Eval-Lab — Regresja promptów i modeli
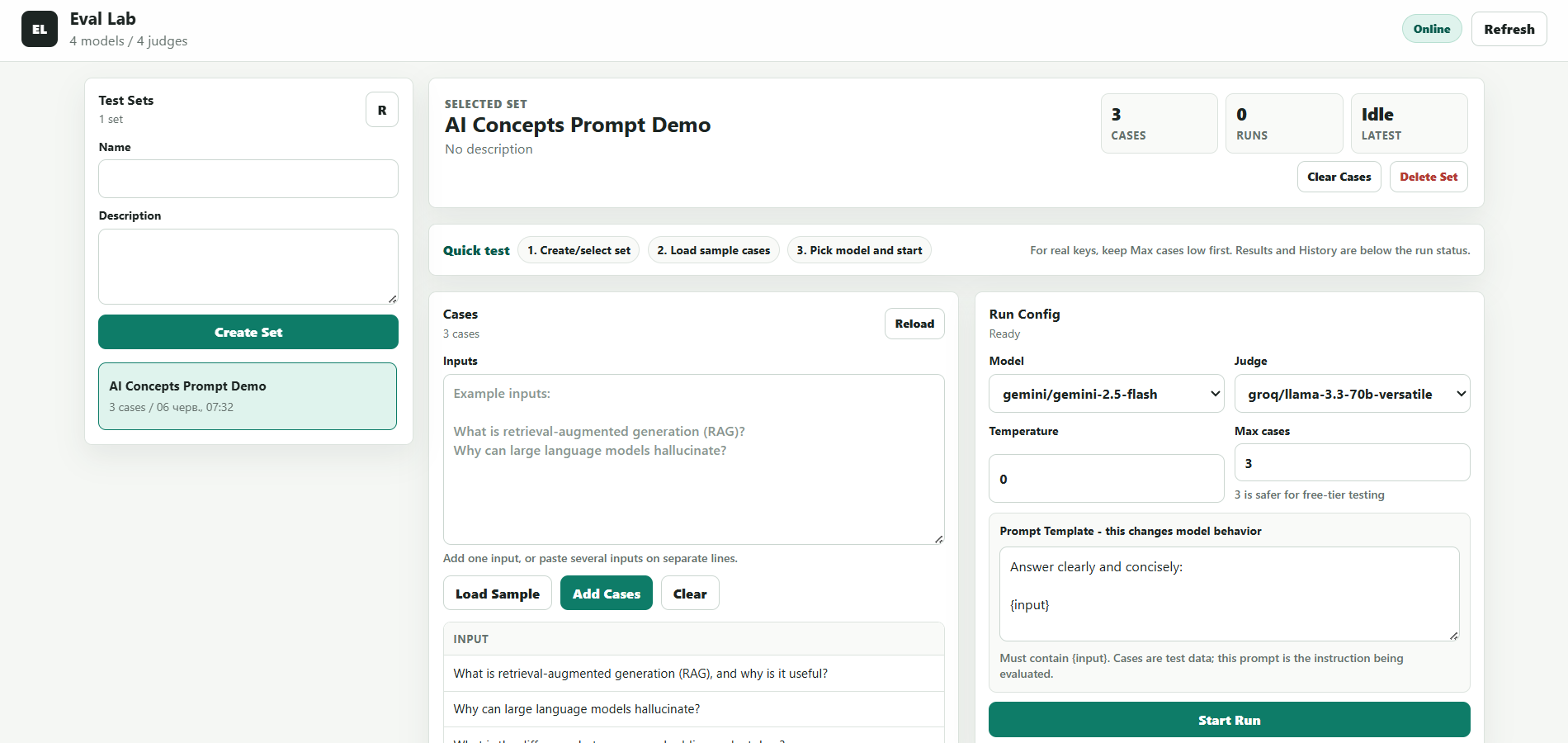
Dashboard internetowy do regresyjnego testowania promptów i modeli. Uruchomienie zestawu testowego przez dwa modele/prompt — porównanie według 4 pod-ocen.
Co ciekawego technicznie:
— LLM-as-judge przez 5 dostawców (OpenRouter, Anthropic przez tool-use, Gemini, Groq, mock)
— 4 pod-oceny każdego przypadku: poprawność, trafność, kompletność, jakość promptu
— Ograniczenie końcowego wyniku przy złym promcie — nie pozwala silnemu modelowi zamaskować złego promptu
— Ograniczenie i ponowne próby na poziomie dostawcy z backoff + Retry-After
— Tryb mock do uruchamiania bez kluczy API (przyjazny CI, $0)
— Edycja sekretów w logach
Stos: FastAPI, async SQLAlchemy, Alembic, httpx, Pydantic, vanilla JS, Docker.
Co ciekawego technicznie:
— LLM-as-judge przez 5 dostawców (OpenRouter, Anthropic przez tool-use, Gemini, Groq, mock)
— 4 pod-oceny każdego przypadku: poprawność, trafność, kompletność, jakość promptu
— Ograniczenie końcowego wyniku przy złym promcie — nie pozwala silnemu modelowi zamaskować złego promptu
— Ograniczenie i ponowne próby na poziomie dostawcy z backoff + Retry-After
— Tryb mock do uruchamiania bez kluczy API (przyjazny CI, $0)
— Edycja sekretów w logach
Stos: FastAPI, async SQLAlchemy, Alembic, httpx, Pydantic, vanilla JS, Docker.
 Lwów
Lwów