Recommendation systems for restaurants
AI & Machine Learning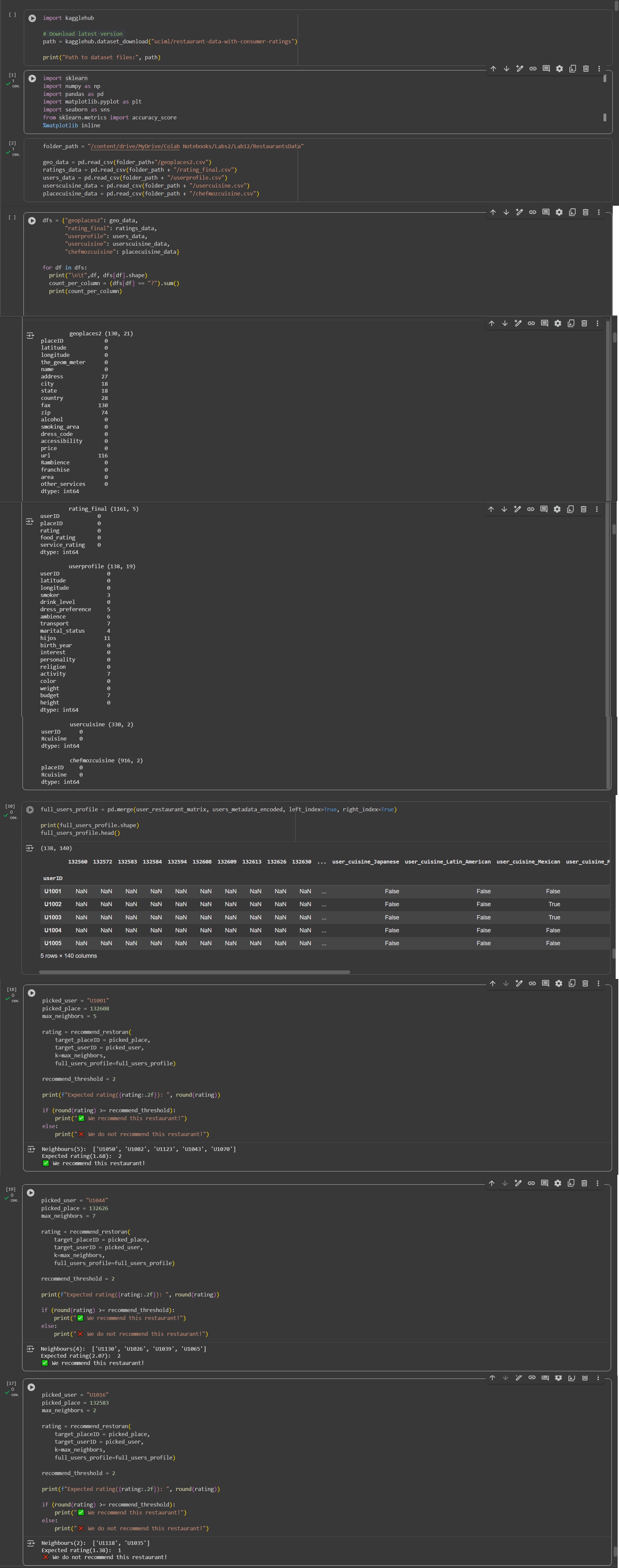
The work is focused on developing a recommendation system for dining establishments (restaurants) for individual users. The main focus of the project was on preprocessing a complex, multi-table dataset and building a model capable of predicting whether a particular user would like a specific restaurant.
The goal was to create a prediction function (recommendation) of a restaurant rating for a user based on user profile data and their previous ratings. In other words, performing a User-based collaborative filtering task using KNN.
Steps performed:
• Loading and merging data from five different sources.
• Detecting and handling missing and inconsistent values in the data.
• Cleaning and normalizing geographic and meta-data of users and restaurants.
• Building the recommendation system model.
Data used
The project uses the dataset restaurant-data-with-consumer-ratings, which consists of 9 tables, out of which five interrelated CSV files were used:
1. geoplaces2.csv: Geographic characteristics and attributes of establishments (e.g., price range, alcohol, dress code, etc.).
2. rating_final.csv: Final user ratings of establishments (overall rating, food rating, service rating).
3. userprofile.csv: Demographic and behavioral profiles of users (e.g., alcohol consumption, nicotine usage, budget, etc.).
4. usercuisine.csv: User cuisine preferences.
5. chefmozcuisine.csv: Types of cuisine offered by establishments.
Modeling
• Applied the concept of User-Based Collaborative Filtering (UBCF), where KNN was used to find the K-nearest neighbors based on cosine similarity metrics.
• Optimization: Addressed scalability issues of classical UBCF using optimized methods; confirmed the need to switch to Weighted Average for accurate rating prediction based on neighbor distances and indices.
• Recommendation function: Developed the function recommend_restoran(), which takes a target establishment (target_placeID), a target user (target_userID), and the number of neighbors (k) to predict the rating.
• Recommendation criterion: The predicted rating is rounded, and if it equals or exceeds a threshold value (recommend_threshold), the restaurant is recommended.
Technologies used
Programming language: Python
Libraries:
• pandas, numpy: Data processing and manipulation.
• requests: For calling an external geo-service (GPS-Coordinates.net).
• sklearn (Scikit-learn): For similarity metrics.
P.S. The screenshot shows the number of missing values in the tables I worked with, the final calculation matrix, and 3 results of the function’s execution.
#ML #machinelearning #datascience #database #analytics #dataanalysis
The goal was to create a prediction function (recommendation) of a restaurant rating for a user based on user profile data and their previous ratings. In other words, performing a User-based collaborative filtering task using KNN.
Steps performed:
• Loading and merging data from five different sources.
• Detecting and handling missing and inconsistent values in the data.
• Cleaning and normalizing geographic and meta-data of users and restaurants.
• Building the recommendation system model.
Data used
The project uses the dataset restaurant-data-with-consumer-ratings, which consists of 9 tables, out of which five interrelated CSV files were used:
1. geoplaces2.csv: Geographic characteristics and attributes of establishments (e.g., price range, alcohol, dress code, etc.).
2. rating_final.csv: Final user ratings of establishments (overall rating, food rating, service rating).
3. userprofile.csv: Demographic and behavioral profiles of users (e.g., alcohol consumption, nicotine usage, budget, etc.).
4. usercuisine.csv: User cuisine preferences.
5. chefmozcuisine.csv: Types of cuisine offered by establishments.
Modeling
• Applied the concept of User-Based Collaborative Filtering (UBCF), where KNN was used to find the K-nearest neighbors based on cosine similarity metrics.
• Optimization: Addressed scalability issues of classical UBCF using optimized methods; confirmed the need to switch to Weighted Average for accurate rating prediction based on neighbor distances and indices.
• Recommendation function: Developed the function recommend_restoran(), which takes a target establishment (target_placeID), a target user (target_userID), and the number of neighbors (k) to predict the rating.
• Recommendation criterion: The predicted rating is rounded, and if it equals or exceeds a threshold value (recommend_threshold), the restaurant is recommended.
Technologies used
Programming language: Python
Libraries:
• pandas, numpy: Data processing and manipulation.
• requests: For calling an external geo-service (GPS-Coordinates.net).
• sklearn (Scikit-learn): For similarity metrics.
P.S. The screenshot shows the number of missing values in the tables I worked with, the final calculation matrix, and 3 results of the function’s execution.
#ML #machinelearning #datascience #database #analytics #dataanalysis