Python текстовий токен
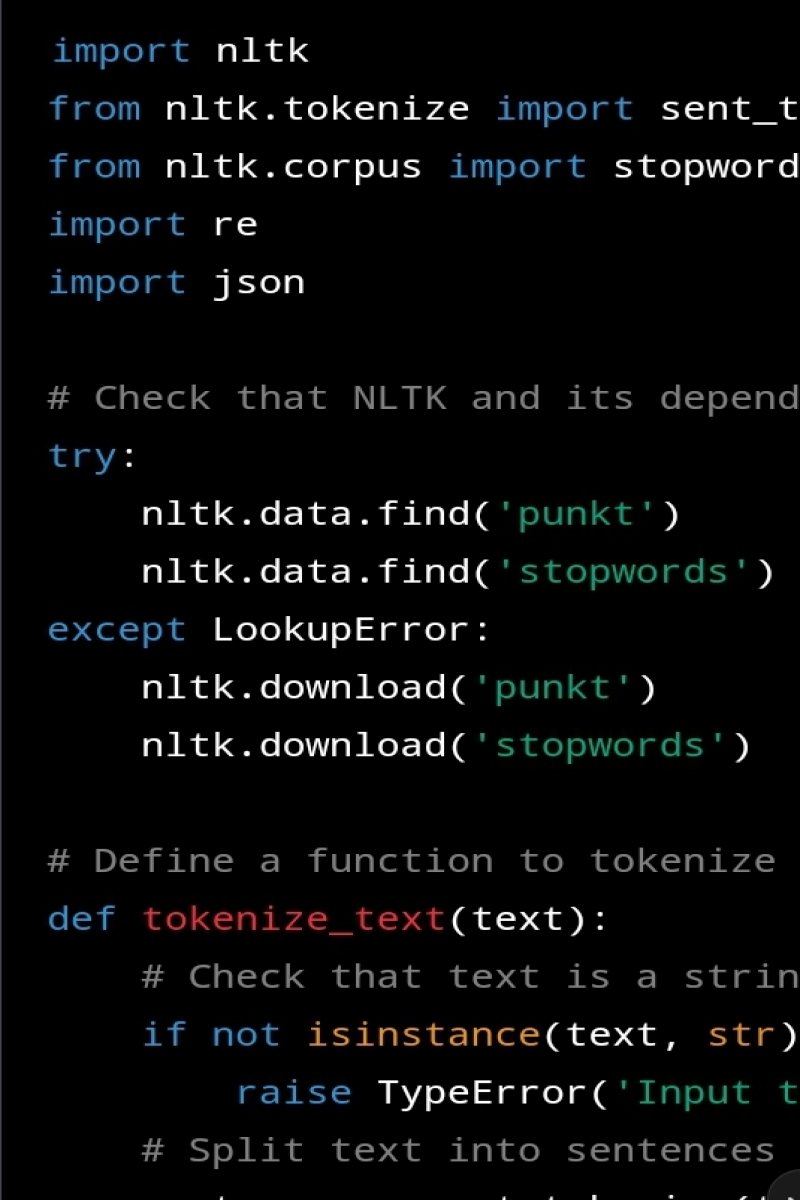
Ось перегляд того, що робить Цей Код:
Імпортує Необхідні Бібліотеки: Nltk Для Обробки Природних Мов, ре Для Регулярних Виразів Та Json Для Роботи З Об'Ектами Json.Перевіряє, Що Ненеобхідні Дани Нltк Завантажені.Якщо ні, то вони завантажуються.Визначає Функцію Tokenize_Text (текст), Яка Приймає Рядок текст Як Вхідні Дани Та Повертає Об'Ект Джсон, Що Містить Кожне Слово В Тексті Та Речення, У Яких Воно Зустрічається.Функція Tokenize_Text (текст) Спочатку Розбиває Текст На Окремі Речення За Допомогою Sent_Tokenize (текст) З Модуля Nltk.Tokenize.
Потім Она Створює Порожній Словник Word_Dict Для Збереження Слів Та Їх Речень.Для Кожного Речення В Тексти Функція Токенізує Речення На Окремі Слова За Допомогою Word_Tokenize (свенція) З Модуля Nltk.Tokenize.
Функція Потім Фільтрує Будь-Які Зупинні Слова (Звичайні Слова, Такі Як "те" Та "і", Які Зазвичай Не Є Корисні Для Аналізу) Та Небажані Слова (Такі Як Знаки Пунктуації Та Числа) За Допомогою Спискового Включення, Яке Перебирає Слова Та Перевіряє, Що Кожне Слово Не Міститься В Множині Англійських Зупинних Слова (Stopwords.Words ('English')) Та Що Воно Не Складається Виключно З Символів, Які Не Є Словами (За Допомогою ReMatch ('^ [W_] + $', слово)).Функція Потім Перебирає Відфільтровані Слова Та Додає Кожне Слово Та Індекс Речення, У Якому Воно Зустрічається, До Word_Dict.Якщо Слово Вже Є У Словнику, Функція Додає Індекс Речення До Списку Речень, У Яких Зустрічається Слово.Нарешті, Word_Dict Перетворюється На Об'Ект Json За Допомогою Json.Dumps (Word_Dict)
Імпортує Необхідні Бібліотеки: Nltk Для Обробки Природних Мов, ре Для Регулярних Виразів Та Json Для Роботи З Об'Ектами Json.Перевіряє, Що Ненеобхідні Дани Нltк Завантажені.Якщо ні, то вони завантажуються.Визначає Функцію Tokenize_Text (текст), Яка Приймає Рядок текст Як Вхідні Дани Та Повертає Об'Ект Джсон, Що Містить Кожне Слово В Тексті Та Речення, У Яких Воно Зустрічається.Функція Tokenize_Text (текст) Спочатку Розбиває Текст На Окремі Речення За Допомогою Sent_Tokenize (текст) З Модуля Nltk.Tokenize.
Потім Она Створює Порожній Словник Word_Dict Для Збереження Слів Та Їх Речень.Для Кожного Речення В Тексти Функція Токенізує Речення На Окремі Слова За Допомогою Word_Tokenize (свенція) З Модуля Nltk.Tokenize.
Функція Потім Фільтрує Будь-Які Зупинні Слова (Звичайні Слова, Такі Як "те" Та "і", Які Зазвичай Не Є Корисні Для Аналізу) Та Небажані Слова (Такі Як Знаки Пунктуації Та Числа) За Допомогою Спискового Включення, Яке Перебирає Слова Та Перевіряє, Що Кожне Слово Не Міститься В Множині Англійських Зупинних Слова (Stopwords.Words ('English')) Та Що Воно Не Складається Виключно З Символів, Які Не Є Словами (За Допомогою ReMatch ('^ [W_] + $', слово)).Функція Потім Перебирає Відфільтровані Слова Та Додає Кожне Слово Та Індекс Речення, У Якому Воно Зустрічається, До Word_Dict.Якщо Слово Вже Є У Словнику, Функція Додає Індекс Речення До Списку Речень, У Яких Зустрічається Слово.Нарешті, Word_Dict Перетворюється На Об'Ект Json За Допомогою Json.Dumps (Word_Dict)
 Київ
Київ