Panel wyników parsera dla systemów zbierania danych
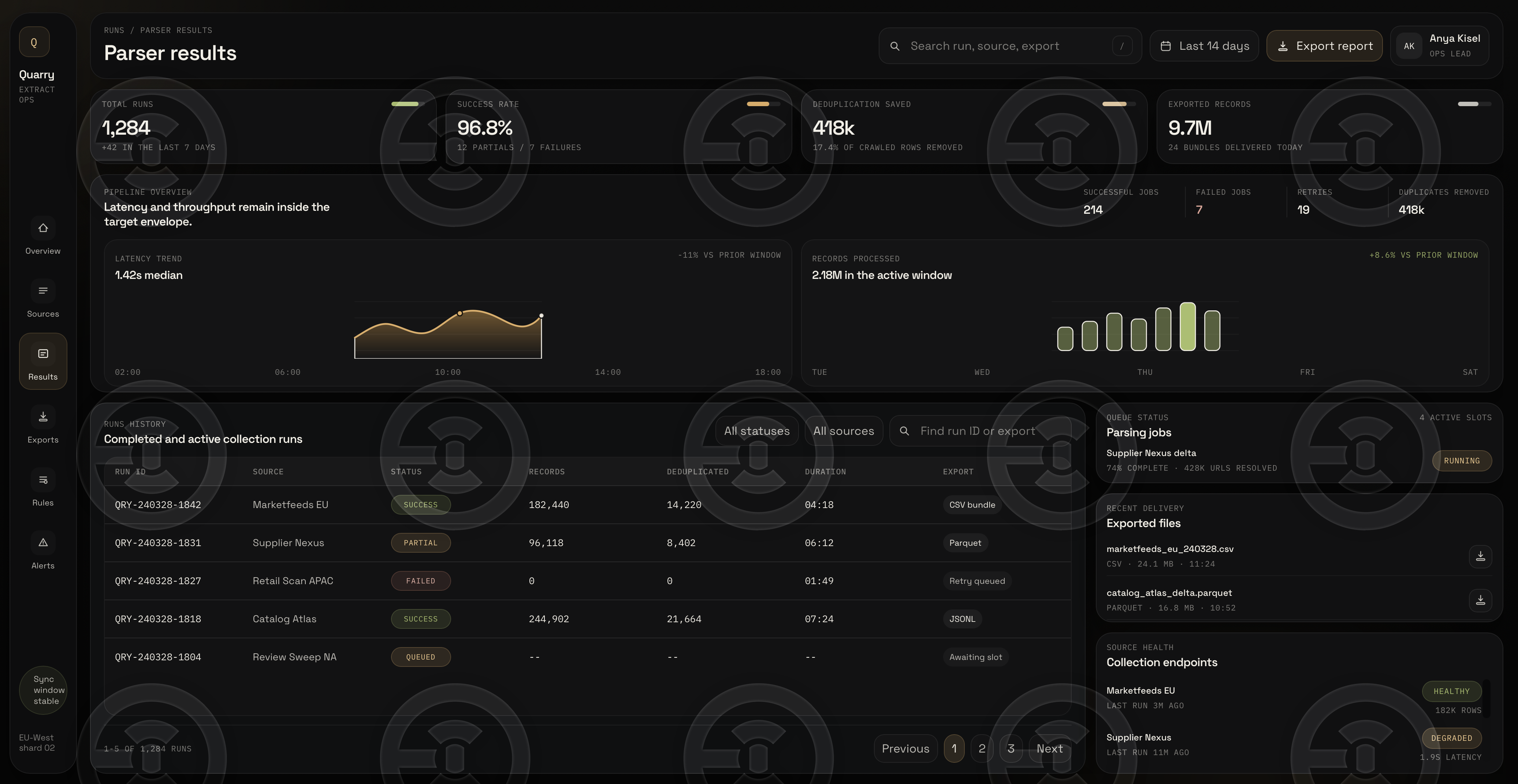
Opracowanie systemu dashboard do monitorowania wyników parsowania i kontroli pipeline'u zbierania danych. Projekt został zrealizowany jako pełnoprawny interfejs produktu wewnętrznego do pracy z dużymi ilościami danych: śledzenie uruchomień, statusów, deduplikacji, opóźnień, przepustowości, eksportów i stanu źródeł w jednym obszarze roboczym.
Główny nacisk został położony nie tylko na część wizualną, ale także na wygodę pracy z metrykami operacyjnymi, przepływem rekordów, statusem kolejki i wynikami przetwarzania danych. Interfejs został zaprojektowany tak, aby szybko zobaczyć stan pipeline'u, problematyczne źródła, skuteczność eksportów i ogólną efektywność systemu.
Co zostało zrealizowane:
#dashboard #datapipeline #parsing #analytics #frontend #internaltools
— dashboard do monitorowania wyników parsera i uruchomień zbierania danych
— bloki KPI dotyczące całkowitych uruchomień, wskaźnika sukcesu, deduplikacji i eksportowanych rekordów
— przegląd opóźnień / przepustowości i analizy przetworzonych danych
— tabela historii uruchomień ze statusami, czasem trwania, typem eksportu i przepływem wyszukiwania/filtracji
— bloki statusu kolejki, eksportowanych plików i zdrowia źródła
— strukturalny ciemny interfejs użytkownika do operacji na danych wewnętrznych
— interfejs w stylu produktu dla systemów parsera / ETL / workflow zbierania danych
Główny nacisk został położony nie tylko na część wizualną, ale także na wygodę pracy z metrykami operacyjnymi, przepływem rekordów, statusem kolejki i wynikami przetwarzania danych. Interfejs został zaprojektowany tak, aby szybko zobaczyć stan pipeline'u, problematyczne źródła, skuteczność eksportów i ogólną efektywność systemu.
Co zostało zrealizowane:
#dashboard #datapipeline #parsing #analytics #frontend #internaltools
— dashboard do monitorowania wyników parsera i uruchomień zbierania danych
— bloki KPI dotyczące całkowitych uruchomień, wskaźnika sukcesu, deduplikacji i eksportowanych rekordów
— przegląd opóźnień / przepustowości i analizy przetworzonych danych
— tabela historii uruchomień ze statusami, czasem trwania, typem eksportu i przepływem wyszukiwania/filtracji
— bloki statusu kolejki, eksportowanych plików i zdrowia źródła
— strukturalny ciemny interfejs użytkownika do operacji na danych wewnętrznych
— interfejs w stylu produktu dla systemów parsera / ETL / workflow zbierania danych
 Kijów
Kijów