Smart Chunker: підготовка документів для RAG і векторних баз
AI та машинне навчання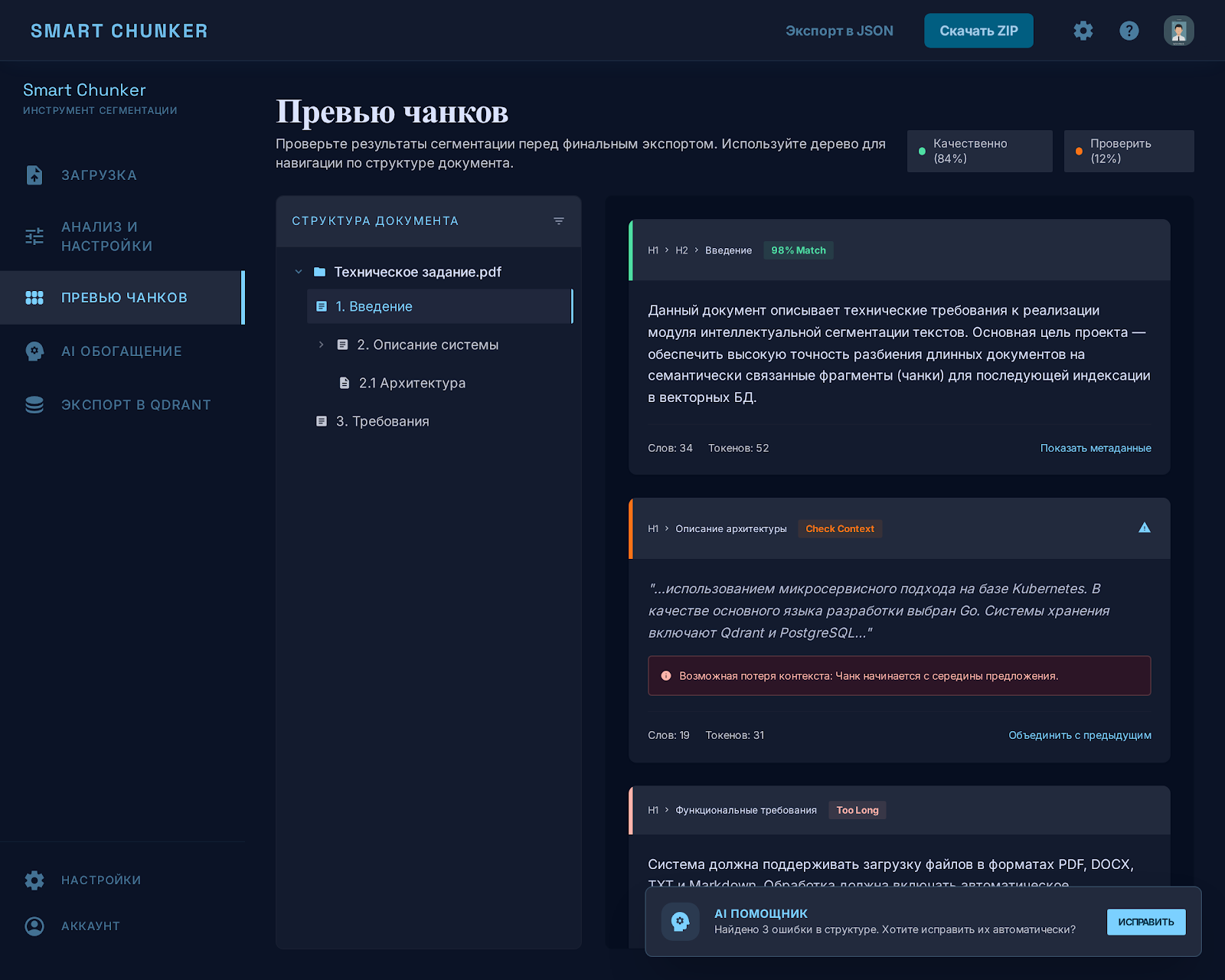
AI-агент відповідає настільки добре, наскільки підготовлений його контекст. Щоб готувати велику базу знань до RAG, я зробив Smart Chunker: він ріже Markdown на змістовні чанки, показує проблемні місця і вантажить готові дані у векторну базу. Перед пошуком знання приведені до нормального вигляду, без обірваних фрагментів і дублів.
Що всередині:
- Детерміноване ядро: розбір Markdown у дерево заголовків H1-H3 і 7 правил чанкінгу, без overlap.
- Автопідбір розмірів чанків перебором сітки до 2500 комбінацій.
- Контроль якості видно в інтерфейсі: проблемні чанки підсвічуються, система підказує, що поправити.
- AI-шар: архітектор пропонує схему метаданих, агент збагачує чанки пакетами, результат проходить валідацію.
- Завантаження у Qdrant: dense-вектори через embeddings, sparse через локальний BM25, оновлення через Smart Match. 20 API-точок.
API-ключі живуть тільки в браузері й не зберігаються на сервері. Базовий чанкінг працює і без зовнішніх моделей.
#Python #RAG #Qdrant #FastAPI #AI #VectorDB #LLM #NLP #VanillaJS #OpenAI #Anthropic #BM25 #SSE
Що всередині:
- Детерміноване ядро: розбір Markdown у дерево заголовків H1-H3 і 7 правил чанкінгу, без overlap.
- Автопідбір розмірів чанків перебором сітки до 2500 комбінацій.
- Контроль якості видно в інтерфейсі: проблемні чанки підсвічуються, система підказує, що поправити.
- AI-шар: архітектор пропонує схему метаданих, агент збагачує чанки пакетами, результат проходить валідацію.
- Завантаження у Qdrant: dense-вектори через embeddings, sparse через локальний BM25, оновлення через Smart Match. 20 API-точок.
API-ключі живуть тільки в браузері й не зберігаються на сервері. Базовий чанкінг працює і без зовнішніх моделей.
#Python #RAG #Qdrant #FastAPI #AI #VectorDB #LLM #NLP #VanillaJS #OpenAI #Anthropic #BM25 #SSE