Python/Selenium parser danych z avto.pro
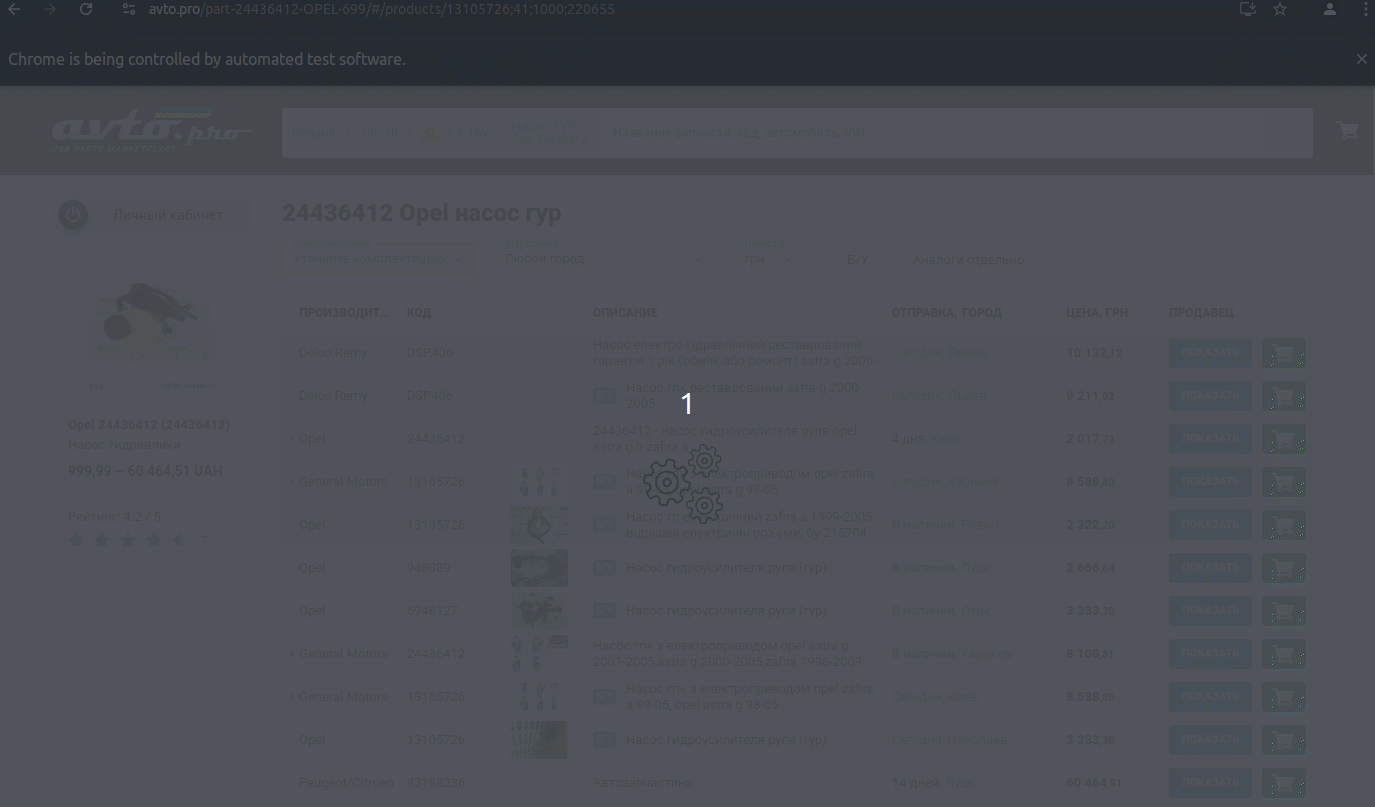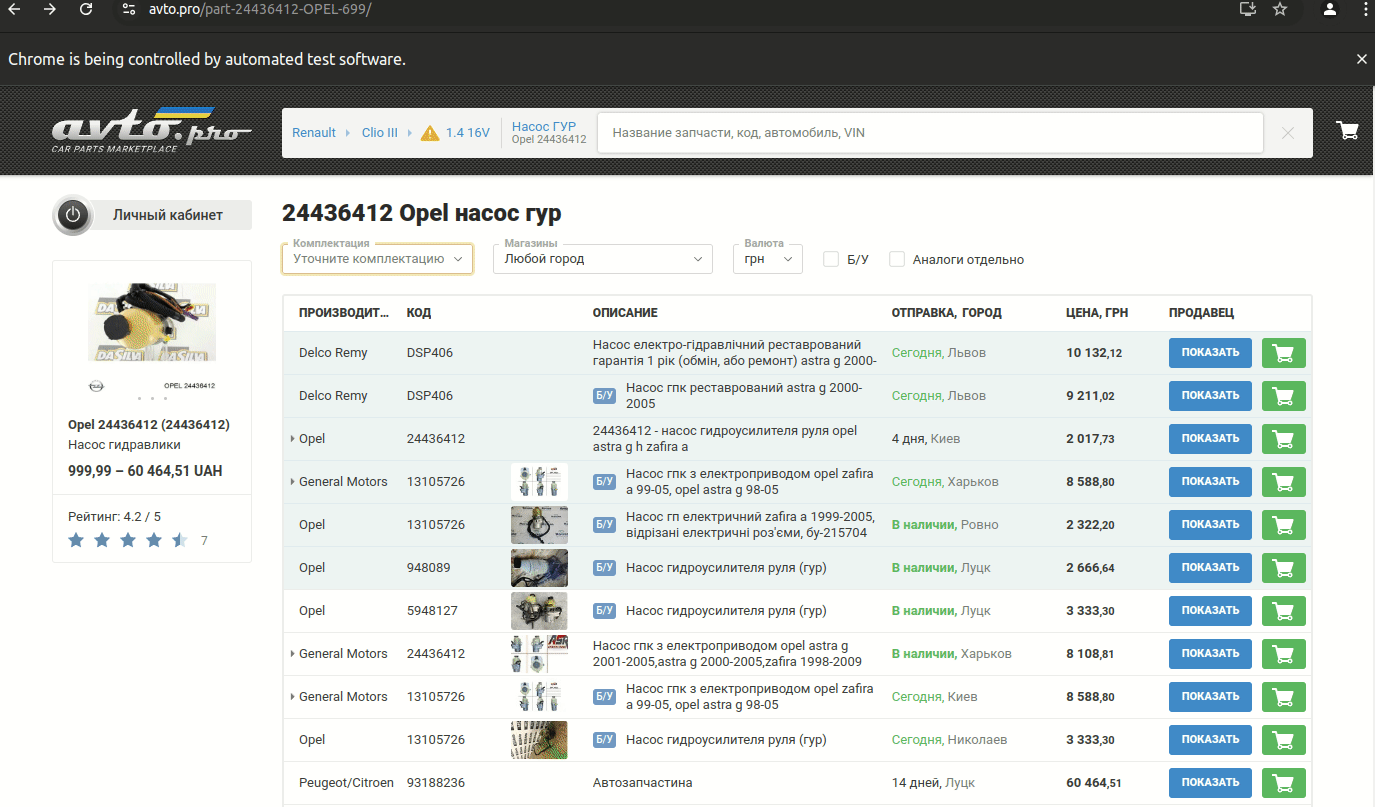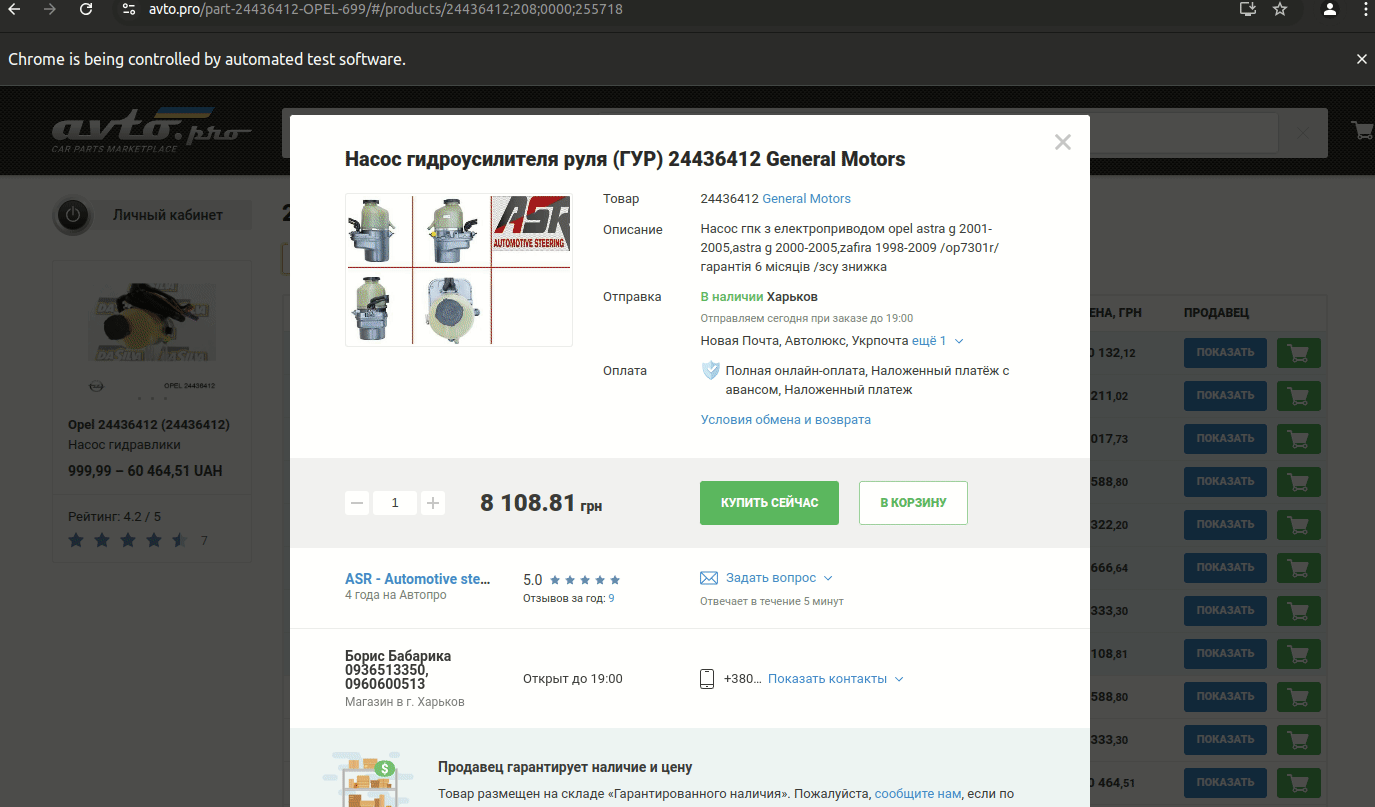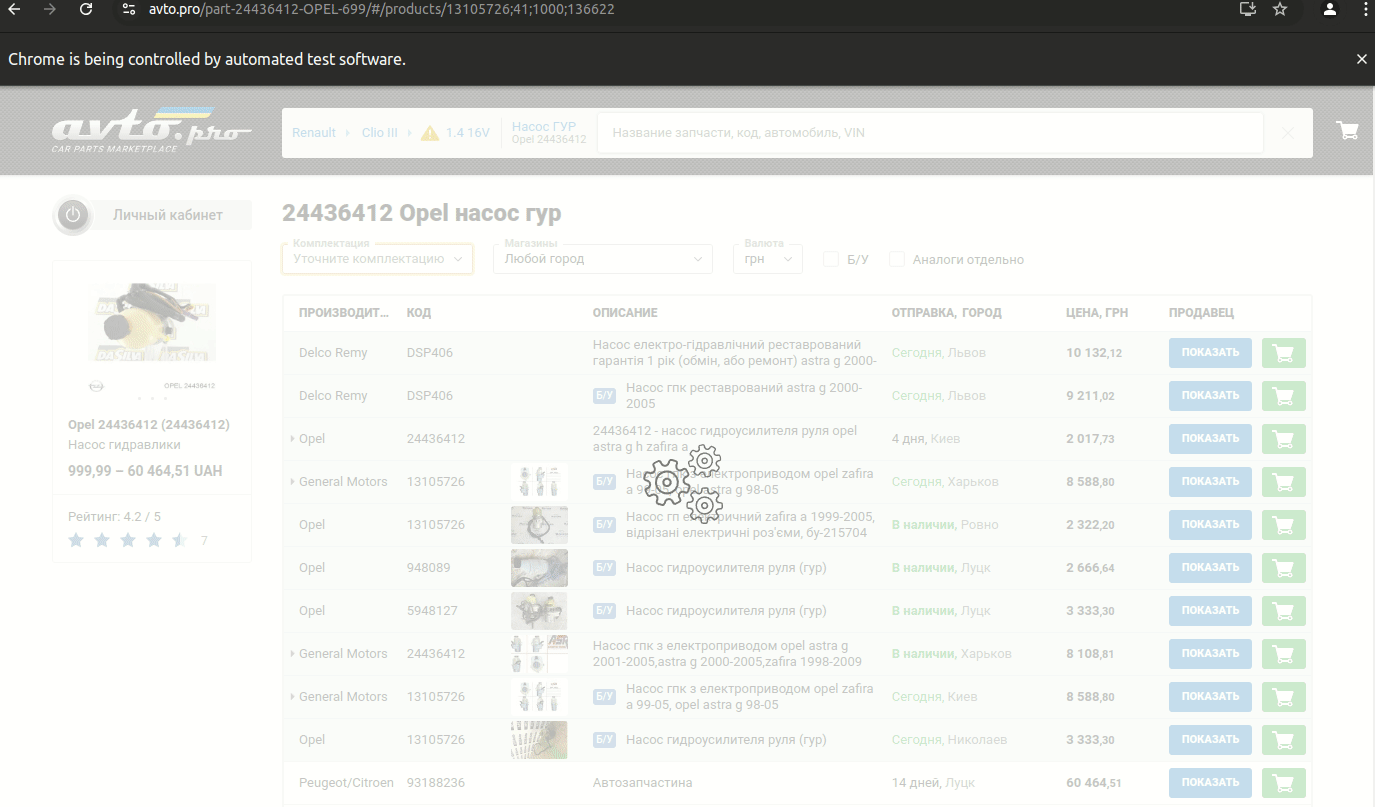
Zadanie polegało na wyciągnięciu z witryny avto.pro danych sprzedawców, ich sklepów i warsztatów samochodowych.
Ponieważ większość potrzebnej treści ładowana jest na stronach dynamicznie, wykonałem to za pomocą #selenium. Główną trudnością w tym projekcie było znalezienie URL stron sprzedawców, ponieważ nie ma określonej listy ani strony, na której można je znaleźć.
Witryna została zaprojektowana w taki sposób (możliwe, że celowo), że aby przejść do strony sprzedawcy, trzeba przejść ścieżkę od wyboru samochodu lub części do wybrania konkretnej części. I dopiero wtedy, klikając na nią, widzimy tylko jej sprzedawcę.
Dlatego mój parser kliknie wszystkie części na wszystkich stronach (a jest ich ponad milion) i wyciągnie potrzebne informacje.
Wynik parsowania jest przechowywany w bazie danych #sqlite i eksportowany do pliku #Exell #xlsx
Ponieważ większość potrzebnej treści ładowana jest na stronach dynamicznie, wykonałem to za pomocą #selenium. Główną trudnością w tym projekcie było znalezienie URL stron sprzedawców, ponieważ nie ma określonej listy ani strony, na której można je znaleźć.
Witryna została zaprojektowana w taki sposób (możliwe, że celowo), że aby przejść do strony sprzedawcy, trzeba przejść ścieżkę od wyboru samochodu lub części do wybrania konkretnej części. I dopiero wtedy, klikając na nią, widzimy tylko jej sprzedawcę.
Dlatego mój parser kliknie wszystkie części na wszystkich stronach (a jest ich ponad milion) i wyciągnie potrzebne informacje.
Wynik parsowania jest przechowywany w bazie danych #sqlite i eksportowany do pliku #Exell #xlsx
 Lwów
Lwów