#Kubernetes #Security #Automation #GPT #DataAnalysis #DevSecOps #AI #PromptEngineering #BigData
Ten projekt ma na celu automatyzację analizy dużych raportów JSON dotyczących bezpieczeństwa Kubernetes (#Polaris, #Trivy, #Kubescape). Klientka potrzebowała wygodnego narzędzia do przekształcania surowych danych w użyteczny raport z kluczowymi wnioskami, najlepszymi praktykami, rekomendacjami i oceną dojrzałości. Wynik miał być gotowy do prezentacji dla publiczności technicznej i nietechnicznej.
Zadania i Wyzwania
• Przetwarzanie ogromnych ilości danych (#BigData) bez przekraczania kontekstu GPT.
• Oddzielne #Prompts dla każdego narzędzia w celu zwiększenia dokładności (#PromptEngineering).
• Zrównoważenie kosztów: początkowy poziom uogólnienia ma być tańszy (#gpt-3.5-turbo), końcowy — głębszy (#o1-mini), aby zachować jakość (#CostOptimization).
• Ihierarchiczne podejście (#HierarchicalAnalysis) i buforowanie (#Caching) w celu przyspieszenia ponownych uruchomień.
Rozwiązania
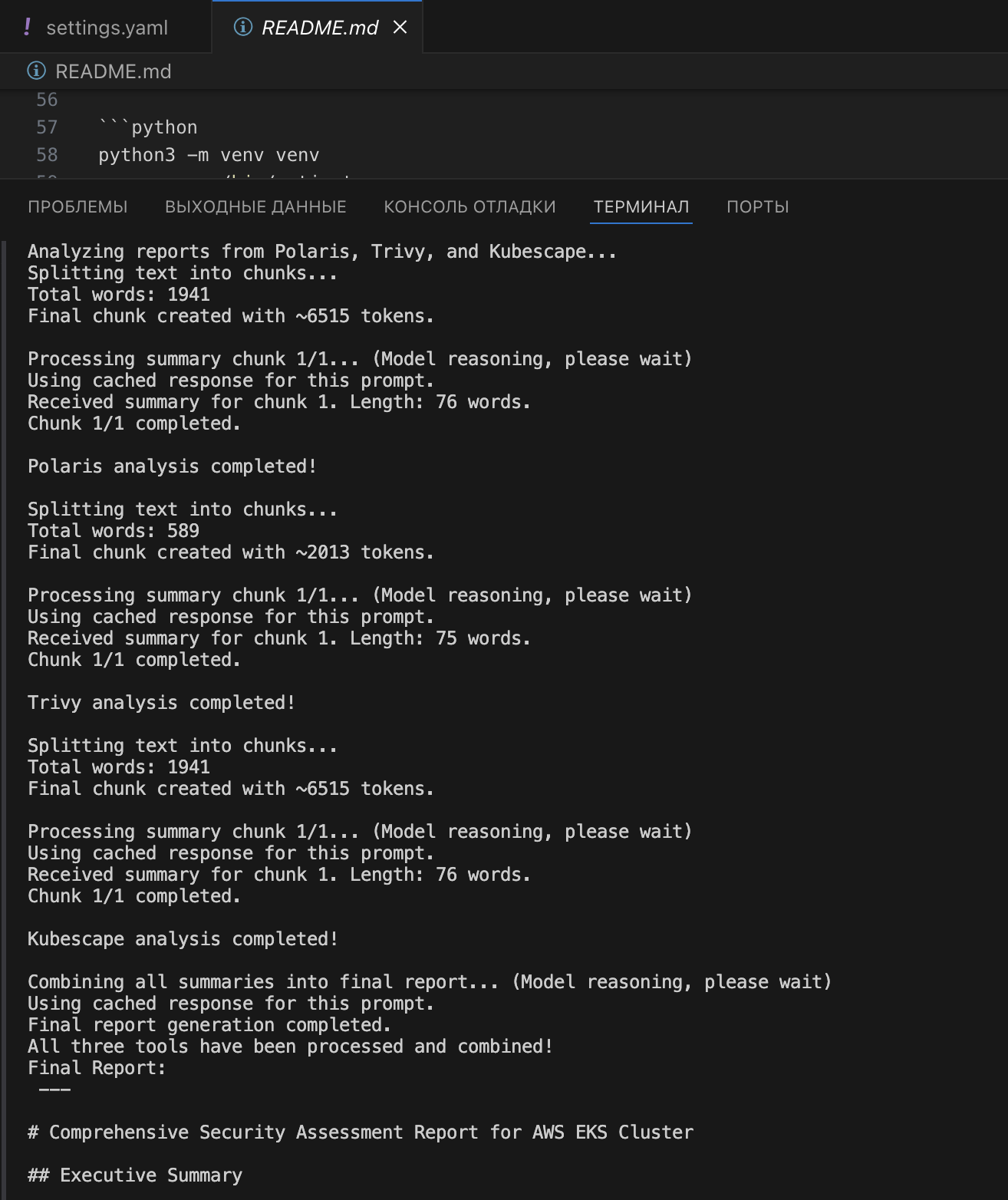
1. Ihierarchiczna analiza: Dane są dzielone na kawałki, uogólniane przez gpt-3.5-turbo, a następnie podsumowania trzech narzędzi łączone są przez o1-mini.
2. Oddzielne promty: Każde narzędzie ma swój promt, dostosowany do formatu danych (#Polaris, #Trivy, #Kubescape).
3. Buforowanie: Zmniejsza czas i koszty ponownych uruchomień.
4. Modularność: Kod podzielony na moduły, co uprościło przyszłe aktualizacje (#Modularity).
Wyniki
• Pełna automatyzacja analizy (#Automation): Ogromne pliki są przetwarzane bez pracy ręcznej.
• Optymalizacja kosztów (#CostEffective): Początkowe uogólnienia gpt-3.5-turbo są tanie, buforowanie szybkie.
• Jakościowy końcowy raport (#QualityOutput): Dzięki hybrydowemu podejściu i promtom raport jest dokładny, istotny i gotowy do prezentacji.
Wnioski
Ten przypadek demonstruje skuteczność #AI, #LLM i #PromptEngineering w zadaniach #DevSecOps i #DataAnalysis. Połączenie różnych modeli, hierarchiczna analiza, modularna architektura i jasna dokumentacja uczyniły rozwiązanie elastycznym, skalowalnym i ekonomicznym.
Ten projekt ma na celu automatyzację analizy dużych raportów JSON dotyczących bezpieczeństwa Kubernetes (#Polaris, #Trivy, #Kubescape). Klientka potrzebowała wygodnego narzędzia do przekształcania surowych danych w użyteczny raport z kluczowymi wnioskami, najlepszymi praktykami, rekomendacjami i oceną dojrzałości. Wynik miał być gotowy do prezentacji dla publiczności technicznej i nietechnicznej.
Zadania i Wyzwania
• Przetwarzanie ogromnych ilości danych (#BigData) bez przekraczania kontekstu GPT.
• Oddzielne #Prompts dla każdego narzędzia w celu zwiększenia dokładności (#PromptEngineering).
• Zrównoważenie kosztów: początkowy poziom uogólnienia ma być tańszy (#gpt-3.5-turbo), końcowy — głębszy (#o1-mini), aby zachować jakość (#CostOptimization).
• Ihierarchiczne podejście (#HierarchicalAnalysis) i buforowanie (#Caching) w celu przyspieszenia ponownych uruchomień.
Rozwiązania
1. Ihierarchiczna analiza: Dane są dzielone na kawałki, uogólniane przez gpt-3.5-turbo, a następnie podsumowania trzech narzędzi łączone są przez o1-mini.
2. Oddzielne promty: Każde narzędzie ma swój promt, dostosowany do formatu danych (#Polaris, #Trivy, #Kubescape).
3. Buforowanie: Zmniejsza czas i koszty ponownych uruchomień.
4. Modularność: Kod podzielony na moduły, co uprościło przyszłe aktualizacje (#Modularity).
Wyniki
• Pełna automatyzacja analizy (#Automation): Ogromne pliki są przetwarzane bez pracy ręcznej.
• Optymalizacja kosztów (#CostEffective): Początkowe uogólnienia gpt-3.5-turbo są tanie, buforowanie szybkie.
• Jakościowy końcowy raport (#QualityOutput): Dzięki hybrydowemu podejściu i promtom raport jest dokładny, istotny i gotowy do prezentacji.
Wnioski
Ten przypadek demonstruje skuteczność #AI, #LLM i #PromptEngineering w zadaniach #DevSecOps i #DataAnalysis. Połączenie różnych modeli, hierarchiczna analiza, modularna architektura i jasna dokumentacja uczyniły rozwiązanie elastycznym, skalowalnym i ekonomicznym.