Scraper для Отримання Заголовків (Title) із Вебсторінок
Парсинг даних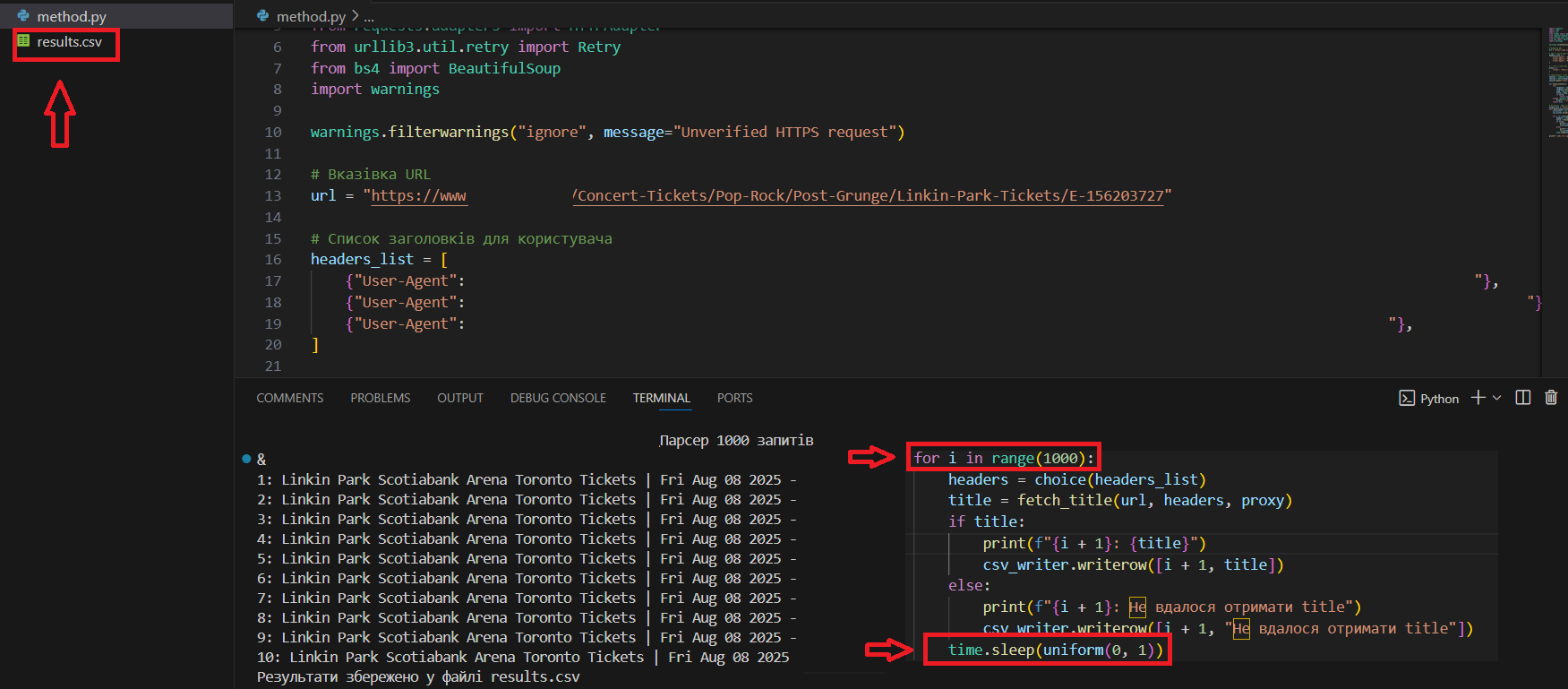
Цей проєкт представляє собою Python-скрипт для веб-скрапінгу, що автоматично отримує заголовки вебсторінок ( теги) з URL-адреси, використовуючи бібліотеки requests та BeautifulSoup. Основна мета проєкту — зібрати інформацію з цільового сайту та зберегти результати у файл CSV для подальшого аналізу.
Скрипт було створено з урахуванням важливих аспектів безпеки та ефективності, включаючи ротацію заголовків User-Agent, використання проксі-сервера та повторні спроби підключення у разі невдалих запитів.
Ключові можливості:
Отримання заголовків:
Автоматичний парсинг тега із вказаної URL-адреси.
Перевірка успішності запиту та обробка виключень.
Ротація заголовків User-Agent:
Використання різних User-Agent для імітації запитів із різних пристроїв та браузерів.
Зменшення ризику блокування при надсиланні запитів.
Підтримка проксі-сервера:
Додавання проксі для обходу географічних обмежень та забезпечення анонімності запитів.
Обробка винятків:
Використання механізму повторних спроб при виникненні тимчасових помилок (500, 502, 503, 504).
Обробка помилок з’єднання та інших непередбачених ситуацій.
Збереження результатів:
Усі отримані заголовки зберігаються у CSV-файл у структурованому форматі (номер запиту та відповідний заголовок).
Динамічна затримка між запитами:
Реалізація випадкової затримки для імітації поведінки користувача.
Технології:
Python — основна мова програмування.
requests — для HTTP-запитів.
BeautifulSoup — для парсингу HTML-документів.
csv — для роботи з даними у форматі CSV.
random — для генерації випадкових затримок та ротації заголовків.
aiohttp — для роботи з асинхронними HTTP-запитами (у майбутньому можна інтегрувати для підвищення продуктивності).
Практичне застосування:
Збір даних для SEO: Отримання заголовків із вебсторінок для аналізу метаданих.
Моніторинг вебсайтів: Відстеження змін у заголовках сторінок.
Аналіз конкурентів: Збір інформації з цільових ресурсів для маркетингових досліджень.
Скрипт було створено з урахуванням важливих аспектів безпеки та ефективності, включаючи ротацію заголовків User-Agent, використання проксі-сервера та повторні спроби підключення у разі невдалих запитів.
Ключові можливості:
Отримання заголовків:
Автоматичний парсинг тега із вказаної URL-адреси.
Перевірка успішності запиту та обробка виключень.
Ротація заголовків User-Agent:
Використання різних User-Agent для імітації запитів із різних пристроїв та браузерів.
Зменшення ризику блокування при надсиланні запитів.
Підтримка проксі-сервера:
Додавання проксі для обходу географічних обмежень та забезпечення анонімності запитів.
Обробка винятків:
Використання механізму повторних спроб при виникненні тимчасових помилок (500, 502, 503, 504).
Обробка помилок з’єднання та інших непередбачених ситуацій.
Збереження результатів:
Усі отримані заголовки зберігаються у CSV-файл у структурованому форматі (номер запиту та відповідний заголовок).
Динамічна затримка між запитами:
Реалізація випадкової затримки для імітації поведінки користувача.
Технології:
Python — основна мова програмування.
requests — для HTTP-запитів.
BeautifulSoup — для парсингу HTML-документів.
csv — для роботи з даними у форматі CSV.
random — для генерації випадкових затримок та ротації заголовків.
aiohttp — для роботи з асинхронними HTTP-запитами (у майбутньому можна інтегрувати для підвищення продуктивності).
Практичне застосування:
Збір даних для SEO: Отримання заголовків із вебсторінок для аналізу метаданих.
Моніторинг вебсайтів: Відстеження змін у заголовках сторінок.
Аналіз конкурентів: Збір інформації з цільових ресурсів для маркетингових досліджень.