Task: Automate the collection of "hot" leads (business owners who have been sued) for law firms in the USA by extracting data from complex government websites and scanned documents.
Solution: An automated parser has been written that bypasses the basic protections of the court website (NYSCEF), finds the necessary cases, downloads PDF documents (complaints), and extracts the names of business owners and their addresses through text analysis.
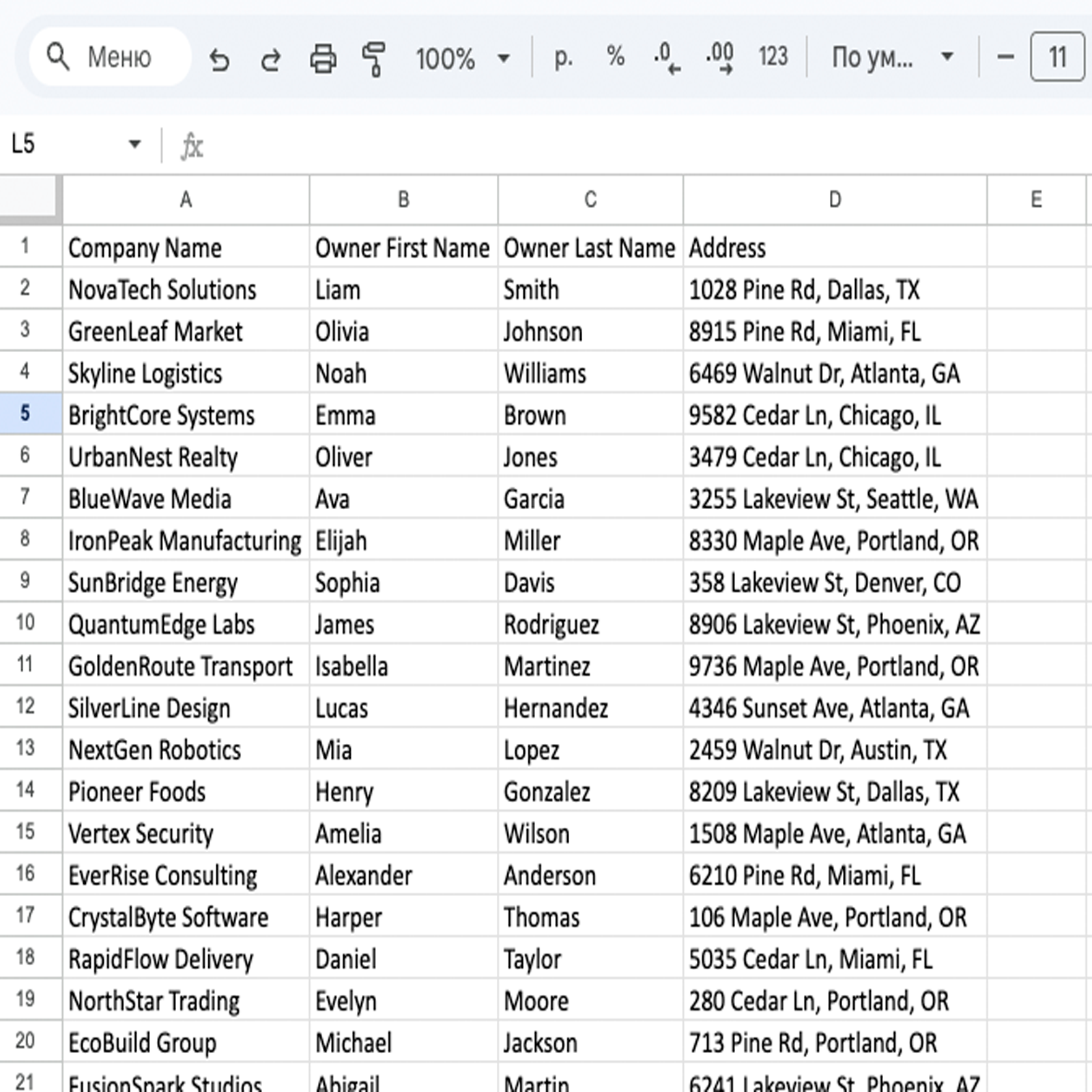
Result: Automated the generation of Excel/CSV tables with ready contacts for the sales department, replacing weeks of manual searching.
Technology stack: Python, Playwright (for bypassing blocks and navigation), PyMuPDF / pdfplumber (for reading PDFs), Pandas (for exporting to tables).
Solution: An automated parser has been written that bypasses the basic protections of the court website (NYSCEF), finds the necessary cases, downloads PDF documents (complaints), and extracts the names of business owners and their addresses through text analysis.
Result: Automated the generation of Excel/CSV tables with ready contacts for the sales department, replacing weeks of manual searching.
Technology stack: Python, Playwright (for bypassing blocks and navigation), PyMuPDF / pdfplumber (for reading PDFs), Pandas (for exporting to tables).