Industrial tennis data parser Sofascore
#Parsing #Python #Automation #DataScience #Sofascore #Scraper
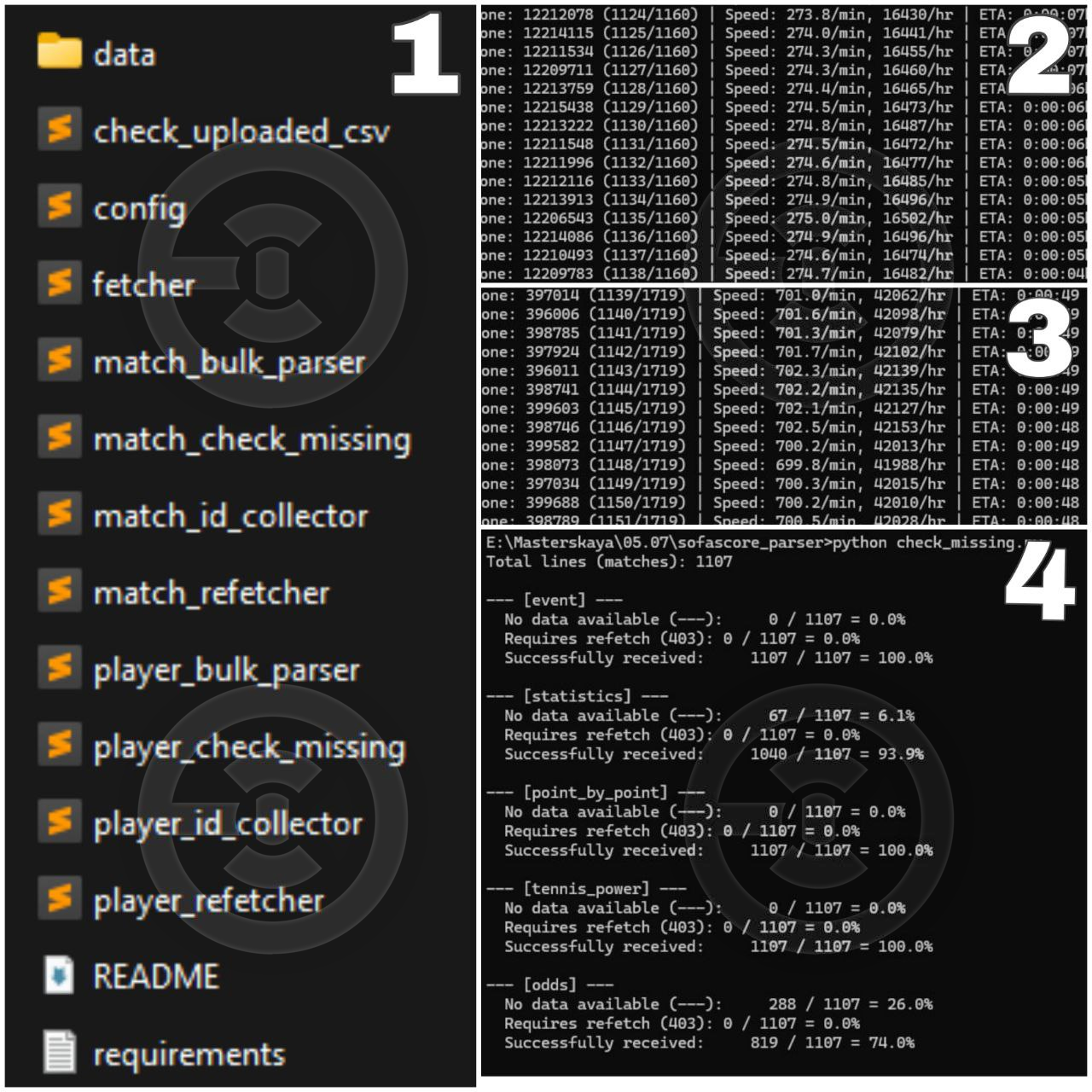
Created a modular library [see photo 1] and a set of Python scripts for automated data collection of all tennis matches and players from the Sofascore website.
Features:
- Collects all historical and upcoming matches within a date range (id, statistics, points, odds, player strength).
- Parses information for each player and their rating.
- Built-in anti-bot protection: automatic proxy rotation, dynamic user-agent, cookies.
- Multithreading: configurable via settings, speeds up collection (16,400 matches/hour [see photo 2] and 42,000 players/hour [see photo 3]).
- Smart retry system and automatic re-fetch of missing data (403, 429) [see photo 4].
- All settings are managed through the config.py file (dates, proxies, threads, delays).
- Export: clean CSV files, fully compatible with pandas, ready for ML and analytics.
- Logs, progress bar, ETA (remaining time), speed output per minute/hour.
- Detailed documentation in Russian and English, with code and console run examples.
Result:
The project was successfully implemented for the client, with a fully automated data collection and update process, ensuring high speed and stability even with large volumes.
Stack: Python 3.11+, curl_cffi, pandas, threading, proxies.
Created a modular library [see photo 1] and a set of Python scripts for automated data collection of all tennis matches and players from the Sofascore website.
Features:
- Collects all historical and upcoming matches within a date range (id, statistics, points, odds, player strength).
- Parses information for each player and their rating.
- Built-in anti-bot protection: automatic proxy rotation, dynamic user-agent, cookies.
- Multithreading: configurable via settings, speeds up collection (16,400 matches/hour [see photo 2] and 42,000 players/hour [see photo 3]).
- Smart retry system and automatic re-fetch of missing data (403, 429) [see photo 4].
- All settings are managed through the config.py file (dates, proxies, threads, delays).
- Export: clean CSV files, fully compatible with pandas, ready for ML and analytics.
- Logs, progress bar, ETA (remaining time), speed output per minute/hour.
- Detailed documentation in Russian and English, with code and console run examples.
Result:
The project was successfully implemented for the client, with a fully automated data collection and update process, ensuring high speed and stability even with large volumes.
Stack: Python 3.11+, curl_cffi, pandas, threading, proxies.
 Dnepr
Dnepr