Audio Transcription Tool
Python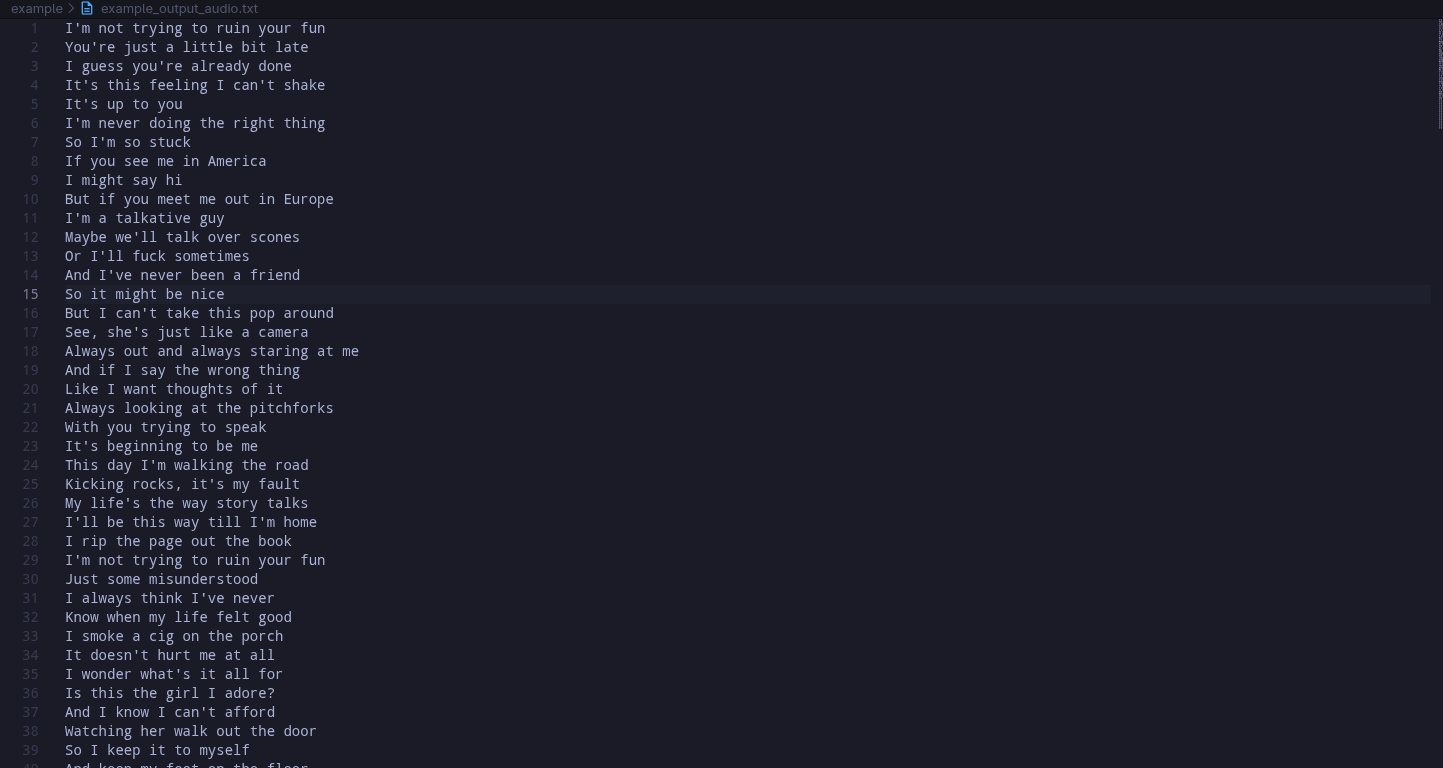
Console application in Python for automatic transcription of audio files using the faster-whisper model (optimized implementation of OpenAI Whisper). The project converts the input audio file to text, saves the transcription to a file, and optionally splits it into parts for easier processing of large volumes.
Features:
1) Support for various audio formats through automatic conversion to WAV using FFmpeg (mono, 16 kHz).
2) Use of the Whisper large model (customizable in size) for high recognition accuracy.
3) Decoding parameters (beam_size=20, best_of=10, temperature=0.2) for a balance between accuracy and speed.
4) Automatic detection of language and audio duration with logging.
5) Saving the transcription line by line in a text file (.txt).
6) Splitting large text into parts of 500 lines for easier further processing.
7) Detailed logging of all stages to a file for debugging.
8) Minimalist CLI interface: support for specifying the path to audio via command line argument.
9) Full modularity: separate modules for configuration, logging, conversion, transcription, and text splitting.
Example of operation:
When processing a song with vocals, the model attempts to transcribe the text, but due to the musical accompaniment, there are significant inaccuracies: repetitions of phrases, distortions of words, and hallucinations (for example, the repeated line "I'm not trying to be a fool"). This is expected, as Whisper is optimized primarily for speech rather than lyrics in music—the background instrumental part and stylized vocals complicate the task. However, for regular conversational speech, the project demonstrates excellent results: high accuracy even in conditions of strong noise (wind, background sounds, echo), thanks to the robustness of the Whisper model to real acoustic interference.
Technologies:
Python 3, faster-whisper (CTranslate2), FFmpeg (for conversion).
Repository:
https://github.com/fedyaqq34356/audio-to-txt.git
Features:
1) Support for various audio formats through automatic conversion to WAV using FFmpeg (mono, 16 kHz).
2) Use of the Whisper large model (customizable in size) for high recognition accuracy.
3) Decoding parameters (beam_size=20, best_of=10, temperature=0.2) for a balance between accuracy and speed.
4) Automatic detection of language and audio duration with logging.
5) Saving the transcription line by line in a text file (.txt).
6) Splitting large text into parts of 500 lines for easier further processing.
7) Detailed logging of all stages to a file for debugging.
8) Minimalist CLI interface: support for specifying the path to audio via command line argument.
9) Full modularity: separate modules for configuration, logging, conversion, transcription, and text splitting.
Example of operation:
When processing a song with vocals, the model attempts to transcribe the text, but due to the musical accompaniment, there are significant inaccuracies: repetitions of phrases, distortions of words, and hallucinations (for example, the repeated line "I'm not trying to be a fool"). This is expected, as Whisper is optimized primarily for speech rather than lyrics in music—the background instrumental part and stylized vocals complicate the task. However, for regular conversational speech, the project demonstrates excellent results: high accuracy even in conditions of strong noise (wind, background sounds, echo), thanks to the robustness of the Whisper model to real acoustic interference.
Technologies:
Python 3, faster-whisper (CTranslate2), FFmpeg (for conversion).
Repository:
https://github.com/fedyaqq34356/audio-to-txt.git