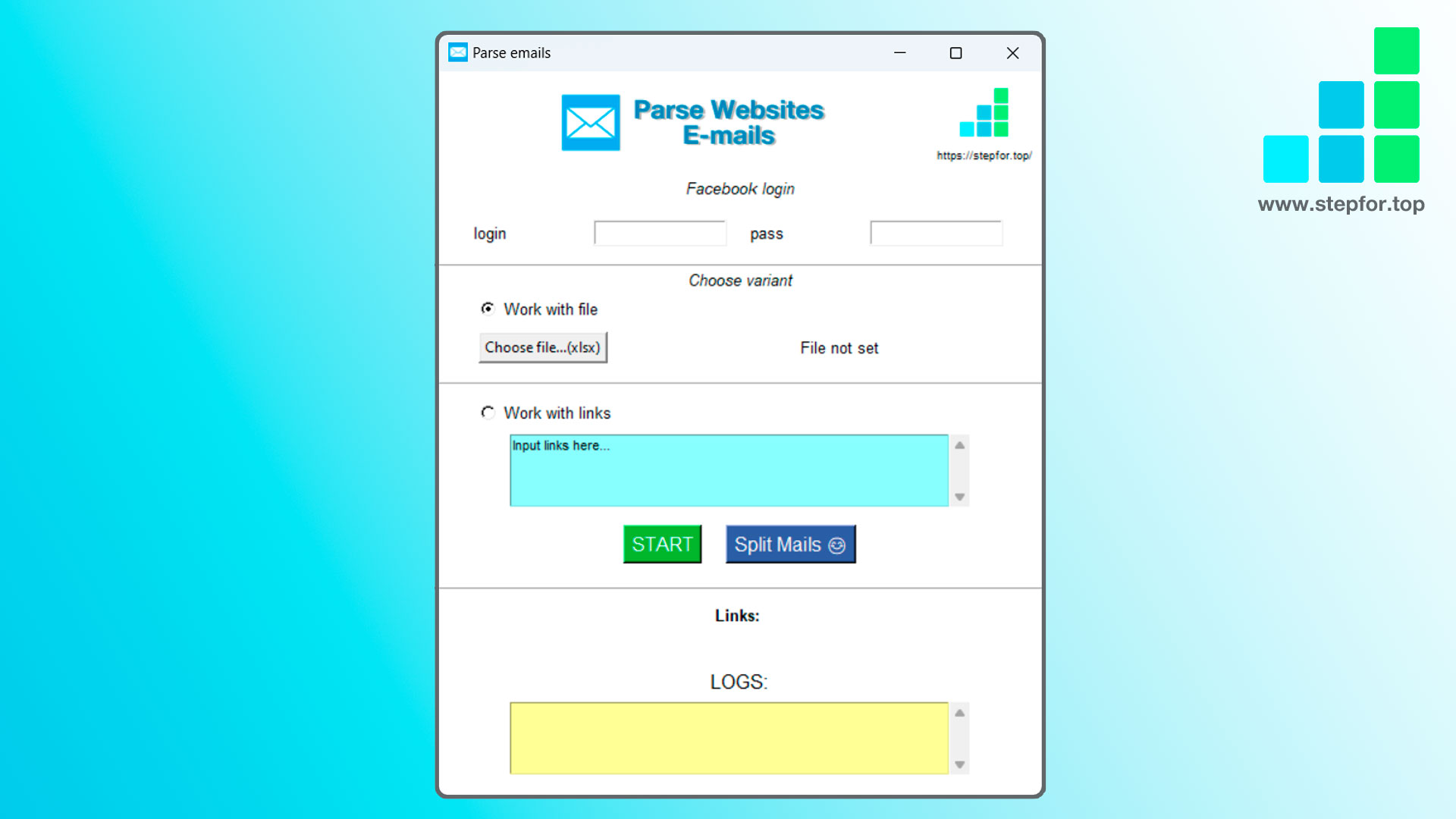
#Parser #emails zbiera wiadomości e-mail z listy linków do dowolnej strony internetowej.
Jest zaimplementowany w Python + Selenium (najbardziej wydajna opcja).
Wyszukiwanie odbywa się na samej stronie, stronie kontaktów (pod warunkiem, że nazwa strony zawiera słowo "kontakt") i stronie zespołu. Listę takich stron można dodać samodzielnie)
Program pobiera dane do parsowania:
1. Przesłany plik Excel (najważniejsze jest to, że powinien mieć kolumnę o nazwie Strona, dodatkowo (niekoniecznie) może być kolumna o nazwie Nazwa).
2. Wystarczy skopiować i wkleić listę linków do strony
Program loguje się do konta na Facebooku, aby móc zbierać maile również ze stron na Facebooku, dlatego program udostępnia pola login i pass. Nie jest to warunek konieczny. Można pozostawić je puste.
Ważne: Wiadomości e-mail w ramach jednej witryny są zbierane bez duplikatów, z wyłączeniem najczęściej fałszywych wiadomości e-mail. Istnieje również wbudowane obejście różnych typów wiadomości e-mail zabezpieczonych parserem.
Wynikiem jest plik Excel:
- nazwa firmy (pod warunkiem, że nazwa ta była obecna w oryginalnym pliku excel w kolumnie Nazwa)
- strona internetowa
- wszystkie znalezione e-maile na stronie internetowej oddzielone przecinkami
- link do strony na Facebooku
- link do strony LinkedIn
Dzielenie wiadomości e-mail: Dodatkowo dostępna jest funkcja rozdzielania maili (zebranych dla jednej firmy) przecinkiem - jeden mail w wierszu. Przyda się to przy masowych kampaniach mailowych.
P.S.
Osobno dostępna jest opcja Python + requests oraz inny, najszybszy, asynchroniczny parser dla dużych zbiorów danych.
Jest zaimplementowany w Python + Selenium (najbardziej wydajna opcja).
Wyszukiwanie odbywa się na samej stronie, stronie kontaktów (pod warunkiem, że nazwa strony zawiera słowo "kontakt") i stronie zespołu. Listę takich stron można dodać samodzielnie)
Program pobiera dane do parsowania:
1. Przesłany plik Excel (najważniejsze jest to, że powinien mieć kolumnę o nazwie Strona, dodatkowo (niekoniecznie) może być kolumna o nazwie Nazwa).
2. Wystarczy skopiować i wkleić listę linków do strony
Program loguje się do konta na Facebooku, aby móc zbierać maile również ze stron na Facebooku, dlatego program udostępnia pola login i pass. Nie jest to warunek konieczny. Można pozostawić je puste.
Ważne: Wiadomości e-mail w ramach jednej witryny są zbierane bez duplikatów, z wyłączeniem najczęściej fałszywych wiadomości e-mail. Istnieje również wbudowane obejście różnych typów wiadomości e-mail zabezpieczonych parserem.
Wynikiem jest plik Excel:
- nazwa firmy (pod warunkiem, że nazwa ta była obecna w oryginalnym pliku excel w kolumnie Nazwa)
- strona internetowa
- wszystkie znalezione e-maile na stronie internetowej oddzielone przecinkami
- link do strony na Facebooku
- link do strony LinkedIn
Dzielenie wiadomości e-mail: Dodatkowo dostępna jest funkcja rozdzielania maili (zebranych dla jednej firmy) przecinkiem - jeden mail w wierszu. Przyda się to przy masowych kampaniach mailowych.
P.S.
Osobno dostępna jest opcja Python + requests oraz inny, najszybszy, asynchroniczny parser dla dużych zbiorów danych.