Persistent Vector Memory for Claude Code: Open-Source MCP Server
AI & Machine Learning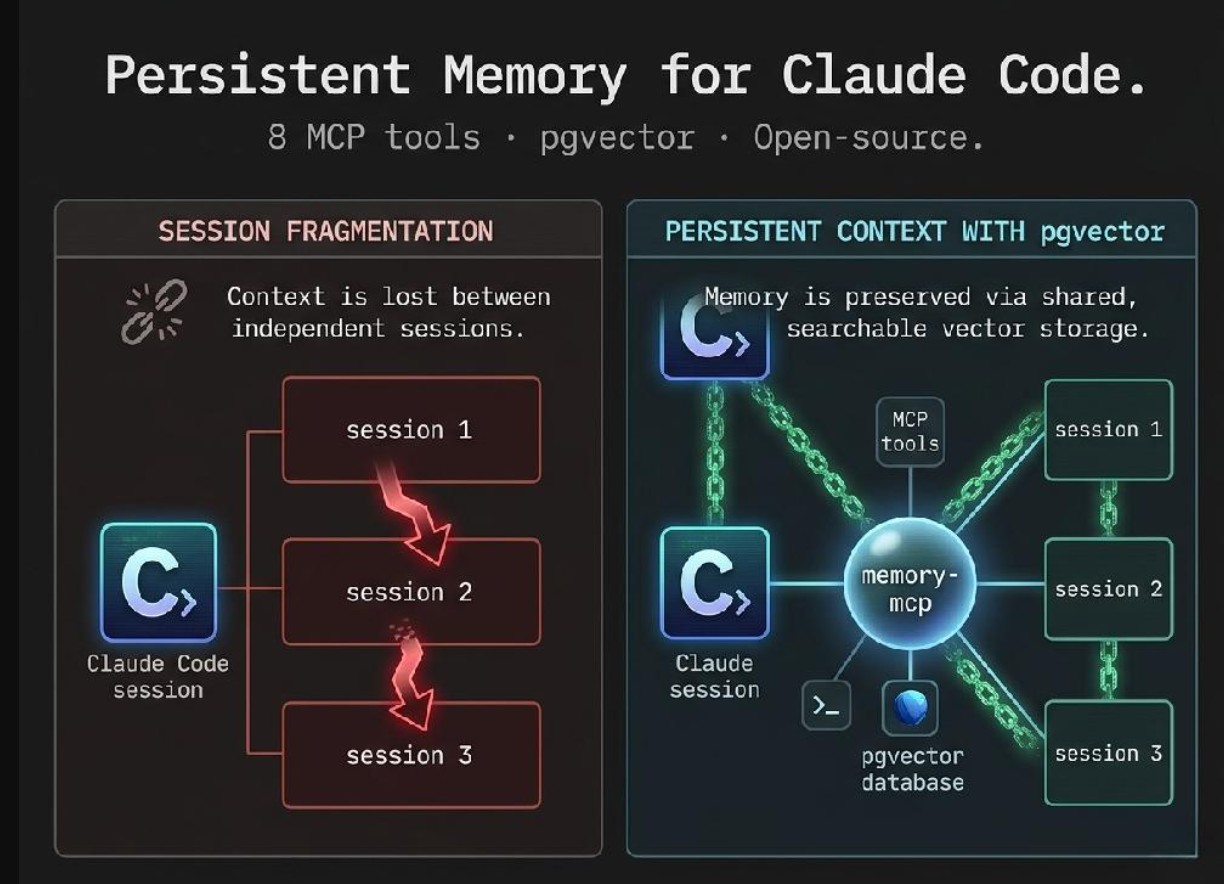
The Situation
Claude Code is a powerful AI coding assistant, but it is stateless by design. Every new session starts without knowledge of past decisions, bugs, or architecture. In real production work, this leads to constant repetition, lost context, and slower development.
The Problem
The fundamental issue: the AI assistant helping build a project has no memory of building it. I was rediscovering the same bugs, re-explaining the same architecture, and losing decisions made last week. A secondary problem: recurring patterns across projects (like "we have set up Supabase this exact way 4 times") stayed buried in session memories instead of becoming reusable, documented skills.
The Solution
I built memory-mcp, an open-source MCP server that gives Claude Code long-term semantic memory. It exposes 8 tools: 4 core memory tools (remember, recall, forget, project_status) and 4 skill-pattern tools that track recurring work patterns and surface candidates for formalization once seen 3+ times.
Memories store as 1536-dimension vector embeddings (OpenAI text-embedding-3-small) in Supabase PostgreSQL with pgvector. Retrieval runs a cosine-similarity search via a Postgres RPC function with SQL-level filtering (threshold, project, type, date, expiration) in a single round trip. Recall responses are token-capped at ~2000 tokens to protect Claude's context window.
The server runs as a stateless Docker container on port 3101 via Express + Streamable HTTP transport, so multiple Claude Code sessions share one always-on instance. A stdio transport mode is also available for direct native-binary integration. Memories never hard-delete: forget is a soft-delete via expires_at, and every query filters on active-memory status.
Tech Stack: Node.js 20, TypeScript 5 (strict), Express 5, @ modelcontextprotocol/sdk, OpenAI API (text-embedding-3-small), Supabase PostgreSQL, pgvector, IVFFlat indexes, Zod validation, Vitest, Docker Compose.
The Results
- 8 MCP tools shipped and end-to-end tested over HTTP
- 125 unit tests with Supabase and OpenAI clients fully mocked
- ~2,600 lines of TypeScript across 16 source files, 11 commits over 11 days
- 2 tables, 3 RPC functions with SQL-level filtering before LIMIT for correctness
- Production-running as an always-on Docker service, used daily with real Claude Code sessions
- Published open-source on GitHub with full setup documentation, Docker Compose, and troubleshooting guide covering 4 documented failure modes
Key Engineering Decisions
1. Empirical similarity thresholds. text-embedding-3-small produces lower cosine scores than docs suggest (near-identical text scores 0.78–0.84). I lowered recall threshold to 0.25 and dedup to 0.75 based on real measurements, documented the rule for future features.
2. SQL-level date filtering. The since_days filter originally ran client-side after LIMIT, which silently missed recent memories ranked below the top N. Moving it into the WHERE clause before LIMIT guarantees correctness regardless of data volume.
3. Tool descriptions as executable instructions. Tool descriptions were rewritten from "what they do" to "when to call them" (e.g., "Call before starting non-trivial work"), so tools work correctly without requiring a maintained CLAUDE.md.
4. OAuth workaround for native Claude Code binary. The binary blocks HTTP MCP connections until OAuth discovery completes. Adding a static Bearer token to the MCP config skips discovery entirely (the token is arbitrary and never validated server-side).
Available On GitHub
Full source, setup instructions, and architecture docs published for developers who want to replicate or extend the system.
Claude Code is a powerful AI coding assistant, but it is stateless by design. Every new session starts without knowledge of past decisions, bugs, or architecture. In real production work, this leads to constant repetition, lost context, and slower development.
The Problem
The fundamental issue: the AI assistant helping build a project has no memory of building it. I was rediscovering the same bugs, re-explaining the same architecture, and losing decisions made last week. A secondary problem: recurring patterns across projects (like "we have set up Supabase this exact way 4 times") stayed buried in session memories instead of becoming reusable, documented skills.
The Solution
I built memory-mcp, an open-source MCP server that gives Claude Code long-term semantic memory. It exposes 8 tools: 4 core memory tools (remember, recall, forget, project_status) and 4 skill-pattern tools that track recurring work patterns and surface candidates for formalization once seen 3+ times.
Memories store as 1536-dimension vector embeddings (OpenAI text-embedding-3-small) in Supabase PostgreSQL with pgvector. Retrieval runs a cosine-similarity search via a Postgres RPC function with SQL-level filtering (threshold, project, type, date, expiration) in a single round trip. Recall responses are token-capped at ~2000 tokens to protect Claude's context window.
The server runs as a stateless Docker container on port 3101 via Express + Streamable HTTP transport, so multiple Claude Code sessions share one always-on instance. A stdio transport mode is also available for direct native-binary integration. Memories never hard-delete: forget is a soft-delete via expires_at, and every query filters on active-memory status.
Tech Stack: Node.js 20, TypeScript 5 (strict), Express 5, @ modelcontextprotocol/sdk, OpenAI API (text-embedding-3-small), Supabase PostgreSQL, pgvector, IVFFlat indexes, Zod validation, Vitest, Docker Compose.
The Results
- 8 MCP tools shipped and end-to-end tested over HTTP
- 125 unit tests with Supabase and OpenAI clients fully mocked
- ~2,600 lines of TypeScript across 16 source files, 11 commits over 11 days
- 2 tables, 3 RPC functions with SQL-level filtering before LIMIT for correctness
- Production-running as an always-on Docker service, used daily with real Claude Code sessions
- Published open-source on GitHub with full setup documentation, Docker Compose, and troubleshooting guide covering 4 documented failure modes
Key Engineering Decisions
1. Empirical similarity thresholds. text-embedding-3-small produces lower cosine scores than docs suggest (near-identical text scores 0.78–0.84). I lowered recall threshold to 0.25 and dedup to 0.75 based on real measurements, documented the rule for future features.
2. SQL-level date filtering. The since_days filter originally ran client-side after LIMIT, which silently missed recent memories ranked below the top N. Moving it into the WHERE clause before LIMIT guarantees correctness regardless of data volume.
3. Tool descriptions as executable instructions. Tool descriptions were rewritten from "what they do" to "when to call them" (e.g., "Call before starting non-trivial work"), so tools work correctly without requiring a maintained CLAUDE.md.
4. OAuth workaround for native Claude Code binary. The binary blocks HTTP MCP connections until OAuth discovery completes. Adding a static Bearer token to the MCP config skips discovery entirely (the token is arbitrary and never validated server-side).
Available On GitHub
Full source, setup instructions, and architecture docs published for developers who want to replicate or extend the system.