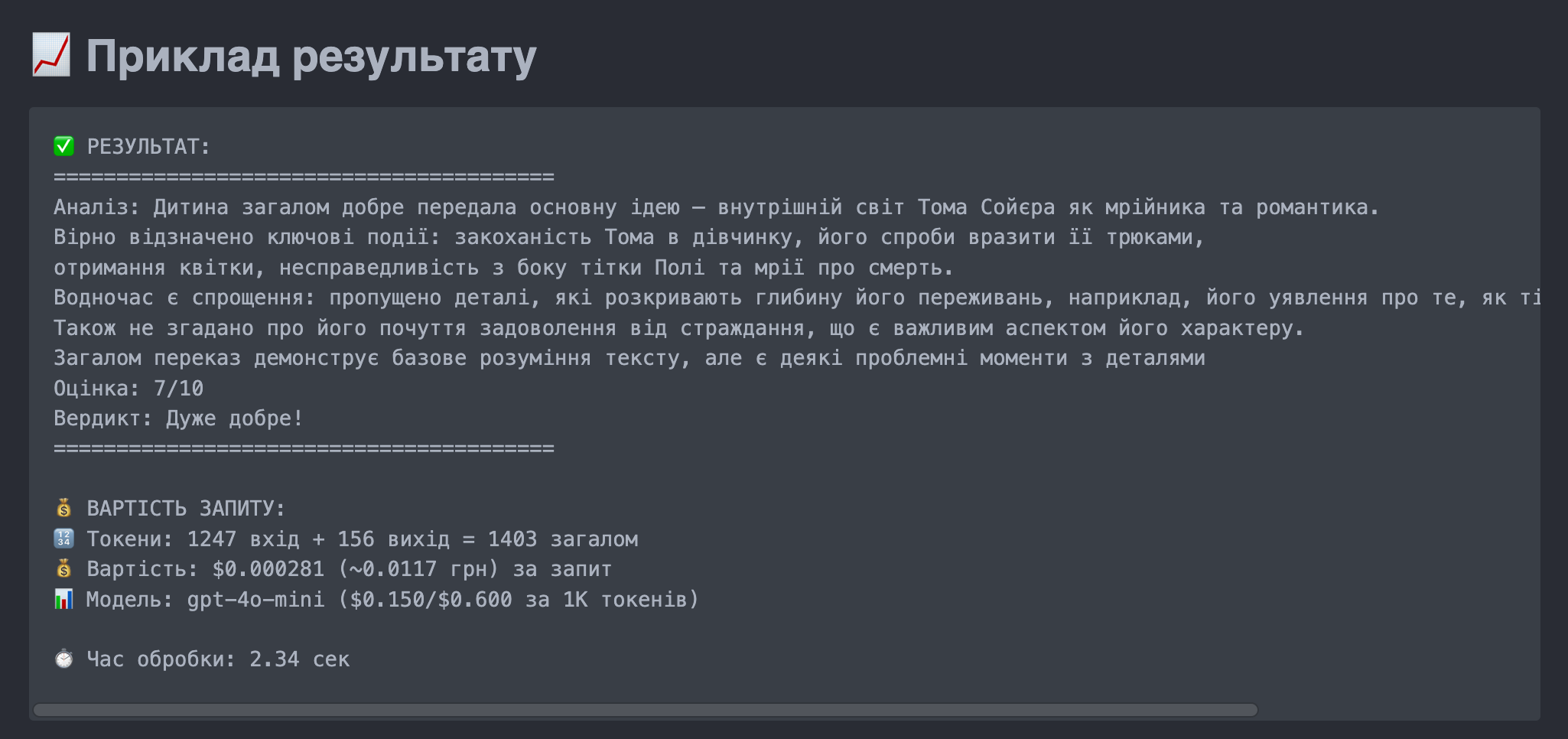
Prompt engineering for a project to evaluate children's retellings of literary works from school and preschool children for the OpenAI GPT 4o mini model.
The main goal is a consistent assessment of a child's retelling (to avoid offending) on a 10-point scale over 100 checks with no more than 1% deviation. Each check consists of 10 prompts, from which an average score is selected. That is, for 100 * 10 = 1000 prompts, the results show 100% consistency in scoring.
Evaluation criteria:
Characters - understanding of main characters and their roles
Plot - conveying key events in the correct sequence
Conflict - understanding the problem and its resolution
Main idea - capturing the central theme/moral
Clarity - logicality and coherence of the retelling
Display scale (1-10):
10-9: "Well done!", "Great job!"
8-7: "Good!", "Nice work!"
6-5: "Not bad, but could be better"
4-3: "Try harder", "You can do better"
2-1: "Try again", "Re-read the text"
#openai #openai-api #Chatgpt #prompt #ai
The main goal is a consistent assessment of a child's retelling (to avoid offending) on a 10-point scale over 100 checks with no more than 1% deviation. Each check consists of 10 prompts, from which an average score is selected. That is, for 100 * 10 = 1000 prompts, the results show 100% consistency in scoring.
Evaluation criteria:
Characters - understanding of main characters and their roles
Plot - conveying key events in the correct sequence
Conflict - understanding the problem and its resolution
Main idea - capturing the central theme/moral
Clarity - logicality and coherence of the retelling
Display scale (1-10):
10-9: "Well done!", "Great job!"
8-7: "Good!", "Nice work!"
6-5: "Not bad, but could be better"
4-3: "Try harder", "You can do better"
2-1: "Try again", "Re-read the text"
#openai #openai-api #Chatgpt #prompt #ai