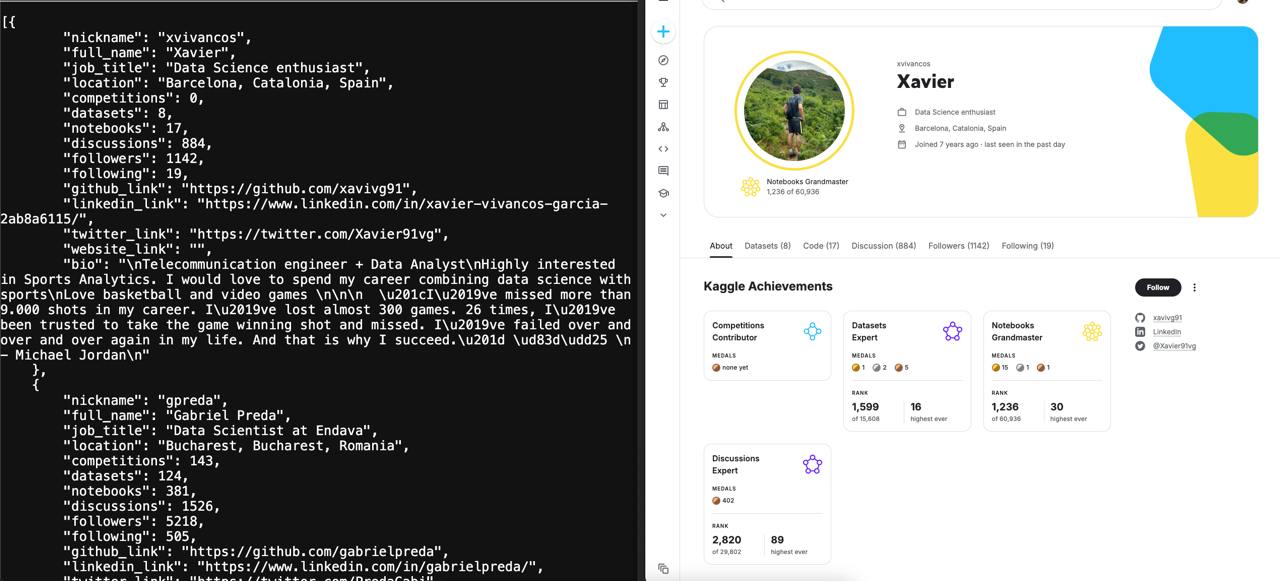
This project implements a web scraper based on Scrapy that automatically collects detailed information about Kaggle user profiles. It analyzes profile pages, extracts data about name, location, position, competition activity, datasets, notebooks, discussions, as well as information about followers and subscriptions. Additionally, the parser finds and classifies external links such as GitHub, LinkedIn, Twitter, or personal websites. Thanks to HTML processing features, the scraper correctly extracts biographical data. The project ensures efficient collection and structuring of data for further analysis of Kaggle user activity.