NeuroLabirynt — platforma równoległego uczenia się agentów
AI i uczenie maszynowe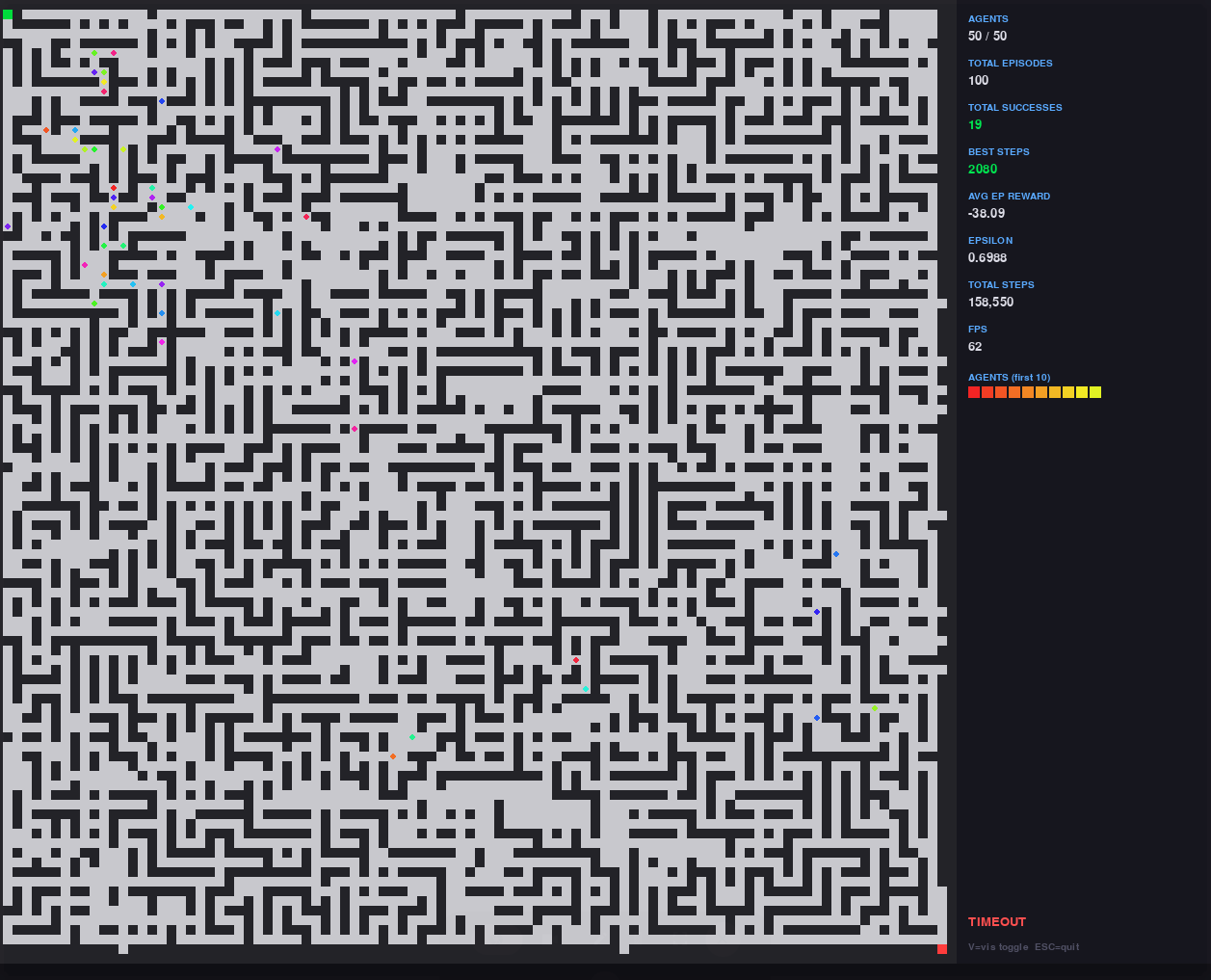
To jest wysoko wydajny system uczenia się z wzmocnieniem, zbudowany wokół wieloagentowego środowiska Maze RL, zoptymalizowany pod kątem rzeczywistych obciążeń obliczeniowych i skalowania.
Projekt realizuje całkowicie wektorową symulację, w której jednocześnie uczy się dziesiątki agentów w tym samym środowisku. Architektura została specjalnie zaprojektowana, aby odejść od klasycznego podejścia single-agent i zastąpić je równoległym uczeniem się w wspólnym środowisku, co radykalnie zwiększa efektywność wykorzystania zasobów obliczeniowych.
Każdy agent działa niezależnie, ale w ramach jednego środowiska, co pozwala modelować konkurencyjne i kolektywne zachowanie jednocześnie. System wspiera przetwarzanie wsadowe obserwacji i działań, gdzie wszyscy agenci przechodzą forward pass jedną operacją, bez N oddzielnych wywołań modelu. To daje znaczący wzrost wydajności i czyni system odpowiednim do skalowania do setek agentów.
Środowisko zbudowane jest na proceduralnej generacji skomplikowanych labiryntów z kontrolowaną entropią strukturalną: cykle, pułapki, ślepe zaułki, fałszywe ścieżki i wąskie korytarze. To tworzy bogatą przestrzeń do uczenia się, gdzie agent nie może polegać na trywialnych strategiach i musi formować stabilną politykę nawigacji.
System wspiera dynamiczną wizualizację na Pygame, gdzie jednocześnie wyświetlane są wszystkie agenty w czasie rzeczywistym, w tym ich pozycje, postęp i zebrane statystyki uczenia. W razie potrzeby wizualizacja jest wyłączana, a system przechodzi w tryb headless o wysokiej prędkości, osiągając tysiące kroków agenta na sekundę na CPU.
Uczenie oparte jest na architekturze DQN z buforem replay, siecią docelową i epsilon decay, dostosowanymi do trybu wieloagentowego. Zamiast klasycznego epizodycznego cyklu stosuje się trening krokowy w strumieniu, gdzie aktualizacje modelu odbywają się nieprzerwanie w miarę napływu doświadczeń od wszystkich agentów.
W rezultacie powstaje system, który jednocześnie jest platformą badawczą i narzędziem inżynieryjnym: demonstruje zachowanie skomplikowanych agentów RL w warunkach gęstej paralelizacji, pozwala testować strategie skalowania i wizualnie obserwować kolektywne uczenie się w czasie rzeczywistym.
W istocie to nie tylko symulator agenta, ale pełnoprawne środowisko do opracowywania i testowania stresowego algorytmów uczenia się z wzmocnieniem w scenariuszach wieloagentowych o wysokiej gęstości interakcji.
Projekt realizuje całkowicie wektorową symulację, w której jednocześnie uczy się dziesiątki agentów w tym samym środowisku. Architektura została specjalnie zaprojektowana, aby odejść od klasycznego podejścia single-agent i zastąpić je równoległym uczeniem się w wspólnym środowisku, co radykalnie zwiększa efektywność wykorzystania zasobów obliczeniowych.
Każdy agent działa niezależnie, ale w ramach jednego środowiska, co pozwala modelować konkurencyjne i kolektywne zachowanie jednocześnie. System wspiera przetwarzanie wsadowe obserwacji i działań, gdzie wszyscy agenci przechodzą forward pass jedną operacją, bez N oddzielnych wywołań modelu. To daje znaczący wzrost wydajności i czyni system odpowiednim do skalowania do setek agentów.
Środowisko zbudowane jest na proceduralnej generacji skomplikowanych labiryntów z kontrolowaną entropią strukturalną: cykle, pułapki, ślepe zaułki, fałszywe ścieżki i wąskie korytarze. To tworzy bogatą przestrzeń do uczenia się, gdzie agent nie może polegać na trywialnych strategiach i musi formować stabilną politykę nawigacji.
System wspiera dynamiczną wizualizację na Pygame, gdzie jednocześnie wyświetlane są wszystkie agenty w czasie rzeczywistym, w tym ich pozycje, postęp i zebrane statystyki uczenia. W razie potrzeby wizualizacja jest wyłączana, a system przechodzi w tryb headless o wysokiej prędkości, osiągając tysiące kroków agenta na sekundę na CPU.
Uczenie oparte jest na architekturze DQN z buforem replay, siecią docelową i epsilon decay, dostosowanymi do trybu wieloagentowego. Zamiast klasycznego epizodycznego cyklu stosuje się trening krokowy w strumieniu, gdzie aktualizacje modelu odbywają się nieprzerwanie w miarę napływu doświadczeń od wszystkich agentów.
W rezultacie powstaje system, który jednocześnie jest platformą badawczą i narzędziem inżynieryjnym: demonstruje zachowanie skomplikowanych agentów RL w warunkach gęstej paralelizacji, pozwala testować strategie skalowania i wizualnie obserwować kolektywne uczenie się w czasie rzeczywistym.
W istocie to nie tylko symulator agenta, ale pełnoprawne środowisko do opracowywania i testowania stresowego algorytmów uczenia się z wzmocnieniem w scenariuszach wieloagentowych o wysokiej gęstości interakcji.