Eval-Lab — Regression of prompts and models
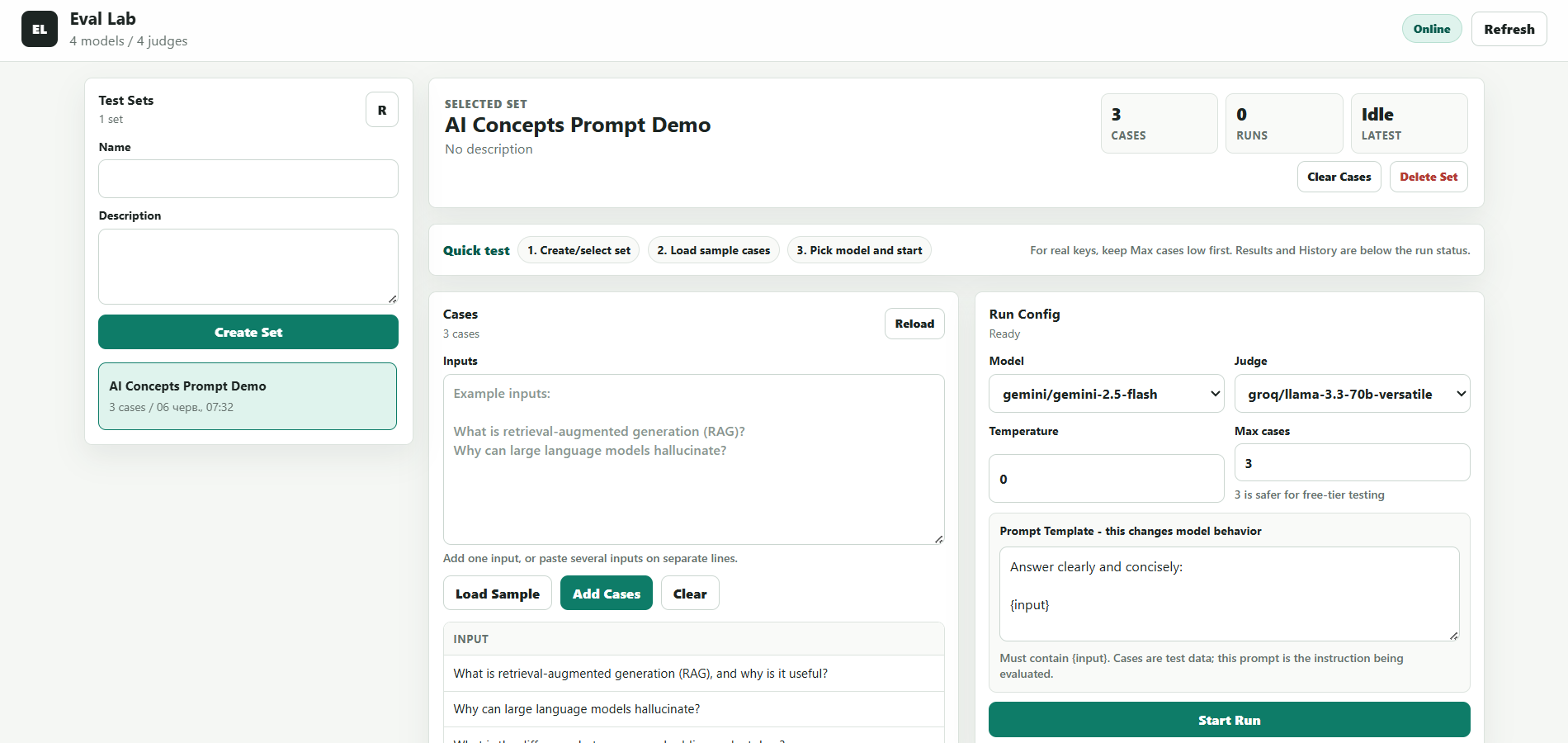
Web dashboard for regression testing of prompts and models. Running a test set through two models/prompts — comparison based on 4 sub-scores.
Technically interesting aspects:
— LLM-as-judge through 5 providers (OpenRouter, Anthropic via tool-use, Gemini, Groq, mock)
— 4 sub-scores for each case: correctness, relevance, completeness, prompt_quality
— Cap on final score for poor prompt — prevents strong model from masking poor prompt
— Per-provider throttle and retry with backoff + Retry-After
— Mock mode for running without API keys (CI-friendly, $0)
— Editing secrets in logs
Stack: FastAPI, async SQLAlchemy, Alembic, httpx, Pydantic, vanilla JS, Docker.
Technically interesting aspects:
— LLM-as-judge through 5 providers (OpenRouter, Anthropic via tool-use, Gemini, Groq, mock)
— 4 sub-scores for each case: correctness, relevance, completeness, prompt_quality
— Cap on final score for poor prompt — prevents strong model from masking poor prompt
— Per-provider throttle and retry with backoff + Retry-After
— Mock mode for running without API keys (CI-friendly, $0)
— Editing secrets in logs
Stack: FastAPI, async SQLAlchemy, Alembic, httpx, Pydantic, vanilla JS, Docker.
 Lvov
Lvov