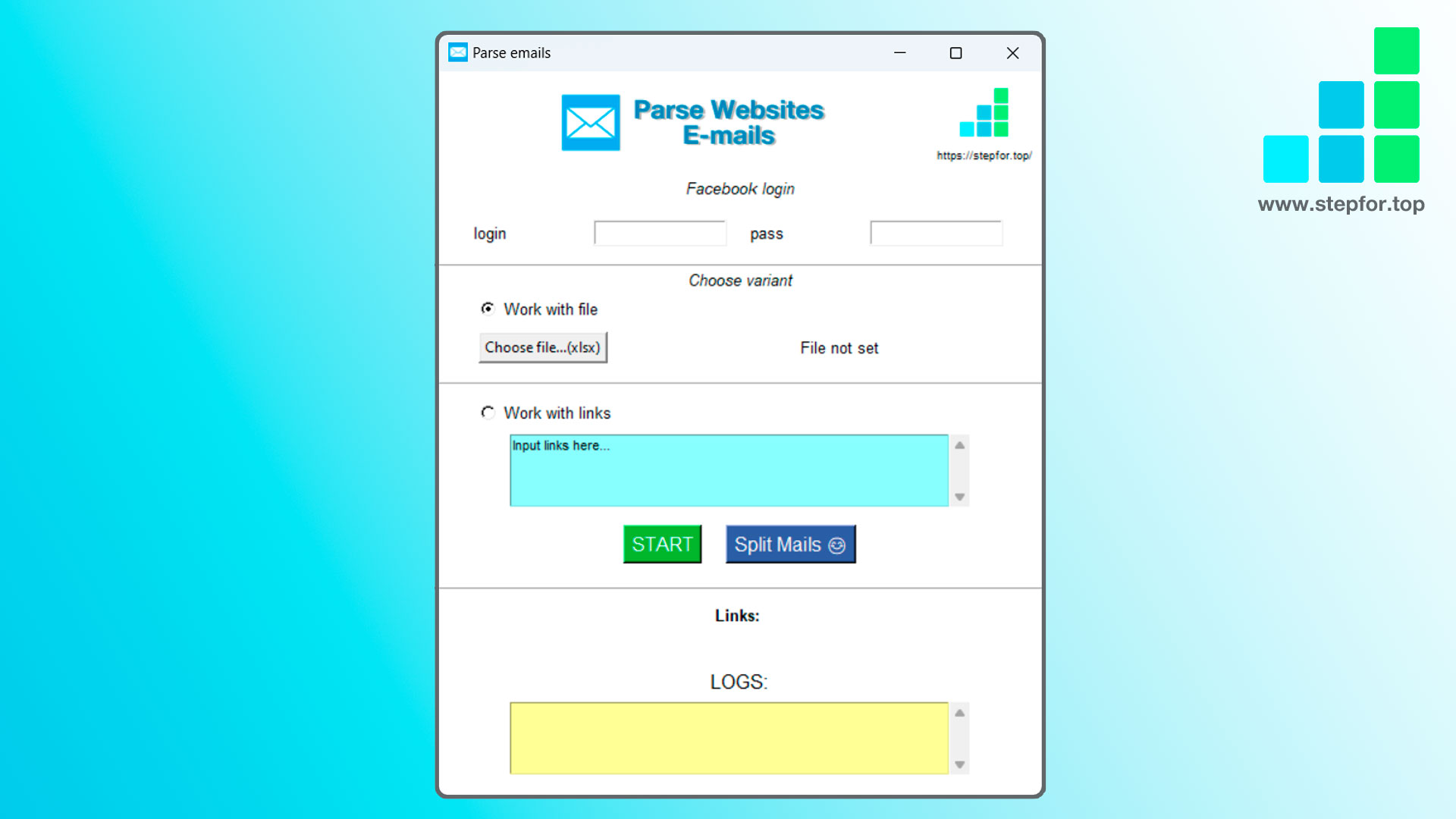
#The #emails parser collects emails from a list of links to any website.
It is implemented in Python + Selenium (the most efficient option).
The search is carried out on the bare page, the Contacts page (provided that the page name contains the word "contact"), and the team page. You can add a list of such pages yourself)
The program takes data for parsing:
1. The uploaded Excel file (the main thing is that it should have a column named Site, additionally (not necessarily) there can be a column named Name)
2. Just copy and paste the list of links to the site
The program logs in to your Facebook account to be able to collect emails from Facebook pages as well, so the program provides login and pass fields. It is not a prerequisite. You can leave it blank.
Important: Emails within one site are collected without duplicates, excluding the most common fraudulent emails. There is also a built-in bypass of various types of parser-protected emails.
The result is an excel file:
- company name (provided that this name was present in the original excel file in the Name column)
- website
- all found emails on the website separated by commas
- link to the Facebook page
- link to LinkedIn page
Split Mails: Additionally, there is a function to split emails (collected for one company) with a comma - one email in a line. This will be useful for mass email campaigns.
P.S.
Separately, there is a Python + requests option and another, the fastest, asynchronous parser for large data sets.
It is implemented in Python + Selenium (the most efficient option).
The search is carried out on the bare page, the Contacts page (provided that the page name contains the word "contact"), and the team page. You can add a list of such pages yourself)
The program takes data for parsing:
1. The uploaded Excel file (the main thing is that it should have a column named Site, additionally (not necessarily) there can be a column named Name)
2. Just copy and paste the list of links to the site
The program logs in to your Facebook account to be able to collect emails from Facebook pages as well, so the program provides login and pass fields. It is not a prerequisite. You can leave it blank.
Important: Emails within one site are collected without duplicates, excluding the most common fraudulent emails. There is also a built-in bypass of various types of parser-protected emails.
The result is an excel file:
- company name (provided that this name was present in the original excel file in the Name column)
- website
- all found emails on the website separated by commas
- link to the Facebook page
- link to LinkedIn page
Split Mails: Additionally, there is a function to split emails (collected for one company) with a comma - one email in a line. This will be useful for mass email campaigns.
P.S.
Separately, there is a Python + requests option and another, the fastest, asynchronous parser for large data sets.